Git est un système de contrôle de version distribué, conçu pour suivre les modifications dans les fichiers et coordonner le travail sur ces fichiers entre plusieurs personnes
git clone est une commande Git utilisée pour créer une copie d’un dépôt distant sur votre machine locale. Elle télécharge essentiellement l’ensemble du dépôt, y compris tous ses fichiers, ses branches et l’historique des livraisons. Vous pouvez en avoir besoin pour récupérer un dépôt public sur GitHub ou si vous êtes un développeur pour obtenir une copie d’un projet.
Dans ce tutoriel, je vous explique comment utiliser la commande git clone.
Comment cloner un dépôt git
Voici la syntaxe générale de la commande git clone :
git clone <repository_URL>
Par exemple, si vous voulez cloner un dépôt hébergé sur GitHub, vous utiliserez :
git clone git://github.com/<nom dépôt>.git
Cette commande créera un nouveau répertoire sur votre machine locale avec le même nom que le dépôt et téléchargera tout son contenu dans ce répertoire.
Si vous souhaitez spécifier un nom de répertoire différent, vous pouvez le faire en l’ajoutant comme argument supplémentaire après l’URL du dépôt :
git clone <dépôt_URL> <nom_repertoire>
Comment cloner un dépôt, y compris ses sous-modules (récursif)
Un submodule (sous-module) est un référentiel Git intégré à un autre référentiel Git plus large. Lorsque vous clônez un référentiel qui contient des sous-modules, ces sous-modules sont initialement configurés pour pointer vers une version spécifique (commit) dans leur référentiel d’origine.
Si vous souhaitez cloner un dépôt git tout en clonant également ses sous-modules, vous devez ajouter l’option –recurse-submodules :
Si vous souhaitez cloner et mettre à jour les sous-modules à leur dernière révision, ajoutez la commande –remote-submodules. Celle-ci va mettre à jour les sous-modules d’un référentiel pour pointer vers les dernières révisions disponibles dans leurs référentiels distants. Cela signifie qu’au lieu de pointer vers une révision spécifique (commit) dans le même référentiel parent, les sous-modules pointeront vers les révisions les plus récentes de leur référentiel distant.
Pour cloner une branche spécifique avec Git, vous pouvez utiliser la commande git clone suivie de l’URL du référentiel, puis vous pouvez spécifier la branche que vous souhaitez cloner en utilisant l’option -b ou –branch suivi du nom de la branche.
Voici la syntaxe générale :
git clone -b <URL_du_référentiel>
Par exemple, si vous souhaitez cloner la branche develop d’un référentiel, vous pouvez utiliser la commande suivante :
Cela va cloner le référentiel et basculer automatiquement sur la branche develop après le clonage. Si vous ne spécifiez pas la branche à cloner, Git clonera automatiquement la branche par défaut, souvent master ou main , selon la configuration du référentiel.
Si vous avez déjà cloné le référentiel et que vous souhaitez basculer vers une branche spécifique après le clonage, vous pouvez utiliser la commande git checkout après avoir cloné le référentiel :
git clone https://github.com/utilisateur/nom_du_repos.git cd nom_du_repos git checkout
Cela va cloner le référentiel et basculer sur la branche spécifiée après le clonage.
Comment cloner un dépôt à distant par SSH
Vous pouvez aussi cloner un dépôt distant disponible par SSH. Voici la syntaxe générale :
Lorsque vous git clone, git fetch, git pull ou git push vers un référentiel distant à l’aide d’URL SSH, vous êtes invité à entrer un mot de passe et vous devez fournir la phrase secrète de votre clé SSH. Pour plus d’informations, consultez « Utilisation des phrases secrètes de clé SSH ».
Pour utiliser Windows dans Linux, vous avez la solution VirtualBox. Mais grâce à Dockurr, nouveau projet open source, vous pouvez exécuter Windows à l’intérieur d’un conteneur Docker sans avoir à franchir de nombreuses étapes. De plus, le conteneur fournit une connexion VNC et RDP notamment accessible par un simple navigateur internet. Enfin les performances sont bonnes grâce à l’accélération KVM (Kernel Virtual Machine).
Dans ce tutoriel, je vous guide pour exécuter Windows, Tiny11, Tiny10 dans un conteneur Linux (Docker) avec Dockurr.
Qu’est-ce que Dockurr?
Dockurr est un projet libre et gratuit qui permet d’exécuter des installations de bureau Windows client et Windows Server dans un environnement de conteneur Docker. Il vous permet également de le faire sur un hôte Docker Linux qui ne pourrait normalement exécuter que des conteneurs Linux. En utilisant l’accélération KVM, il vous permet d’exécuter des conteneurs Windows sur un hôte de conteneur Linux sans avoir besoin d’installer et de démarrer Docker Desktop ou d’autres problèmes de compatibilité qui sont typiques avec le mélange de systèmes d’exploitation entre Linux et Windows.
Il fournit également une connexion VNC au conteneur pendant le processus d’installation. Il vous permet également de vous connecter via le protocole de bureau à distance (RDP) à l’installation Windows exécutée dans Docker.
Quelles sont les configurations de distribution Windows prises en charge ?
Windows 11 Pro
Windows 10 Pro
Windows 10 LTSC
Windows 8.1 Pro
Windows 7 SP1
Windows Vista SP2
Windows XP SP3
Windows Server 2022
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2008 R2
Tiny 11 Core
Tiny 11
Tiny 10
Installer la machine virtuelle à noyau (KVM)
Dans un premier temps, Docker doit être installé sur votre appareil en Linux. Si ce n’est pas le cas, vous pouvez consulter ce guide : Comment installer Docker sur Linux Ensuite, vous devez installer KVM (Kernel Virtual Machine) et qemu :
Exécutez la commande suivante à partir de la ligne de commande pour installer KVM. Assurez-vous d’être root ou de faire partie du groupe d’utilisateurs sudo :
Télécharger Dockurr dans un conteneur et lancer Windows dans un conteneur Docker
Après avoir installé KVM sur notre hôte Docker Linux, nous pouvons maintenant lancer le conteneur Docker appelé Dockurr, qui utilise l’isolation de KVM. Deux manières sont possibles, par docker run ou par docker compose.
La méthode docker run est la plus automatisé et rapide. Voici comment faire :
Dans mon cas, j’ai du passer la commande suivante pour autoriser les sockets Docker à être utilisé par les utilisateurs Linux
sudo chmod 666 /var/run/docker.sock
Vous pouvez utiliser la commande docker run à partir de l’interface de commande de docker pour exécuter le conteneur :
docker run -it --rm --name windows -p 8006:8006 --device=/dev/kvm --cap-add NET_ADMIN --stop-timeout 120 dockurr/windows
La méthode par docker compose vous permet de modifier le fichier de configuration si vous souhaitez installer une autre version de Windows ou modifier la configuration du réseau (voir fin de ce guide). Voici comment faire :
Cloner le dépôt Git :
git clone https://github.com/dockur/windows.git
Modifiez le fichier compose.yml si besoin (voir plus bas)
Puis exécutez le conteneur :
cd windows
docker-compose up -d
L’image de Windows se télécharge puis l’installation de l’OS s’effectue.
Après avoir utilisé les commandes ci-dessus pour installer la solution Dockurr, vous pouvez vous connecter au conteneur sur votre hôte de conteneur en vous connectant à votre hôte de conteneur dans un navigateur sur le port 8006 pour l’accès à l’interface utilisateur.
Lorsque vous démarrez la configuration de conteneur par défaut, elle tire une image Docker Windows 11. Notez l’exemple de configuration Docker compose ci-dessous :
Ensuite une phase d’extraction du fichier win11x64.esd
Puis l’image de Windows 11 est construire
Ensuite qemu exécute l’installeur de Windows 11, la copie de fichiers s’effectuent
Une fois l’installation terminée, l’utilisateur se connectera automatiquement en utilisant le nom d’utilisateur docker
Voila, Windows s’exécute dans un conteneur Docker.
Ici nous utilisons le navigateur internet pour se connecter via VNC, mais vous pouvez aussi prendre la main sur Windows par RDP, avec par exemple le bureau à distance. Le port utilisé est celui par défaut, à savoir le port 3389.
Exécuter différentes images du système d’exploitation Windows dans Docker
Comme mentionné en introduction, plusieurs versions de Windows sont supportés. Par défaut, c’est Windows 11 qui est installé, mais vous pouvez modifier la partie suivante du fichier compose.yml pour changer la version de Windows :
environment: VERSION: "win11"
Vous pouvez utiliser les désignateurs suivants dans la variable d’environnement pour indiquer la version de Windows que vous souhaitez lancer (win11, win10, ltsc10, win7, etc.) dans la liste d’informations ci-dessous :
Valeur
Description
Source
Transfert
Taille
win11
Windows 11 Pro
Microsoft
Rapide
6,4 Go
win10
Windows 10 Pro
Microsoft
Rapide
5,8 Go
ltsc10
Windows 10 LTSC
Microsoft
Rapide
4,6 Go
win81
Windows 8.1 Pro
Microsoft
Rapide
4,2 Go
win7
Windows 7 SP1
Bob Pony
Moyen
3,0 Go
vista
Windows Vista SP2
Bob Pony
Moyen
3,6 Go
winxp
Windows XP SP3
Bob Pony
Moyen
0,6 Go
2022
Windows Server 2022
Microsoft
Rapide
4,7 Go
2019
Windows Server 2019
Microsoft
Rapide
5,3 Go
2016
Windows Server 2016
Microsoft
Rapide
6,5 Go
2012
Windows Server 2012 R2
Microsoft
Rapide
4,3 Go
2008
Windows Server 2008 R2
Microsoft
Rapide
3,0 Go
core11
Tiny 11 Core
Archive.org
Lent
2,1 Go
tiny11
Tiny 11
Archive.org
Lent
3,8 Go
tiny10
Tiny 10
Archive.org
Lent
3,6 Go
Les versions de Windows supportées par Dockurr
Outre les versions de Windows que vous pouvez installer par défaut, vous pouvez également utiliser des images personnalisées pour vos supports Windows. Il suffit de définir l’emplacement web de l’ISO personnalisée de Windows comme suit :
Vous avez la possibilité de modifier la configuration de l’hôte Windows.
Configurer le réseau
Par défaut, les conteneurs utilisent un réseau ponté qui utilise l’adresse IP de l’hôte Docker. Cependant, selon les détails de la documentation. Si vous souhaitez connecter vos conteneurs Windows à un réseau spécifique en production, vous pouvez le faire avec une configuration supplémentaire. Vous pouvez changer cela manuellement :
Wayland est un protocole du serveur d’affichage pour Linux et Unix. Dans la plupart des distributions, il est utilisé par défaut à la place de X11. Mais si les pilotes propriétés NVIDIA sont installés, Linux peut revenir à Xorg.
Dans ce tutoriel, je vous donne plusieurs commandes pour vérifier si le bureau Linux est en Wayland ou Xorg.
Comment vérifier si le bureau Linux Wayland ou Xorg (X11)
Depuis le terminal
Ouvrez le terminal Ubuntu par la recherche d’application ou par le raccourci clavier CTRL+ALT+T. Plus de détails : Comment ouvrir terminal Ubuntu
Puis saisissez la commande suivante
echo $XDG_SESSION_TYPE
Cela retourne Wayland ou X11
Une alternative est la commande loginctl pour cibler le type de session :
Dans Linux, chaque application, outil ou fenêtre que vous voyez sur l’écran de votre ordinateur de bureau ou portable provient d’une technologie de serveur d’affichage. Depuis 1987, le standard est le serveur X, la version la plus récente étant X11. Xorg (parfois connu sous le nom de X.org) est l’implémentation open-source la plus populaire d’un serveur X sous Linux.
Mais Wayland fait de la concurrence à Xorg. Wayland a été développé pour créer une approche plus rationalisée qui utilise des processus modernes. Le développement de Wayland a commencé en 2013, et la première version alpha a été publiée en janvier 2021. Depuis 2013, le débat autour de Wayland et Xorg n’a cessé d’enfler.
Dans ce guide complet, je vous explique tout ce qu’il faut savoir sur Wayland, le serveur d’affichage pour Linux, les différences avec X11 et quel est le meilleur.
Qu’est-ce que Wayland
Wayland est un protocole de communication et un serveur d’affichage pour les systèmes Unix-like, principalement utilisé sur les systèmes Linux. Il a été développé comme une alternative au serveur d’affichage X11, qui était le standard de facto depuis de nombreuses années.
Le projet Wayland Display Server a été lancé par Kristian Høgsberg, développeur chez Red Hat, en 2008. Contrairement à X11, Wayland est conçu pour être plus rapide et réduire la latence. Il simplifie également la gestion des fenêtres et des événements d’entrée
Wayland se compose d’un protocole et d’une implémentation de référence appelée Weston. Le projet développe également des versions de GTK et de Qt qui rendent vers Wayland au lieu de X. La plupart des applications devraient prendre en charge Wayland par l’intermédiaire de l’une de ces bibliothèques sans modification de l’application.
Wayland est considéré comme le remplaçant du serveur X.Org vieillissant.
Comment fonctionne Wayland
Wayland est conçu de manière modulaire. Il sépare le serveur d’affichage (Wayland compositor) et les clients (applications), ce qui permet une meilleure isolation et une sécurité améliorée.
Le protocole Wayland suit un modèle client-serveur dans lequel les clients sont les applications graphiques qui demandent l’affichage de tampons de pixels sur l’écran, et le serveur (compositeur) est le fournisseur de services qui contrôle l’affichage de ces tampons. Un compositeur est un gestionnaire de fenêtres qui fournit une mémoire tampon hors écran pour chaque fenêtre. La mémoire tampon de la fenêtre contient une image ou d’autres effets graphiques tels qu’une animation, et l’écrit dans la mémoire de l’écran.
Le rendu est effectué par le client via EGL, et le client envoie simplement une requête au compositeur pour indiquer la région qui a été mise à jour. EGL (Embedded-System Graphics Library)est une interface de programmation d’applications (API) qui fournit un moyen standard pour les applications graphiques de créer et de gérer des contextes de rendu graphique. Elle fait le lien entre ses API de rendu, comme OpenGL ES ou OpenVG, et le système de fenêtrage du système d’exploitation sous-jacent.
La communication entre le client et le composeur se fait par IPC via l’espace noyau.
Wayland VS Xorg (X11) et pourquoi Wayland est meilleur
Tout comme Xorg, Wayland utilise aussi les technologies récentes du noyau Linux comme le DRI (Direct Rendering Infrastructure,), KMS (Kernel-based mode-setting), et GEM (Graphics Execution Manager), dans le but de fournir un serveur d’affichage minimal, léger et performant.
Mais Wayland priorise la performance et la sécurité. Il réduit la complexité de la communication entre les composants et permet aux applications d’interagir plus efficacement avec le serveur d’affichage. Dans la majorité des cas, le serveur X n’est plus qu’un intermédiaire qui introduit une étape supplémentaire entre les applications et le compositeur et une étape supplémentaire entre le compositeur et le matériel. Sous Wayland, les fonctions du serveur d’affichage et du gestionnaire de fenêtres sont combinées dans le compositeur Wayland correspondant. Le protocole Wayland permet au compositeur d’envoyer les événements d’entrée directement aux clients et au client d’envoyer l’événement d’endommagement directement au compositeur. Les clients effectuent le rendu localement et communiquent directement avec le compositeur.
Ainsi, l’application sait ce qu’elle veut rendre. Le rendu côté client réduit les étapes généralement associées au processus client/serveur traditionnel. Les applications dessinent la fenêtre dans laquelle elles vont s’exécuter et envoient ensuite leurs informations d’affichage à Wayland. Avec Wayland, le compositeur est le serveur d’affichage.
Wayland offre une base de code simplifiée, ce qui présente l’avantage supplémentaire de réduire le gonflement dû à des années de développement pour faire fonctionner Xorg au fur et à mesure des évolutions technologiques. Le passage à un rendu côté client augmente les temps de chargement et, dans la plupart des cas, offre une interface plus simple. Ainsi, Wayland supprime ces étapes supplémentaires et simplifie le rendu pour offrir des performances plus fluides et réactives que X11.
Du point de vue de la sécurité, Wayland montre une nette amélioration de l’isolation au niveau de l’interface graphique. De par sa conception, Xorg ne permet pas cette fonctionnalité. Xorg suppose que tous les programmes ne sont pas nuisibles. Lors de l’exécution de plusieurs applications graphiques, Xorg ne les isole pas les unes des autres. L’entrée de commande a le potentiel d’enregistrer les frappes de touches, par exemple, des processus pour de nombreuses applications. Wayland restreint les interactions entre les applications, limitant la capacité des applications malveillantes à affecter d’autres processus ou à intercepter des données sensibles.
Enfin Wayland offre une meilleure prise en charge des périphériques d’entrée, tels que les claviers, souris et écrans tactiles, en les intégrant plus étroitement dans le système graphique.
En résumé, Xorg est un intermédiaire qui crée des étapes supplémentaires entre les applications, le compositeur et le matériel. Wayland rationalise ce processus en éliminant l’étape du serveur X pour fournir un protocole plus moderne et plus cohérent que X11.
Quelles sont les limites et les problèmes de Wayland
Il y a plusieurs raisons pour lesquelles Xorg reste la version par défaut de Linux. Xorg est familier, car il est utilisé depuis plus de 30 ans. Cette longévité s’accompagne d’un bagage, car le codage et les ajouts rendent X trop lourd. Cependant, comparé à Wayland, Xorg est mieux conçu pour ajouter de nouvelles capacités ou fonctionnalités.
Les jeux vidéo et les applications graphiquement intenses conçues pour X11 ont tendance à mieux fonctionner sur Xorg. Au-delà de ces deux exemples, de nombreuses applications natives encore utilisées ont été écrites pour Xorg. Même sur les systèmes les plus récents, X et Xorg restent l’application de fenêtrage par défaut, bien que Wayland soit installé sur de nombreux systèmes. En ce qui concerne les jeux, des problèmes de déchirure d’écran, d’artefacts ou de problème de rafraîchissement sont connus.
Ainsi, l’adoption de Wayland prend du temps car il faut aussi réécrire les applications. Pour minimiser cela, Xwayland a été créé. Il s’agit d’un composant du système graphique Wayland qui agit comme un pont de compatibilité en permettant aux applications conçues pour X11 (l’ancien système d’affichage) de s’exécuter sur un serveur Wayland. Il facilite la transition vers Wayland en offrant une compatibilité avec l’immense catalogue d’applications existantes pour X11.
L’utilisation de certains pilotes propriétaires comme NVIDIA peuvent aussi poser des problèmes. Il existe plusieurs domaines dans lesquels le pilote NVIDIA ne présente pas les mêmes caractéristiques que X11 et Wayland. Cela peut être dû à des limitations du pilote lui-même, du protocole Wayland ou du compositeur Wayland spécifique utilisé. Au fil du temps, cette liste devrait s’alléger au fur et à mesure que les fonctionnalités manquantes seront implémentées à la fois dans le pilote et dans les composants en amont, mais ce qui suit reflète la situation à la date de publication de cette version du pilote. Notez que cela suppose un compositeur avec un support raisonnablement complet pour les extensions du protocole Wayland liées au graphisme. La liste des limitations est fournie par NVIDIA dans ce lien : https://download.nvidia.com/XFree86/Linux-x86_64/515.65.01/README/wayland-issues.html
Wayland dans les distributions Linux
La prise en charge de Wayland peut varier en fonction de l’environnement de bureau et des pilotes graphiques utilisés. Certains environnements de bureau, comme KDE Plasma, prennent en charge Wayland, mais leur adoption peut être moins répandue que celle de GNOME. Il est possible souvent proposer en option lors de l’ouverture du bureau Linux mais pas forcément par défaut.
Ainsi, il en résulte que l’adoption de Wayland varie beaucoup selon la distribution Linux. Voici un tour d’horizon :
Fedora : Fedora a été l’une des premières distributions à adopter Wayland par défaut, notamment avec Fedora 25 et les versions ultérieures. GNOME, l’environnement de bureau par défaut de Fedora, fonctionne sur Wayland.
Ubuntu : Bien qu’Ubuntu utilise toujours Xorg par défaut dans ses versions stables, il offre la possibilité d’utiliser Wayland avec l’environnement de bureau GNOME. Ubuntu 17.10 utilise Wayland par défaut. Dans Ubuntu 24.04, Wayland est par défaut pour les utilisateurs des pilotes NVIDIA propriétaires
Arch Linux : Arch Linux propose Wayland dans ses dépôts officiels et prend en charge plusieurs environnements de bureau qui fonctionnent sur Wayland, tels que GNOME, KDE Plasma, et Sway (un gestionnaire de fenêtres Wayland inspiré de i3)
openSUSE : openSUSE propose une prise en charge de Wayland avec son environnement de bureau GNOME. Il est possible d’utiliser Wayland avec d’autres environnements de bureau également, mais GNOME est le plus largement pris en charge
Debian : Debian propose la prise en charge de Wayland dans ses dépôts officiels. Bien qu’il ne soit pas activé par défaut dans la version stable, il est disponible en tant qu’option pour les utilisateurs qui souhaitent l’utiliser avec des environnements de bureau tels que GNOME et KDE Plasma
Endless OS : Endless OS, une distribution Linux axée sur l’éducation et les pays en développement, utilise Wayland par défaut avec son propre environnement de bureau basé sur GNOME appelé EOS Shell
Wayland est est configuré par défaut pour la plupart des cas d’utilisation dans RHEL 8, suivi de la dépréciation du serveur Xorg dans RHEL 9, avec l’intention de son retrait dans une future version. Dans RHEL 10, le serveur Xorg et d’autres serveurs X (à l’exception de Xwayland) sont supprimés
Xorg et Wayland sont deux protocoles graphiques utilisés dans les systèmes d’exploitation Unix-like, principalement sur les distributions Linux, pour gérer l’affichage graphique et les interactions avec l’utilisateur.
La plupart des distributions Linux utilisent par défaut Xorg. Toutefois, lorsque vous installez les pilotes NVIDIA propriétaires ou pour différentes raisons, le gestionnaire de fenêtres peut être Xorg.
Voici comment passer de Xorg à Wayland notamment sur Ubuntu et Debian.
Comment passer sur Wayland dans Linux
Par défaut, Ubuntu utilise Wayland. Toutefois dans le cas où les pilotes propriétaires de NVIDIA sont installés sur Ubuntu, ce dernier repasse sous Xorg (X11). Cela fonctionne sur Ubuntu 22.04 ou Ubuntu 23.10. Veuillez noter que Ubuntu 24.04 LTS devrait être par défaut sur Wayland même si les pilotes NVIDIA propriétaires sont installés.
Voici comment activer Wayland avec les pilotes NVIDIA sur Linux :
Avant de passer sur Wayland, si vous avez une carte graphique NVIDIA, je vous conseille d’installer les pilotes version 550, cela règle beaucoup de problème. Suivez ce guide : Installer les pilotes NVIDIA sur Ubuntu (propriétaire)
Installez la librairies d’implémentation en cours d’une bibliothèque EGL (Embedded-System Graphics Library) pour la plate-forme externe pour Wayland :
sudo apt install libnvidia-egl-wayland1
Puis éditez le fichier de configuration GRUB :
sudo nano /etc/default/grub
Repérez la ligne GRUB_CMDLINE_LINUX et éditez pour ajouter la configuration suivante :
GRUB_CMDLINE_LINUX="nvidia-drm.modeset=1"
Puis mettez à jour la configuration GRUB :
sudo update-grub
Pour que l’hibernation et mise en veille prolongée fonctionne correctement, il faut activer certaines options. Toutefois le fichier de configuration peut être différents d’une distribution Linux à l’autre
Sur Ubuntu, éditez le fichier /etc/modprobe.d/nvidia-graphics-drivers-kms.conf
Sur Debian, modifiez le fichier /etc/modprobe.d/nvidia-power-management.conf
options nvidia NVreg_PreserveVideoMemoryAllocations=1 NVreg_TemporaryFilePath=/tmp/tmp-nvidia options nvidia-drm modeset=1 'article sur les problèmes rencontrés options nvidia NVreg_UsePageAttributeTable=1 options nvidia NVreg_RegistryDwords="OverrideMaxPerf=0x1"
Redémarrez l’ordinateur pour prendre en compte les modifications
sudo reboot
Sur l’écran de verrouillage, cliquez sur l’utilisateur
Puis en bas à droite, cliquez sur l’icône roue crantée puis sélectionnez Wayland (ici il s’agit de l’écran de verrouillage d’Ubuntu)
Pour vérifier que le bureau de Linux est bien en Wayland :
echo $XDG_SESSION_TYPE
Si Wayland n’apparaît pas dans la liste, suivez le paragraphe suivant pour l’activer.
Le display manager de GNOME (GDM) donne la possibilité de choisir le gestionnaire de fenêtres que vous pouvez utiliser.Vous pouvez très bien activer ou désactiver Wayland dans GNOME. Voici comment faire :
Éditez le fichier de configuration de GDM :
sudo nano /etc/gdm3/custom.conf
Pour forcer l’activation de Wayland dans gnome, positionnez l’option suivante sur True
WaylandEnable=true
Pour forcer la désactivation de Wayland :
WaylandEnable=false
Puis relancez GDM :
sudo systemctl restart gdm3
Vous devriez pouvoir choisir Wayland au démarrage de la session GNOME
Pourquoi passer de X11 à Wayland
Plusieurs raisons peuvent vous pousser à utiliser Wayland à la place de Xorg. Premièrement, Xorg n’est plus maintenu et vous expose à des problèmes de sécurité. Ce dernier étant un projet de 1980. Wayland a été lancé afin de proposer un gestionnaire de fenêtre plus moderne, notamment Wayland élimine le modèle client-serveur et permet aux applications d’interagir directement avec le serveur d’affichage. De plus, Wayland est projet actif, il propose des fonctionnalités qui n’existent pas sur X11. Dans mon cas, les performances sont vraiment meilleures sur Wayland, l’affichage est beaucoup plus réactif. C’est aussi le cas dans les jeux.
Quels sont les problèmes connus entre Wayland et les pilotes propriétaires NVIDIA
Le support de Wayland n’est pas encore totale, de plus certaines technologies ne sont pas encore supportés. Ainsi, des bugs existent.
Les fenêtres en plein écran des jeux et applications rencontrent des problèmes d’affichage. Certaines parties de la fenêtre sont noires, contiennent des artefacts, clignotements ou encore des bandes horizontales passent de haut en bas révélant un problème de rafraîchissement. Il existe une discussion à ce sujet : https://gitlab.freedesktop.org/xorg/xserver/-/issues/1317 Vous pouvez tenter d’ajouter MUTTER_DEBUG_FORCE_EGL_STREAM=1 dans /etc/environment et relancez la session GNOME. Toutefois, il faut savoir que cela risque de poser des problèmes de chargement des jeux mais surtout provoquer des baisses de performances. Dans mon cas, la mise à jour des pilotes NVIDIA en 550 a réglé le problème.
De plus, j’ai rencontré des erreurs suivantes qui semblent être à l’origine de freez :
[drm:nv_drm_atomic_commit [nvidia_drm]] ERROR [nvidia-drm] [GPU ID 0x00000 100] Flip event timeout on head 0
D’où la désactivation de fbdev (framebuffer Device – toujours en expérimental) depuis /etc/modprobe.d/nvidia-graphics-drivers-kms.conf :
options nvidia-drm.fbdev=0
En outre, la fréquence adaptative de l’écran (VRR/GSync) n’est pas encore tout à fait disponible. Les pilotes NVIDIA propriétaires supportent la fonctionnalité depuis la version 545. Toutefois, ce n’est pas encore le cas des gestionnaire de fenêtres. Par exemple, Gsync est en expérimentale sur la version 46 de GNOME (disponible à partir d’Ubuntu 24.04). La documentation ArchLinux en parle : https://wiki.archlinux.org/title/Variable_refresh_rate#Limitations
Parmi les commandes basiques Linux, on trouve la commande more. Elle est principalement utilisée pour afficher le contenu d’un fichier page par page, ce qui permet de lire facilement des fichiers volumineux sans être submergé par un mur de texte. Elle dispose aussi de fonction de recherche.
Dans ce tutoriel, je vous montre comment utiliser la commande more sur Linux avec des exemples.
Quelle est la syntaxe de la commande more
Voici la syntaxe :
more [-options] [-num] [+/pattern] [+numligne] <nom fichier>
Et la liste des options
Option
Description
-c ou –no-color
Désactive le surlignage en couleur de la sortie.
-n ou –line-numbers
Afficher les numéros de ligne au début de chaque ligne.
-d
L’invite est “[Appuyez sur l’espace pour continuer, sur ‘q’ pour quitter.]”, et affiche “[Appuyez sur ‘h’ pour les instructions.]” au lieu de sonner la cloche lorsque l’on tente de faire défiler le fichier au-delà de la fin.
-l
Ignore le saut de page (^L).
-f
Compte les lignes logiques, plutôt que les lignes d’écran (c’est-à-dire que les lignes longues ne sont pas pliées).
-p
Fait défiler un écran complet.
-c
Efface l’écran avant d’afficher la page.
-s
Réduit le nombre de lignes vierges en une seule.
-u
Mode texte plein en supprimant la mise en forme gras et souligné.
Les options de la commande more
Comment utiliser la commande more sur Linux
Par défaut, plus de commandes sous Linux affichent le fichier une page à la fois.
Vous pouvez naviguer dans le fichier à l’aide de différentes commandes :
Commande
Action
ESPACE ou f
Afficher les x lignes de texte suivantes. La valeur par défaut est la taille actuelle de l’écran.
Entrée
Afficher les x lignes de texte suivantes. La valeur par défaut est 1. L’argument devient la nouvelle valeur par défaut.
d ou ^D
Défiler de x lignes. La valeur par défaut est la taille de défilement actuelle, initialement 11.
s
Sauter x lignes de texte. La valeur par défaut est 1.
f
Sauter x lignes de texte. La valeur par défaut est 1.
b ou ^B
Revenir à x lignes de texte vers l’arrière. La valeur par défaut est 1. Ne fonctionne qu’avec les fichiers, pas avec les pipes.
‘
Aller à l’endroit où la dernière recherche a commencé.
=
Affiche le numéro de la ligne en cours.
q ou Q
Quitter
Les raccourcis clavier pour naviguer dans la fenêtre more
Recherche dans un fichier
La commande more vous permet également de rechercher une chaîne de caractères spécifique dans un fichier. Cette fonction est particulièrement utile lorsque vous avez affaire à des fichiers volumineux et que vous recherchez des informations spécifiques. Pour ce faire, vous pouvez utiliser le ‘/’ suivi de la chaîne de caractères que vous recherchez.
Voici un exemple :
Dans cet exemple, la commande “more” affiche le contenu de monfichier.txt à partir de la première ligne contenant la “chaîne de recherche”.
more +/"chaîne de recherche" monfichier.txt
Vous pouvez également utiliser des expressions régulières avec l’option /pattern pour rechercher des motifs plus complexes. Par exemple, pour rechercher toutes les lignes commençant par le mot “error”, vous pouvez utiliser la commande suivante :
more /^error/ /var/log/syslog
Il ne s’agit là que de quelques exemples d’utilisations avancées de la commande ‘more’. Comme vous pouvez le constater, ‘more’ est un outil puissant pour visualiser et naviguer dans les fichiers sous Linux. Cependant, comme tout outil, il a ses avantages et ses inconvénients, et son utilisation dépend des exigences spécifiques de la tâche à accomplir.
Visualiser plusieurs fichiers
L’une des fonctions les plus puissantes de la commande more est la possibilité d’afficher plusieurs fichiers de manière séquentielle. Par exemple, si vous avez trois fichiers texte – fichier.txt, fichier2.txt et fichier3.txt – vous pouvez les afficher en séquence avec la commande suivante :
more fichier1.txt fichier2.txt fichier3.txt
Dans cet exemple, la commande “more” affiche d’abord le contenu du fichier1.txt. Lorsque vous aurez fini de visualiser le fichier1.txt, elle affichera le contenu du fichier2.txt, et ainsi de suite.
Pour passer au fichier suivant, appuyez sur :n. L’observateur se déplace alors au début du fichier suivant.
Pour reculer d’un fichier, appuyez sur :p. Cela permet de revenir au début du fichier précédent.
Vous pouvez bien entendu utiliser le caractère joker, par exemple pour visualiser tous les fichiers dictionnaires :
more /usr/share/dict/*
Afficher que X lignes par pages
Une autre option est utile est l’option -n suivi qui vous permet de définir le nombre de lignes à afficher par page. Par exemple pour n’afficher que 5 lignes par page d’un fichier :
more -n 5 fichier.txt
Ouvrir un fichier à la première occurrence d’une recherche
Pour ouvrir un fichier à un numéro de ligne, passez l’option + accompagnée d’un numéro de ligne. Par exemple pour ouvrir
Dans un tutoriel précédent, je présentais différentes commandes Linux (jobs, fg, …) afin de pouvoir exécuter des processus en arrière-plan. Mais à la fermeture du terminal, un signal SIGHUP (Signal Hang UP) est envoyé pour terminer tous les processus du shell. C’est là qu’intervient la commande disown qui permet de marquer un travail et donc un processus afin de ne pas lui envoyer ce SIGHUP pour qu’il puisse continuer à s’exécuter une fois le shell fermé. De plus, elle permet aussi de retirer chaque des travaux spécifiques de la table des tâches actives.
Dans ce tutoriel, je vous montre comment utiliser la commande disown de Linux.
Quelle est la syntaxe de la commande disown
Voici la syntaxe :
disown <options> <job-id>
Où :
<options> : Il existe plusieurs options, mais la plus courante est “-h”, qui indique au shell de ne pas envoyer de HUP (HangUP) lorsque le shell parent se termine.
<job-id> : L’identifiant du travail (job) que vous souhaitez dissocier du shell. Vous pouvez trouver l’identifiant du travail en utilisant la commande “jobs” dans le shell.
Comment utiliser la commande disown
Comment continuer à exécuter un travail après avoir quitté une invite shell en arrière-plan
Quelques rappels rapides concernant l’exécution de commandes sur Linux. Pour lancer une commande qui s’exécute en arrière plan, ajoutez le caractère & à la fin de la commande. Par exemple pour lancer le téléchargement d’un fichier avec wget en arrière-plan et l’ouverture d’un fichier avec vim :
Pour lister les travaux en cours, utilisez la commande jobs :
jobs -l
[1]- 226923 En cours d'exécution wget -O /dev/null -q http://bouygues.testdebit.info/10G.iso &
[2]+ 226940 Arrêté (via la sortie sur tty) vim /tmp/univers.txt
La commande wget est indiquée par “-“, ce qui signifie qu’elle deviendra la tâche active si la commande vim est interrompue
La commande vim est désignée par “+”, ce qui signifie qu’il s’agit d’une tâche active
Seulement, si vous fermez le terminal ou la session SSH, l’exécution de la commande s’arrête aussi car le système envoie un signal pour terminer toutes les commandes rattachées au shell. C’est là que la commande disown entre en jeu car elle permet de dissocier un processus du shell. Ainsi, si vous fermez le shell, son exécution continue.
Lorsque vous quittez le terminal de votre système, tous les travaux en cours sont automatiquement interrompus. Pour éviter cela, utilisez la commande disown avec l’option -h :
disown -h <%jobID>
Dans notre exemple, nous voulons que la commande wget continue à fonctionner en arrière-plan. Pour éviter qu’elle ne se termine à la sortie, utilisez la commande suivante :
disown -h %1
Tous les travaux pour lesquels vous avez utilisé la commande disown -h continueront de fonctionner.
Autre exemple, imaginons que vous souhaitez exécuter une mise à jour du système avec apt-get en root en arrière-plan et qui ne s’arrête pas si la session se termine. Voici les commandes à utiliser :
sudo -i # Pour devenir root apt-get upgrade &> /root/system.update.log & # Mise à jour du système avec redirection de la sortie dans un fichier disown -h # Marquer apt-get pour que SIGHUP ne soit pas envoyé à la sortie exit # On quitte le shell root
Supprimer tous les travaux en cours avec la commande disown
Sans aucune option, chaque jobID est supprimé de la table des jobs actifs, c’est-à-dire que l’interpréteur de commandes bash utilise sa notion du job en cours qui est affiché par le symbole + dans la commande jobs -l :
disown
Pour supprimer tous les travaux en cours d’exécution, utilisez l’option -r :
disown -r
Pour supprimer tous les travaux, utilisez l’option -a :
disown -a
Suppression de travaux spécifiques
Pour supprimer un travail spécifique du tableau des travaux, utilisez la commande disown avec l’identifiant de travail approprié. L’ID du travail est indiqué entre parenthèses dans le tableau des travaux :
Dans notre exemple, si nous voulons supprimer la commande vim, nous devons utiliser la commande disown sur le job 2 :
Le sous-système Windows pour Linux (WSL) de Microsoft change la donne en offrant une expérience Linux complète au sein de Windows. Lorsqu’on utilise une distribution WSL, on peut avoir besoin de transférer des fichiers entre Windows et Linux. Ne vous inquiétez pas, accéder aux fichiers Windows depuis WSL et inversement est relativement simple.
Dans ce tutoriel, je vous donne toutes les étapes pas à pas pour y parvenir.
Comment transférer facilement des fichiers de Windows vers le WSL à l’aide de l’Explorateur de fichiers
Voici comment accéder aux dossiers de la distributions WSL dans Windows afin de pouvoir transférer des fichiers.
Ouvrez l’explorateur de fichiers et, dans la barre d’adresse, tapez \\wsl$ puis appuyez sur Entrée.
Ouvrez la distribution Linux avec laquelle vous travaillez
Naviguez dans l’arborescence des dossiers jusqu’à ce que vous atteigniez votre dossier personnel /home/<nom-utilisateur>
Cliquez avec le bouton droit de la souris sur le dossier contenant votre nom d’utilisateur et cliquez sur Épingler à l’accès rapide. Vous disposez maintenant d’un moyen pratique de naviguer vers votre dossier d’accueil WSL sur votre panneau de gauche
A partir de là, vous pouvez copier des fichiers vers ce dossier ou encore créer de nouveaux fichiers
Comment accéder facilement aux fichiers Windows à partir du WSL
Par /mnt
Si vous souhaitez accéder facilement aux répertoires des utilisateurs Windows dans WSL, vous pouvez tirer parti des liens symboliques de Linux. Depuis WSL, vous pouvez accéder à l’arborescence de Windows via /mnt/c.
Pour simplifier l’accès à vos fichiers personnels, vous pouvez créer un lien symbolique dans votre répertoire home. Voici comment faire :
Assurez-vous d’être dans votre répertoire personnel.
cd
Créez un répertoire. Appelons-le “winhome”.
mkdir winhome
Créez un lien symbolique vers votre dossier utilisateur Windows qui mène à ce nouveau répertoire.
ln -s /mnt/c/Users/<nom-utilisateur>/ ~/winhome
N’oubliez pas de remplacer <nom-utilisateur> par votre nom d’utilisateur Windows. L’affichage du répertoire winhome devrait maintenant montrer un lien symbolique réussi.
Après cela, vous pouvez accéder au dossier ~/winhome/<nom-utilisateur> qui vous donne accès à vos fichiers personnels
Si nous lançons un gestionnaire de fichiers dans WSL, nous pouvons voir l’arborescence de notre répertoire Windows depuis l’environnement Linux.
Dans quelques jours, Microsoft va participer à l'Open Source Summit 2024, mais pourquoi ? Bien que cela puisse surprendre, sachez qu'au final, c'est plutôt évident et cohérent.
L'Open Source Summit North America est un événement organisé par la Fondation Linux et l'édition 2024 se déroulera du 16 au 18 avril prochain, à Seattle, aux États-Unis. Microsoft va participer à cet événement mondial, tout en étant un sponsor "Platinum", au même titre que Docker et Red Hat. D'ailleurs, au passage, AWS et Google sont des sponsors "Diamond" de cet événement.
Bien que Microsoft soit toujours associé à une étiquette d'"éditeur de solutions propriétaires", notamment parce que son système d'exploitation Windows est un OS propriétaire, la position de l'entreprise américaine a évoluée depuis environ 10 ans. Depuis 2014 et l'arrivée en Satya Nadella en tant que Directeur général, pour être plus précis. Si Microsoft a commencé à adopter l'open source dans ses activités principales et à participer à différents projets, c'est grâce à lui.
Microsoft est impliqué dans de nombreux projets Open Source
À l'occasion de sa participation à l'Open Source Summit, Microsoft discutera de ses contributions à la communauté open source. Aujourd'hui, Microsoft se félicite de participer au développement de Linux, à des langages de programmation tels que PHP, Python et Node.js, mais aussi à PostgreSQL ou encore à ses propres solutions open source comme .NET Core, Visual Studio Code et TypeScript.
"En outre, l'open source est au cœur de notre stratégie produit et constitue un élément fondamental de notre culture. Aujourd'hui, plus de 60 000 employés de Microsoft utilisent GitHub et nous gérons plus de 14 000 dépôts publics couvrant tout, des meilleures pratiques et de l'ensemble de nos systèmes de documentation aux projets innovants tels que PowerTools et PowerShell.", peut-on lire sur le site de Microsoft.
La firme de Redmond partagera également ses meilleures pratiques pour l'utilisation des technologies open source et les tendances émergentes dans ce domaine. D'ailleurs, en interne, Microsoft a eu équipe en charge de veiller sur la bonne utilisation des logiciels libres : "Le Microsoft Open Source Programs Office (OSPO) veille à ce que nous utilisions correctement les logiciels libres, à ce que nous fournissions des solutions sécurisées à nos clients et à ce que nous participions de manière authentique aux communautés de logiciels libres."
Pour Microsoft, l'intérêt est aussi d'assurer une compatibilité et une prise en charge avec ses solutions telles que Microsoft Intune ou encore le Cloud Azure au sein duquel les organisations peuvent exécuter des machines virtuelles sous Linux. "Microsoft prend en charge les principales distributions Linux et collabore étroitement avec Red Hat, SUSE, Canonical et l'ensemble de la communauté Linux.", précise Microsoft.
Des chercheurs en sécurité ont découvert une vulnérabilité qu'ils considèrent comme le "premier exploit natif Spectre v2" qui affecte les systèmes Linux fonctionnant avec de nombreux processeurs Intel récents ! En exploitant cette vulnérabilité, un attaquant pourrait lire des données sensibles dans la mémoire. Voici ce qu'il faut savoir !
La vulnérabilité Spectre et l'exécution spéculative
Avant tout, commençons par quelques mots sur la vulnérabilité Spectre en elle-même, ainsi que sur l'exécution spéculative.
Découverte au sein des processeurs Intel et AMD il y a plusieurs années, Spectre et sa copine Meltdown sont parmi les vulnérabilités les plus populaires. Ces termes font aussi référence à des techniques d'attaques visant à exploiter les failles de sécurité en question. Spectre affecte de nombreux processeurs dotés de l'exécution spéculative et corriger cette faille de sécurité matérielle n'est pas simple, car cela affecte, de façon importante, les performances du CPU.
L'exécution spéculative vise à améliorer les performances de la machine grâce au processeur qui va chercher à deviner la prochaine instruction à exécuter. La puissance des processeurs modernes permet de prédire plusieurs chemins qu'un programme peut emprunter et les exécuter simultanément. Cela ne fonctionne pas toujours, mais quand c'est le cas, cela booste les performances. Malgré tout, cela représente un risque, car le cache du CPU peut contenir des traces avec des données sensibles (mots de passe, informations personnelles, code logiciel, etc.), et celles-ci sont potentiellement accessibles par un attaquant lorsqu'une vulnérabilité est découverte.
Il y a deux méthodes d'attaques nommées Branch Target Injection (BTI) et Branch History Injection (BHI).
L'exploitation de Spectre V2 sur Linux
Récemment, une équipe de chercheurs du groupe VUSec de VU Amsterdam a fait la découverte de Spectre V2, une nouvelle variante de l'attaque Spectre originale, associée à la référence CVE-2024-2201. Vous pouvez retrouver leur rapport sur cette page.
Le CERT/CC a mis en ligne un bulletin de sécurité à ce sujet, dans lequel nous pouvons lire ceci : "Un attaquant non authentifié peut exploiter cette vulnérabilité pour faire fuir la mémoire privilégiée du CPU en sautant spéculativement vers un gadget choisi.", c'est-à-dire un chemin de code.
Dans le cas présent, le nouvel exploit, appelé Native Branch History Injection (en référence à l'attaque BHI), peut être utilisé pour faire fuir la mémoire arbitraire du noyau Linux à une vitesse de 3,5 kB/sec en contournant les mesures d'atténuation existantes de Spectre v2/BHI.
Pour se protéger, le CERT/CC recommande d'appliquer les dernières mises à jour publiées par les éditeurs et précise ceci : "Les recherches actuelles montrent que les techniques d'atténuation existantes, à savoir la désactivation de l'eBPF privilégié et l'activation de l'IBT, sont insuffisantes pour empêcher l'exploitation de BHI contre le noyau/l'hyperviseur."
De son côté, Intel a mis à jour ses recommandations d'atténuation pour Spectre v2 et propose désormais de désactiver la fonctionnalité "Extended Berkeley Packet Filter" non privilégiée (eBPF), d'activer les fonctionnalités "Enhanced Indirect Branch Restricted Speculation" (eIBRS) et "Supervisor Mode Execution Protection" (SMEP).
Voici une vidéo de démonstration d'exploitation de cette vulnérabilité :
Qui est affecté par la vulnérabilité Spectre V2 ?
Le noyau Linux étant affecté, cette vulnérabilité va forcément impacter de nombreuses distributions. L'équipe de développement du noyau Linux mène actuellement des travaux pour trouver une solution. Mais, en fait, l'impact dépend aussi du matériel, car la vulnérabilité Spectre V2 affecte les processeurs Intel, et non les processeurs AMD.
D'un point de vue du système d'exploitation, si nous visitons le site de Debian, nous pouvons voir que les différentes versions sont vulnérables (Sid, Bookworm, Bullseye, Buster, etc.). SUSE Linux est également impactée, comme le mentionne cette page. Du côté de Red Hat Linux Enterprise, on affirme que l'eBPF non privilégié est désactivé par défaut, de sorte que le problème n'est pas exploitable dans les configurations standard.
Une liste publiée sur la page du CERT/CC permet d'accéder facilement aux liens des différents éditeurs et d'effectuer le suivi dans les prochains jours.
Finalement, cette nouvelle découverte souligne la difficulté de trouver un équilibre entre l'optimisation des performances et la sécurité, puisque ceci pourrait contraindre les utilisateurs à se passer de certaines fonctionnalités relatives au CPU.
Lorsque l’on quitte le shell d’un système Linux, tous les processus en cours sont généralement interrompus ou bloqués. C’est là que la commande nohup peut vous être utile. Tous les processus exécutés à l’aide de la commande nohup ignoreront le signal SIGHUP (Signal Hang UP), même après avoir quitté l’interpréteur de commandes. Cela permet donc d’exécuter des commandes en arrière-plan sans qu’il soit arrêter si vous fermez le terminal ou la session SSH.
Dans ce tutoriel, je vous explique comment utiliser la commande Nohup de Linux.
Comment utiliser la commande Nohup sur Linux
Démarrage d’un processus en arrière-plan à l’aide de Nohup
Dans ce premier exemple, vous souhaitez lancer en arrière-plan le téléchargement d’un fichier iso avec la commande wget.
nohup wget http://exemple.com/monfichier.iso &
Cette commande utilise nohup pour lancer un processus wget afin de télécharger un fichier volumineux. En ajoutant & à la fin, la commande s’exécute en arrière-plan, ce qui permet d’utiliser le terminal pour d’autres tâches. Le processus se poursuit même si l’utilisateur se déconnecte, ce qui garantit que le téléchargement s’effectue sans surveillance. La commande vous indique le numéro du travail entre crochet sui par le PID du processus :
[1] 33186
Vous pouvez lister les travaux en arrière-plan à l’aide de la commande jobs :
jobs -l
Si le script ou la commande ne produit aucune sortie standard, cette sortie est écrite dans nohup.out et non dans le terminal. Pour vérifier la sortie, nous pouvons utiliser tail pour suivre les mises à jour effectuées dans le fichier.
tail -f nohup.out
Vérifiez toujours le fichier ‘nohup.out’ pour toute sortie ou erreur de votre commande.
Arrêter le processus en arrière-plan
Si vous souhaitez arrêter ou tuer le processus en cours, utilisez la commande kill suivie de l’identifiant du processus, comme suit
kill 33186
Comment rediriger la sortie de la commande nohup
Imagions le cas où vous souhaitez exécuter un script en arrière-plan, tout en récupérant la sortie dans un fichier. Cela est possible grâce aux redirections de sortie Linux.
nohup ./script.sh > output.log 2>&1 &
Dans cette exemple, la commande nohup exécute un script personnalisé (script.sh). La redirection de la sortie est utilisée ici (> output.log 2>&1) pour capturer à la fois la sortie standard et l’erreur standard dans un fichier nommé output.log, garantissant ainsi que toute sortie du script est sauvegardée pour un examen ultérieur. Le & à la fin exécute le processus en arrière-plan.
Lorsque vous vous déconnectez d’une session Linux, le système envoie un signal HUP (hangup) à tous les processus actifs associés au terminal. Ce signal indique aux processus de se terminer. Mais lorsque l’on administre un système Linux, il peut parfois être nécessaire d’exécuter des commandes en arrière-plan. Par exemple, car on a besoin de libérer le terminal pour exécuter une seconde commande. Dans d’autres cas, lorsque l’on prend la main à distance par SSH, il peut être nécessaire que l’exécuter d’un script continue après la fermeture de la session.
Dans ce tutoriel, je vous donne plusieurs solutions pour lancer des commandes en arrière plan sur Linux.
Comment exécuter des commandes et processus en arrière-plan sur Linux
Avec le caractère &
Ajoutez l’esperluette à la fin d’une commande pour placer la commande en arrière-plan. Voici un exemple où on télécharger un fichier en arrière-plan avec wget :
Toutefois, cela ne suffit pas, si vous souhaitez que l’exécution du processus perdure après l’arrêt du terminal ou de la session. En d’autres termes, si vous vous déconnectez de votre terminal, tous les travaux en cours seront interrompus. Pour éviter cela, vous pouvez passer l’option -h à la commande disown. Cette option marque chaque jobID pour que le SIGHUP ne soit pas envoyé au job si l’interpréteur de commandes reçoit un SIGHUP. La syntaxe est la suivante :
disown -h <job-id>
Imaginons que vous souhaitez exécuter une mise à jour du système avec apt-get en root en arrière-plan et qui ne s’arrête pas si la session se termine. Voici les commandes à utiliser :
sudo -i # Pour devenir root apt-get upgrade &> /root/system.update.log & # Mise à jour du système avec redirection de la sortie dans un fichier disown -h # Marquer apt-get pour que SIGHUP ne soit pas envoyé à la sortie exit # On quitte le shell root
La commande nohup de Linux est un outil puissant qui vous permet d’exécuter vos processus en arrière-plan. Elle est extrêmement utile lorsque vous souhaitez exécuter un processus qui prend beaucoup de temps et que vous ne voulez pas occuper votre terminal ou votre session pendant toute cette durée.
La commande screen est un gestionnaire de fenêtres plein écran qui multiplexe un terminal physique entre plusieurs processus. Elle vous permet d’exécuter plusieurs sessions de terminal dans une même fenêtre et de passer de l’une à l’autre sans effort.
Voici comment démarrer une nouvelle session nommée ‘nom_session” avec la commande screen :
screen -S nom_session
Pour reprendre la session, utilisez l’option -r en indiquant le nom de la session :
Tmux, abréviation de “terminal multiplexer”, est une autre commande qui vous permet d’exécuter plusieurs sessions de terminal dans une seule fenêtre. Elle est similaire à screen, mais offre plus de fonctionnalités et une interface plus moderne.
tmux new -s ma_session
Dans cet exemple, nous démarrons une nouvelle session tmux nommée ‘ma_session’. La sortie “[detached (from session ma_session)]” indique que la session est en cours d’exécution en arrière-plan.
Pour s’attacher à la session, utilisez la commande attach :
A severe vulnerability (CVE-2024-3094) has been discovered in XZ Utils (5.6.0 or 5.6.1), a commonly used compression format. The vulnerability allows attackers to gain root access through SSH. XZ Utils is used in many Linux distributions; it is also available for Windows and has been incorporated into many other programs. Attackers can install programs, manipulate data, or create new accounts with full root privileges. While there are no reports of exploits in the wild, the potential impact is profound, and most Linux distributions have issued warnings. In this post, you will learn how to determine if your systems are affected and what to do if they are.
Dans cet article, nous allons revenir sur la porte dérobée présente dans la bibliothèque XZ Utils afin d'évoquer les distributions Linux affectées, ainsi qu'un outil permettant de vérifier si votre serveur est affecté ou non !
Pour rappel, la bibliothèque de compression de données XZ Utils, correspondante au paquet "liblzma", est victime d'une compromission de la chaîne d'approvisionnement (supply chain attack) : les deux dernières versions (5.6.0 et 5.6.1) contiennent du code malveillant qui permet de déployer une porte dérobée sur le système. Cette backdoor offre la possibilité de se connecter en SSH sur la machine et d'exécuter du code malveillant sans être authentifié.
Cette vulnérabilité est associée à la référence CVE-2024-3094 et elle est considérée comme critique (score CVSS v3.1 de 10 sur 10).
Tout d'abord, sachez que les versions vulnérables de XZ Utils sont utilisées par certaines distributions Linux en cours de développement, dont voici la liste :
Fedora Rawhide
Fedora 41
Debian Sid (les versions testing, unstable et expérimentale de Debian)
openSUSE Tumbleweed
openSUSE MicroOS
Par ailleurs, si vous utilisez Kali Linux, votre machine peut être affectée : "Si vous avez mis à jour votre installation Kali le 26 mars ou après, mais avant le 29 mars, il est crucial d'appliquer les dernières mises à jour aujourd'hui pour résoudre ce problème.", peut-on lire sur cette page du site de Kali Linux.
Désormais, les mainteneurs de ces différentes distributions ont fait le nécessaire pour revenir sur une version non vulnérable. Cependant, c'est-à-vous de faire la manipulation pour revenir en arrière si votre machine est affectée.
Pour vérifier si votre machine est affectée ou non, vous pouvez exécuter le script Bash "CVE-2024-3094 Checker" disponible sur GitHub. Ce script communautaire fonctionne sur les différentes distributions et va regarder qu'elle est la version de XZ Utils installée sur votre machine, et vous indiquer, si oui ou non, vous êtes vulnérable.
Par exemple, sur une machine Debian, la commande suivante est utilisée pour effectuer la vérification :
dpkg -l | grep "xz-utils"
Pour rappel, vous ne devez pas utiliser les versions 5.6.0 et 5.6.1 de XZ Utils, car elles sont compromises. D'ailleurs, si vous utilisez une distribution où le gestionnaire de paquets Apt est utilisé (Debian, par exemple), le script vous proposera de revenir sur la version stable non compromise la plus récente, à savoir la 5.4.6. Enfin, il est également recommandé de lire le bulletin de sécurité publié sur le site de la distribution que vous utilisez.
Grosse alerte de sécurité : la bibliothèque "liblzma" utilisée par de nombreuses distributions Linux est victime d'une compromission de la chaîne d'approvisionnement : les dernières versions contiennent du code malveillant qui permet de déployer une porte dérobée sur le système. Faisons le point sur cette menace.
La bibliothèque liblzma appelée aussi XZ Utils est présente dans de nombreuses distributions Linux, notamment Arch Linux, Fedora, Debian, OpenSUSE, Alpine Linux, etc... Il s'agit d'une bibliothèque de compression de données susceptible d'être utilisées par d'autres applications.
Il s'avère que deux versions de la bibliothèque liblzma sont impactées par une attaque de type supply chain : 5.6.0 ou 5.6.1. La version 5.6.0 date de fin février tandis que la version 5.6.1 a été publiée le 9 mars 2024. Ces deux versions du paquet XZ contiennent du code malveillant qui a été très bien dissimulé par les auteurs de cette attaque, par l'intermédiaire d'un fichier m4 avec du code obfusqué. Il est visible uniquement lorsque le paquet est téléchargé en intégralité, donc il est invisible sur Git, par exemple.
Andres Freund, ingénieur logiciel chez Microsoft, a fait la découverte de ce problème de sécurité en menant des investigations sur une machine Debian Sid, après avoir constaté que les connexions SSH étaient anormalement longues.
Si une version compromise du paquet XZ est installée sur une machine, alors une porte dérobée est également déployée. Celle-ci offre un accès distant à l'attaquant qui pourrait se connecter à votre machine par l'intermédiaire d'une connexion SSH, sans avoir besoin de connaître vos identifiants (car il y a un lien entre systemd et liblzma).
Sachez que ceci est considéré comme une vulnérabilité et que la référence CVE pour cette faille de sécurité critique est la suivante : CVE-2024-3094. Sans surprise, un score CVSS v3.1 de 10 sur 10 a été associé à cette vulnérabilité.
Quels sont les systèmes affectés ?
Même si plusieurs distributions telles que Debian, Fedora ou encore Arch Linux sont concernées, ceci n'affecte pas toutes les versions. En effet, ceci concerne avant tout les versions en cours de développement, dont Debian Sid qui est la future version stable de Debian.
Pour Fedora, sachez que Fedora Rawhide et Fedora 41 sont affectées par ce problème de sécurité. Au sein du bulletin de sécurité de Red Hat, nous pouvons également lire ceci : "Aucune version de Red Hat Enterprise Linux (RHEL) n'est concernée.", ce qui n'est pas surprenant.
Potentiellement, tout autre système avec le paquet XZ en version 5.6.0 ou 5.6.1 est également affecté, donc vérifiez vos machines. Dans ce cas, il convient d'effectuer un downgrade vers la version 5.4.6.
Cette commande doit permettre d'obtenir la version :
dpkg -l | grep "xz-utils"
Pour approfondir le sujet, vous pouvez lire cet article intéressant qui donne des détails techniques supplémentaires, ainsi que l'origine de cette compromission : un nouveau développeur qui est venu épauler le créateur de la bibliothèque XZ Utils.
Dans ce tutoriel, nous allons avoir comment configurer l'authentification LDAP de GLPI pour pouvoir se connecter à l'application GLPI à partir des comptes utilisateurs présents dans un annuaire Active Directory. Ainsi, un utilisateur pourra accéder à GLPI à l'aide de son nom d'utilisateur et son mot de passe habituel (puisque ce seront les informations de son compte dans l'Active Directory).
GLPI propose nativement un modèle d'authentification LDAP, ce qui lui permet de s'appuyer sur un annuaire de comptes externe, comme l'Active Directory de Microsoft. Il faut savoir que les comptes utilisateurs de l'Active Directory seront importés dans la base de données de GLPI, grâce à un processus de synchronisation. Lorsqu'un utilisateur Active Directory se connecte pour la première fois, son compte est créé dans GLPI. Avant cela, il n'est pas visible, sauf si vous décidez d'effectuer un "import en masse" des comptes AD dans GLPI.
Avant de passer à la configuration, voici quelques informations sur l'environnement utilisé.
Pour cette démonstration, le domaine Active Directory "it-connect.local" sera utilisé et le contrôleur de domaine SRV-ADDS-02 sera utilisé. Ce serveur dispose de l'adresse IP "10.10.100.11" et la connexion sera effectuée en LDAP, sur le port par défaut (389).
- Le compte utilisateur qui sera utilisé comme "connecteur" pour permettre à GLPI de se connecter à l'Active Directory se nomme "Sync_GLPI". Il est stocké dans l'unité d'organisation "Connecteurs" de l'annuaire (voir image ci-dessous). Il s'agit d'un compte utilisateur standard, sans aucun droit particulier sur l'annuaire Active Directory. Faites-moi plaisir : n'utilisez pas de compte Administrateur.
- Tous les utilisateurs qui doivent pouvoir se connecter à GLPI à l'aide de leur compte Active Directory sont stockés dans l'unité d'organisation "Personnel" visible ci-dessous. Elle correspond à ce que l'on appelle la "Base DN" vis-à-vis du connecteur LDAP de GLPI. Les autres utilisateurs ne pourront pas se connecter. En fait, ce n'est pas utile de mettre la racine du domaine comme base DN : essayez de restreindre autant que possible pour limiter la découverte de l'annuaire Active Directory au strict nécessaire.
- Les utilisateurs de l'Active Directory pourront se connecter à GLPI à l'aide de leur identifiant correspondant à l'attribut "UserPrincipalName" (mis en évidence, en jaune, sur l'image ci-dessous). Cet identifiant, sous la forme "identifiant + nom de domaine", leur permettra se connecter à GLPI avec un identifiant qui correspond à leur e-mail. L'alternative consisterait à utiliser l'attribut "SamAccountName" (soit l'identifiant sous la forme "DOMAINE\identifiant").
Voilà, maintenant, nous allons pouvoir dérouler la configuration !
II. Installer l'extension LDAP de PHP
L'extension LDAP de PHP doit être installée sur votre serveur pour que GLPI soit capable de communiquer avec votre serveur contrôleur de domaine Active Directory (ou tout autre annuaire LDAP).
Connectez-vous à votre serveur GLPI et exécutez les deux commandes suivantes pour mettre à jour le cache des paquets et procéder à l'installation de l'extension.
sudo apt-get update
sudo apt-get install php-ldap
Cette extension sera installée et activée dans la foulée. Vous n'avez pas besoin de relancer le serveur.
III. Ajouter un annuaire LDAP dans GLPI
Désormais, nous allons ajouter notre annuaire Active Directory à GLPI. Connectez-vous à GLPI avec un compte administrateur, puis dans le menu "Configuration", cliquez sur "Authentification".
Au centre de l'écran, cliquez sur "Annuaire LDAP".
Puis, cliquez sur le bouton "Ajouter".
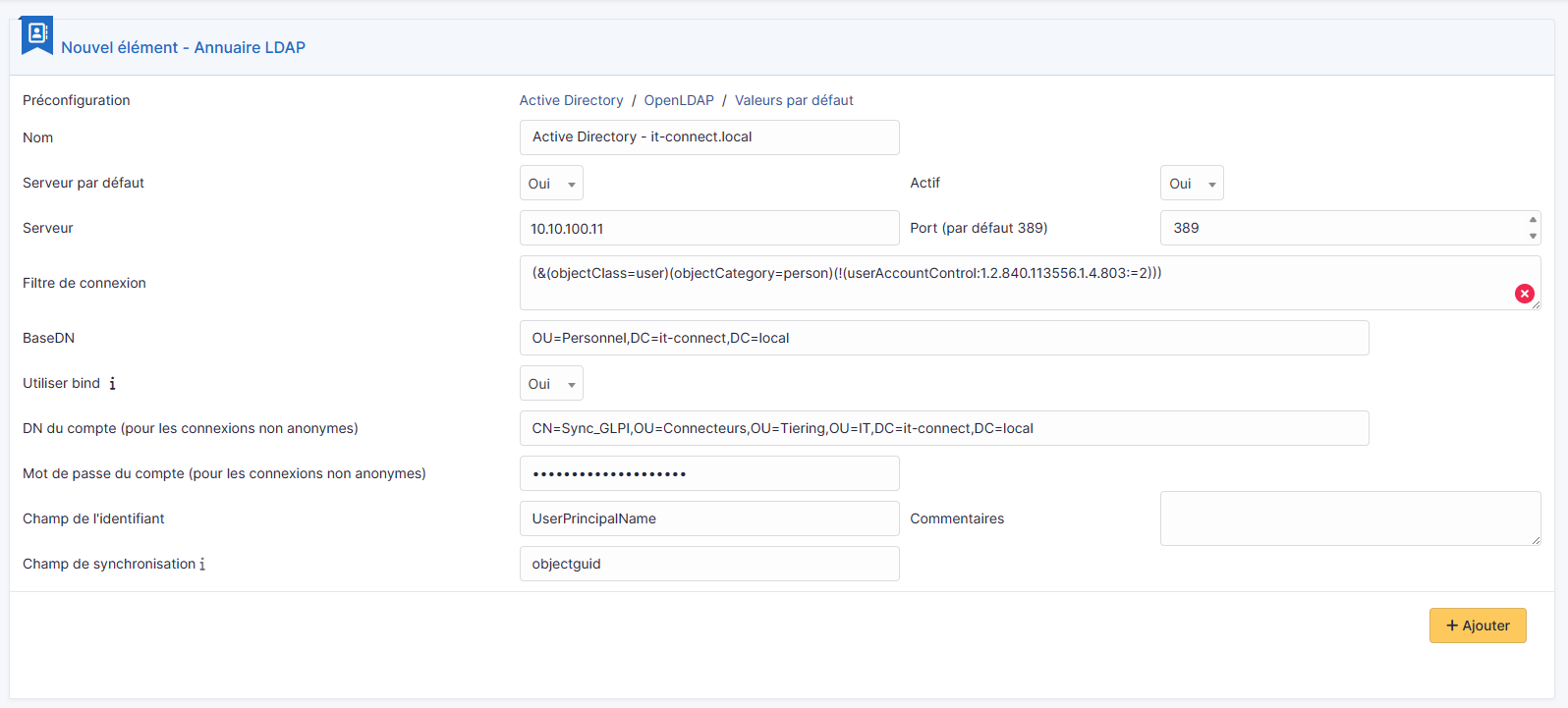
Un formulaire s'affiche à l'écran. Comment le renseigner ? À quoi correspondent tous ces champs ? C'est que nous allons voir ensemble.
Nom : le nom de cet annuaire LDAP, vous pouvez utiliser un nom convivial, ce n'est pas obligatoirement le nom du domaine, ni le nom du serveur.
Serveur par défaut : faut-il s'appuyer sur ce serveur par défaut pour l'authentification LDAP ? Il ne peut y avoir qu'un seul serveur LDAP défini par défaut.
Actif : nous allons indiquer "Oui", sinon ce sera déclaré, mais non utilisé.
Serveur : adresse IP du contrôleur de domaine à interroger. Avec le nom DNS, cela ne semble pas fonctionner (malheureusement).
Port : 389, qui est le port par défaut du protocole LDAP. Si vous utilisez TLS, il faudra le préciser à postériori, dans l'onglet "Informations avancées", du nouveau serveur LDAP.
Filtre de connexion : requête LDAP pour rechercher les objets dans l'annuaire Active Directory. Généralement, nous faisons en sorte de récupérer les objets utilisateurs ("objectClass=user") en prenant uniquement les utilisateurs actifs (via un filtre sur l'attribut UserAccountControl).
BaseDN : où faut-il se positionner dans l'annuaire pour rechercher les utilisateurs ? Ce n'est pas nécessaire la racine du domaine, tout dépend comment est organisé votre annuaire et où se situent les utilisateurs qui doivent pouvoir se connecter. Il faut indiquer le DistinguishedName de l'OU.
Utiliser bind : à positionner sur "Oui" pour du LDAP classique (sans TLS)
DN du compte : le nom du compte à utiliser pour se connecter à l'Active Directory. En principe, vous ne pouvez pas utiliser de connexion anonyme ! Ici, il ne faut pas indiquer uniquement le nom du compte, mais la valeur de son attribut DistinguishedName.
Mot de passe du compte : le mot de passe du compte renseigné ci-dessus
Champ de l'identifiant : dans l'Active Directory, quel attribut doit être utilisé comme identifiant de connexion pour le futur compte GLPI ? Généralement, UserPrincipalName ou SamAccountName, selon vos besoins.
Champ de synchronisation : GLPI a besoin d'un champ sur lequel s'appuyer pour synchroniser les objets. Ici, nous allons utiliser l'objectGuid de façon à avoir une valeur unique pour chaque utilisateur. Ainsi, si un utilisateur est modifié dans l'Active Directory, GLPI pourra se repérer grâce à cet attribut qui lui n'évoluera pas (sauf si le compte est supprimé puis recréé dans l'AD).
Ci-dessous, la configuration utilisée pour cette démonstration et qui correspond à la "configuration cible" évoquée précédemment.
Nom : Active Directory - it-connect.local
Serveur par défaut : Oui
Actif : Oui
Serveur : 10.10.100.11
Port : 389
Filtre de connexion : (&(objectClass=user)(objectCategory=person)(!(userAccountControl:1.2.840.113556.1.4.803:=2)))
BaseDN : OU=Personnel,DC=it-connect,DC=local
Utiliser bind : Oui
DN du compte : CN=Sync_GLPI,OU=Connecteurs,OU=Tiering,OU=IT,DC=it-connect,DC=local
Mot de passe du compte : Mot de passe du compte "Sync_GLPI"
Champ de l'identifiant : userprincipalname
Champ de synchronisation : objectguid
Quand votre configuration est prête, cliquez sur "Ajouter".
Dans la foulée, GLPI va effectuer un test de connexion LDAP et vous indiquer s'il est parvenu, ou non, à se connecter à votre annuaire. Si ce n'est pas le cas (comme moi, la première fois), cliquez sur le nom de votre annuaire, vérifiez la configuration, puis retournez dans "Tester" sur la gauche afin de lancer un nouveau test. Pour ma part, le problème venait du champ "Serveur" : j'avais mis le nom DNS du serveur à la place de l'adresse IP, mais cela ne fonctionnait pas. Pourtant, mon serveur GLPI parvient bien à résoudre le nom DNS.
Par ailleurs, vous pouvez explorer les différents onglets : Utilisateurs, Groupes, Réplicats, etc... Pour affiner la configuration. L'onglet "Utilisateurs" est intéressant pour configurer le mappage entre les champs d'une fiche utilisateur dans GLPI et les attributs d'un compte dans l'Active Directory. Quant à l'onglet "Réplicats", vous pouvez l'utiliser pour déclarer un ou plusieurs contrôleurs de domaine "de secours" à contacter si le serveur principal n'est plus joignable.
IV. Tester la connexion Active Directory
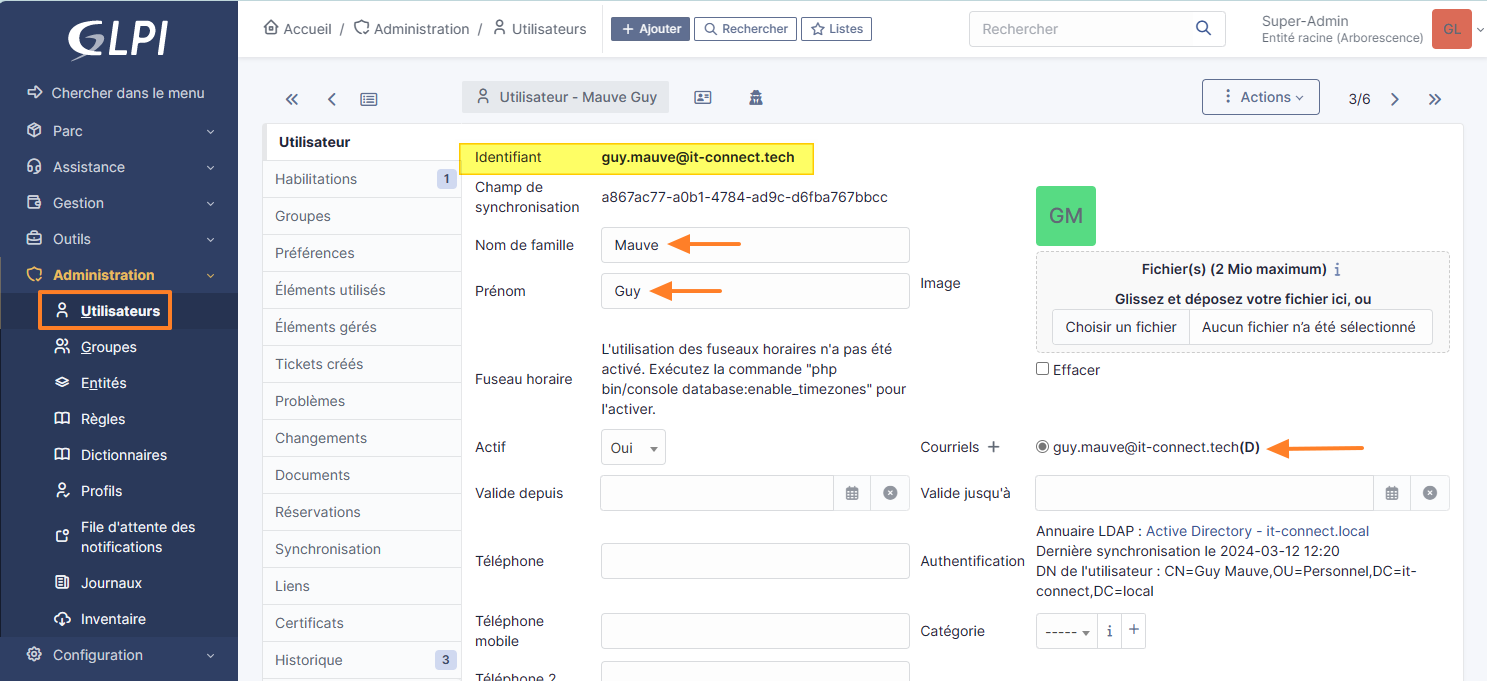
Si GLPI valide la connexion à votre annuaire Active Directory, vous pouvez tenter de vous authentifier à l'application avec un compte utilisateur. Pour ma part, c'est l'utilisateur Guy Mauve qui va servir de cobaye. Son login GLPI sera donc "[email protected]" puisque je m'appuie sur l'attribut UserPrincipalName. Pour le mot de passe, je dois indiquer celui de son compte Active Directory.
Remarque : la source d'authentification doit être l'Active Directory.
Voilà, l'authentification fonctionne ! L'utilisateur a pu se connecter avec son compte Active Directory et il hérite du rôle "Self-service".
Dans le même temps, à partir du compte admin de GLPI, je peux remarquer la présence d'un nouveau compte utilisateur dont l'identifiant est "[email protected]" ! GLPI a également récupéré le nom, le prénom et l'adresse e-mail à partir de différents attributs de l'objet LDAP.
V. Forcer une synchronisation Active Directory
A partir de GLPI, vous pouvez forcer une synchronisation LDAP de façon à mettre à jour les comptes dans GLPI "liés" à des comptes Active Directory, mais aussi pour importer en masse tous les comptes des utilisateurs Active Directory. Ceci vous évite d'attendre la première connexion et vous permet de préparer le compte : attribution du bon rôle, etc.
Cliquez sur "Administration" dans le menu, puis "Utilisateurs". Ici, vous avez accès au bouton "Liaison annuaire LDAP".
Vous avez ensuite le choix entre deux actions différentes, selon vos besoins.
Si vous cliquez sur "Importation de nouveaux utilisateurs", vous pourrez importer en masse les comptes dans l'Active Directory. Il vous suffit de lancer une recherche, de sélectionner les comptes à importer et de lancer l'import grâce au bouton "Actions".
Remarque : vous pouvez aussi importer des groupes Active Directory. Pour cela, suivez la même procédure, mais en allant dans "Groupes" sous "Administration".
VI. Conclusion
En suivant ce tutoriel, vous devriez être en mesure d'importer les comptes utilisateurs d'un annuaire Active Directory dans GLPI, pour faciliter la connexion de vos utilisateurs. Sachez que si un utilisateur change son mot de passe dans l'Active Directory, ce n'est pas un problème : GLPI vérifie les informations lors de la connexion.
Supprimer un service Linux (ou daemon) est une opération essentielle pour gérer efficacement un système d’exploitation basé sur Linux. Lorsqu’un service n’est plus nécessaire ou qu’il pose des problèmes, il est conseillé de le supprimer pour libérer des ressources système, améliorer les performances ou éviter des messages d’erreur. La suppression d’un service peut être réalisée de différentes manières selon la distribution Linux utilisée, mais généralement, elle implique l’utilisation de commandes spécifiques telles que “systemctl disable” ou “service stop“. Il est important de noter que la suppression d’un service peut entraîner des conséquences sur d’autres services ou fonctionnalités, il est donc recommandé de bien comprendre les implications avant de procéder à la suppression.
Suivez ce guide pour apprendre à supprimer un service dans Linux sans endommager le système.
Comment arrêter un service avec systemctl
Pour rappel, le fichier de déclaration d’un service en systemctl peut se trouver à deux emplacements /usr/lib/systemd/system/ ou /etc/systemd/system/.
Listez les services actif dans le système :
systemctl list-units --type=service
Puis identifiez le nom du service que vous souhaitez arrêter
Puis utilisez la commande suivante en remplaçant le nom du service :
sudo systemctl stop <nom service>
Par exemple pour arrêter le service CUPS :
sudo systemctl stop cups.service
sudo systemctl status cups.service
Il faut vérifier alors la ligne Active. Lorsque le service est désactivé, il est marqué en inactive (dead).
Active: inactive (dead) since Fri 2024-03-22 14:50:54 CET; 10min ago
Comment supprimer un service avec systemctl
Voici les commandes que vous devez utiliser pour supprimer un service dans Linux. Veuillez à remplacer <nom service> par le nom du service.
systemctl stop : arrête le service comme vu précédemment
systectl disable : désactive le service du démarrage de Linux en retirant les liens symboliques
Les commandes rm suppriment les fichiers du service. Attention car en supprimant le fichier de configuration, vous pourrez plus réactiver le service par la suite, sauf en réintégrant manuellement ce dit fichier
Enfin en dernier lieu, on réinitialise la configuration de systemctl
Pour simplifier encore, vous pouvez utiliser la commande ci-dessous. Définissez le nom du service à supprimer dans la variable service.
Warp is a modern AI-powered terminal emulator that essentially allows you to execute commands in plain English. The Linux edition recently joined the macOS version, and a Windows release is slated for later this year. In this post, we will look at Warp’s new Linux edition. However, aside from slightly different keyboard shortcuts, the different editions offer the same features. Like other modern terminals, Warp allows you to customize its appearance, apply themes, work in tabs, and even split one window into multiple panes for multi-tasking. In addition, Warp helps automate command execution with its Workflows, which can be shared with team members through the cloud.
Un chercheur en sécurité a identifié un nouveau logiciel malveillant destructeur de données, nommé AcidPour, et qui cible les équipements réseau ainsi que des appareils avec un système Linux. Voici ce que l'on sait sur cette menace.
AcidPour, qui est considéré comme une variante du malware AcidRain, est, ce que l'on appelle un "data wiper", c'est-à-dire un malware dont l'unique but est de détruire les données présentes sur l'appareil infecté. Autrement dit, le malware AcidPour est destiné à effectuer des actes de sabotages. D'ailleurs, AcidRain a été utilisé dans le cadre d'une cyberattaque contre le fournisseur de communications par satellite Viasat, ce qui avait eu un impact important sur la disponibilité des services en Ukraine et en Europe.
Le malware AcidPour quant à lui, a été identifié par Tom Hegel, chercheur en sécurité chez SentinelLabs, et il a été téléchargé depuis l'Ukraine le 16 mars 2024. Il présente plusieurs similitudes avec AcidRain, notamment au sein des chemins pris pour cible sur les machines infectées. Néanmoins, les deux malwares ont uniquement 30% de code source en commun. AcidPour pourrait être une variante beaucoup plus évoluée et puissante qu'AcidRain, grâce à la "prise en charge" de la destruction de données sur une plus grande variété d'appareils.
AcidPour est un malware destructeur de données capable de s'attaquer à des équipements réseau, notamment des routeurs, mais aussi des appareils avec une distribution Linux embarquée (Linux x86). Par exemple, il pourrait s'agir de cibler des NAS dont le système est basé sur Linux, car le malware s'intéresse aux chemins de type "/dev/dm-XX.
Sur X (ex-Twitter), Rob Joyce, directeur de la cybersécurité de la NSA, affiche une certaine inquiétude vis-à-vis de ce logiciel malveillante : "Il s'agit d'une menace à surveiller. Mon inquiétude est d'autant plus grande que cette variante est plus puissante que la variante AcidRain et qu'elle couvre davantage de types de matériel et de systèmes d'exploitation.
Enfin, sachez que SentinelLabs a partagé un échantillon de ce malware sur VirusTotal, et vous pouvez le retrouver sur cette page publique.