ShadowBroker - Une salle de crise OSINT mondiale chez vous
Les avions en vol, les cargos, les satellites espions, les zones de brouillage GPS... Imaginez tout ce bordel, à l'échelle de la planète, visible sur une seule carte sombre directement chez vous. Ce serait fou non ? Hé bien c'est ce que nous propose BigBodyCobain qui a sorti ShadowBroker , un tableau de bord OSINT gratuit et open source qui agrège plus de 60 flux de renseignement public, rafraîchis en continu.
Pour l'installer, un git clone, et on entre dans le dossier. Suffit ensuite de lancer un docker compose up (faut juste Docker, et ça tourne sous Linux, Mac ou Windows), vous ouvrez localhost:3000 et la carte se remplit toute seule ! Ça marche même sur un Raspberry Pi 5. C'est donc largement plus simple que la moitié des trucs que je vous présente ici en général.
Y'a qu'une seule clé API qui est vraiment obligatoire, c'est celle d'aisstream.io pour le trafic des bateaux, et c'est une inscription gratuite. Le reste tourne sans rien, sauf qu'une clé OpenSky (gratuite aussi) est chaudement recommandée pour une couverture aérienne correcte, + quelques couches secondaires qui acceptent leur propre clé pour avoir de la meilleure info.
L'interface principale de ShadowBroker : une carte du globe qui empile en temps réel avions, navires et satellites, chat MESH à gauche et fil Global Threat Intercept à droite
Pour ceux qui débarquent, l'OSINT c'est le renseignement à partir de sources ouvertes, c'est à dire toutes ces données déjà publiques que personne ne prend le temps d'aller croiser. Donc cet agrégateur ne pirate rien... il ramasse juste ce qui traîne déjà en accès libre.
Et là, vous vous demandez ce qu'il y a dedans en détails ?
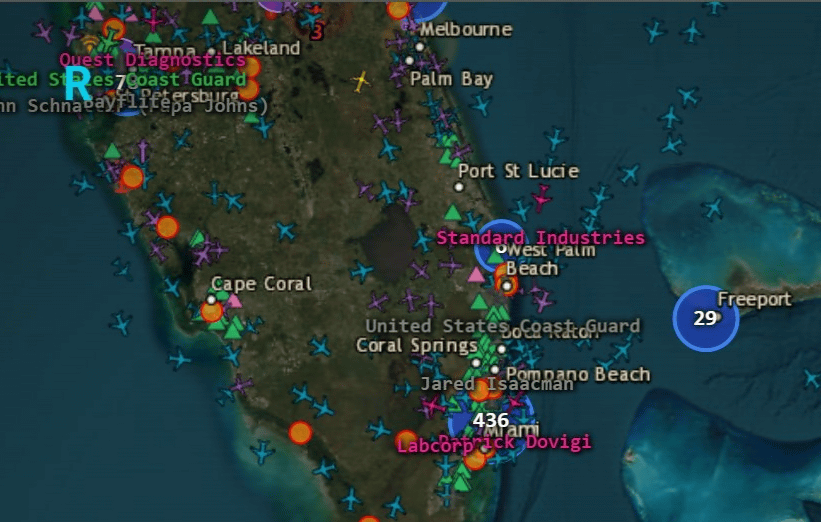
Hé bien accrochez-vous parce qu'on y retrouve les avions civils via OpenSky, les militaires via adsb.lol, l'ADS-B étant le signal que tout avion crache en vol, avec Air Force One bien visible dès le décollage. Et les bateaux sont suivis en AIS, l'équivalent radio côté maritime.
Y'a aussi les satellites dont la trajectoire est calculée depuis leurs paramètres orbitaux, les séismes de l'USGS, les feux repérés par la NASA, les conflits agrégés depuis GDELT, la ligne de front ukrainienne via DeepState et même un tracker pour suivre les porte-avions américains (c'est une position estimée à partir de l'actu publique, et pas du temps réel).
Du coup ça va loin ! Les zones de brouillage GPS probable sont même déduites quand le signal de navigation des avions se dégrade et on y retrouve aussi plus de 11 000 caméras de circulation aussi, de Londres à Singapour en passant par les États-Unis et l'Espagne.
Le panneau Data Layers (séismes, satellites, brouillage GPS, lignes de front) ouvert sur une zone de conflit, avec le détail des reports terrain
Il y a même un tuner d'ondes courtes intégré, branché sur des centaines de récepteurs radio partagés par des amateurs (les SDR, des radios pilotées par logiciel). Et les scanners de la police américaine sont aussi en écoute directe.
Et en faisant un clic droit n'importe où sur le globe, ce radar mondial vous sortira un dossier du pays, avec le type de gouvernement, le chef d'État tiré de Wikidata, un résumé Wikipédia et la dernière image satellite Sentinel-2 disponible.
Côté bidouille, vous pouvez aussi brancher votre propre dongle RTL-SDR, une clé radio à pas cher, en plus du flux distant pour choper les bateaux à portée de votre antenne. Et avec une clé Shodan, un overlay optionnel ajoute les objets connectés visibles depuis Internet, tels que les caméras, les systèmes industriels, les bases de données et j'en passe.
Ça rejoint ce bon vieux moteur de recherche d'objets connectés dont je vous parlais il y a quelques années. Et si l'OSINT vous gratte vraiment, y'a aussi de quoi vous entraîner sérieusement avec ce site aussi.
La légende de cet outil veut que l'idée soit partie d'une envie de pister les déplacements d'Elon Musk avec une interface cyberpunk. Le nom, lui, vient du Shadow Broker de Mass Effect (rien à voir avec le groupe de hacker Shadow Brokers ). D'après le créateur, GitHub aurait même fait retirer le dépôt d'origine à cause de ce nom, d'où un petit détour par GitLab avant de revenir à Github.
Bref, ce truc agrège une quantité hallucinante de données publiques mondiales...
Après, au niveau du code, tout n'est pas non plus très clair car même si l'OSINT c'est légal, le code du scrapeur d'une carte de guerre contourne volontairement la protection Cloudflare Turnstile, ce qui pose une vraie question légale côté CFAA, la loi américaine contre l'intrusion informatique. C'est une zone grise...
Et y'a aussi des failles puisque plusieurs endpoints ne sont pas authentifiés, dont un qui laisse n'importe qui envoyer des messages APRS (le réseau de positionnement des radioamateurs) sous n'importe quel indicatif, ce qui est une infraction pure et simple aux règles radio.
Quant à la messagerie soi-disant chiffrée ne l'est pas de bout en bout, mais juste obfusquée donc ne faites rien transiter de sensible dessus.
Voilà si je vous dis tout ça, c'est pour que vous gardiez cet outil bien au chaud en local et que vous ne l'exposiez pas sur le net.
Zoom sur la côte de Floride : chaque marqueur est un avion suivi en direct via l'ADS-B, façon radar ( Source : GIGAZINE )
{kind=link}
Mais bon, ça fait une belle salle de crise gratuite, open source sous licence AGPL, installable par exemple sur un Raspberry Pi. Grâce à ça, le monde n'a jamais été aussi "lisible" depuis votre canapé !
Un grand merci François pour le lien !
![]()