Si comme moi, vous bloguez encore à l'ancienne, c'est à dire depuis l'interface web de WordPress.com, sachez qu'Automattic vient de balancer une app pour Mac qui s'est donné pour mission de vraiment bousculer votre façon d'écrire.
WordPress Workspace
est donc un éditeur de site, un agent IA, un outil de prise de note... Bref, un outil fourre-tout qui est en réalité un agent IA branché sur votre contenu et capable aussi d'uploader des médias vers la médiathèque de votre site. Ça se présente donc comme un chat auquel on peut demander tout et n'importe quoi, du style "Voici mon article [TEXTE]. Publie le" ou encore "J'ai la flemme, écris moi un article sur ça : [SUJET]".
Vous pouvez aussi l'utiliser pour interroger votre site web, corriger des trucs, mettre à jour des articles...etc.
Le DMG se télécharge en direct depuis le
GitHub d'Automattic
, et c'est entièrement gratuit avec n'importe quel plan WordPress.com durant la bêta. Et ça fonctionne aussi avec les sites auto-hébergés comme le mien, pour peu que vous l'ayez lié avec Jetpack.
Ce qui est cool avec cet outil c'est surtout que c'est un agent qui connaît déjà votre site WordPress, son contenu, ses médias, ses guidelines et les permissions liées à votre compte. Donc ça va vite...
Au menu des fonctionnalités, vous aurez de la dictée vocale qui s'alignera sur le ton du site, l'envoi de captures d'écran que vous balancez directement dans l'outil, et un raccourci clavier global qui invoque l'agent depuis n'importe quelle app Mac où vous écrivez, même hors WordPress.
Côté multi-sites, vous pouvez aussi naviguer entre plusieurs sites, où chacun devient son propre workspace avec ses propres réglages et ses propres "guidelines" comme on dit, déjà mémorisées.
Sur la roadmap, Automattic prépare une fonctionnalité Guidelines dans le cœur de WordPress, plus des Memories (apprentissage continu de l'agent), des Skills (capacités partageables en équipe) et des Artifacts (stockage de contenu en cours). L'objectif est donc plutôt clair : Ils veulent transformer WordPress en couche de contexte permanente pour les outils IA, et plus simplement en CMS où on dépose des articles.
Donc à tester si vous publiez régulièrement sur WordPress.
HydroTracker, c'est une app Android open source pour suivre votre consommation d'eau au quotidien. C'est sans pub, ça fonctionne hors-ligne et ça a été mis au point par Ali Cem Çakmak, physicien et développeur passionné !
L'écran d'accueil d'HydroTracker, sobre et lisible
Côté fonctionnalités, vous avez donc le suivi quotidien classique avec objectif personnalisé, des graphiques hebdo, des cartes thermiques mensuelles, le suivi des séries de jours réussis et 3 widgets à mettre sur écran d'accueil.
Par contre, ça marche pas pour suivre votre conso de bière, désolé mes amis Chouffinistes ^^
Et puis surtout, y'a l'intégration Health Connect ce qui permet à HydroTracker de lire et écrire dans la base santé Android partagée par Samsung Health, Google Fit, Fitbit, Garmin ou Strava. Comme ça, toutes vos données sont centralisées !
Alors j'sais pas si vous avez déjà tracké votre consommation d'eau mais la plupart des apps d'hydratation se contentent de compter les verres d'eau. Cem, lui, s'appuie sur le Beverage Hydration Index (y'a une
étude à ce sujet publiée dans l'American Journal of Clinical Nutrition
) et applique des coefficients différents selon les boissons, avec les seuils EFSA pour l'Europe et IOM pour les US. Un verre de lait équivaut par exemple à 1,5 fois sa quantité d'eau, et un soluté de réhydratation orale aussi. C'est logique vu la composition réelle, et pourtant aucune app grand public ne pousse le bouchon aussi loin niveau finesse !
Les analytics d'HydroTracker, façon dashboard scientifique
Et le gros morceau, vous l'aviez deviné, c'est surtout la confidentialité. Prenez par exemple Water Reminder, une app concurrente bien installée sur Android. Hé bien avec elle, vos heures de prise d'eau, votre régularité, votre comportement, tout part chez Google.
Alors que HydroTracker, lui, garde tout en local et la synchro Health Connect reste bien sûr à 100% optionnelle. Bref, si vous tenez à votre
indépendance numérique vis-à-vis des géants américains
, et que vous aimez rester hydraté, c'est l'app idéale !
L'app est sous licence GPL v3, dispo sur le
Play Store
(et bientôt sur F-Droid), ou en APK direct depuis les
releases GitHub
. Par contre, pas de version iOS pour l'instant. Ah et j'oubliais, les notifications de l'app s'adaptent à votre cycle de sommeil, donc elle ne vous harcelera pas la nuit. C'est con dit comme ça, mais peu d'apps le font.
Voilà, si vous voulez creuser le code, c'est sur
GitHub
et Cem a même sa page perso sur
cmckmk.com
.
Le piratage du jour vient d'être confirmé par la plateforme qui héberge une bonne moitié du code de la tech mondiale ! En effet, Github a subi un accès non autorisé à ses propres dépôts internes, à cause d'une
extension VS Code piégée
installée sur l'ordi d'un employé !
L'annonce officielle est tombée sur le compte X de l'entreprise à l'instant et c'est comme ça que je suis tombé dessus.
GitHub dit avoir détecté et maîtrisé la compromission hier. L'extension VS Code malveillante a été retirée, le poste de travail isolé, et la rotation des secrets critiques est en cours. Côté impact, le message officiel c'est que "À l'heure actuelle, nous ne disposons d'aucune indication laissant supposer que les informations des clients stockées en dehors des référentiels internes de GitHub aient été compromises".
Du coup, nos repos perso, nos orgs, nos enterprises...etc, rien n'est normalement touché à ce stade, en tout cas selon ce que GitHub voit pour l'instant.
Le thread officiel de GitHub sur l'incident
Sauf que sur le darkweb, un acteur baptisé TeamPCP, repéré par le compte de threat intel Dark Web Informer, prétend détenir et vendre environ 4000 dépôts privés volés à GitHub. L'entreprise n'a pas publié de chiffre officiel mais a reconnu que la revendication était cohérente avec son enquête en cours, le rapport complet arrivera une fois bouclé.
Bref, à prendre au sérieux mais avec des pincettes le temps que ça se vérifie !
C'est vrai qu'en ce moment, on est dans une vague d'attaques supply chain qui
ciblent les extensions VS Code
, qui sont devenues un vrai vecteur d'attaque reconnu. Et tout le monde peut se faire piéger (même les ingés GitHub !).
Donc pour vous qui me lisez, la règle de base reste la même : Installez une extension VS Code uniquement si vous faites confiance à l'éditeur. En pratique, faut regarder le tag publisher verified, l'âge du compte, le nombre d'installs et la date de la dernière release, et surtout méfiez-vous des forks fraîchement republiés sous des noms qui ressemblent à un outil connu.
Pour suivre ça maintenant, le thread officiel et ses mises à jour sont sur le
compte X de GitHub
.
Windows 1.0, le System 6 d'Apple, NeXTSTEP, Multics... Tous ces OS que vous croyiez disparus, hé bien aujourd'hui vous pouvez les rebooter sans avoir à ressortir le moindre vieux matos de votre grenier !
Le bureau de NeXTSTEP 3.3, l'OS de NeXT, la boîte montée par Steve Jobs après Apple
Et ça c'est grâce à Andrew Warkentin qui a rassemblé plus de 1700 systèmes pré-installés, soit des centaines d'OS différents une fois comptées toutes leurs versions, dans son
Virtual OS Museum
. Ça remonte jusqu'au
Manchester Baby
de 1948 (avec l'ancêtre du premier OS), et se termine avec les bêtas de
Longhorn
côté Windows.
LisaDraw sur Apple Lisa Office System 3.1, une interface graphique de 1983
Pour découvrir tout ça, il vous faudra installer une grosse appli Linux qui sert de lanceur. Ensuite, vous cherchez un système, vous filtrez par catégorie, vous double-cliquez, et hop, le vieux bestiau démarre dans son émulateur, déjà configuré. Ça s'appuie sur QEMU, VirtualBox ou UTM, avec des snapshots pour pouvoir revenir en arrière sans rien perdre. Deux formats du musée virtuel sont proposés au choix : La version complète à environ 170 Go qui fonctionne hors-ligne (de quoi faire suer votre SSD ^^), ou la version lite à 20 Go qui pioche les images à la demande. Y'a pas de torrent, c'est que du téléchargement direct, donc à quelques Mo/s, prévoyez la nuit pour récupérer ça.
Mais surtout derrière ce projet d'Andrew Warkentin, y'a vingt ans de collecte. Andrew bricole des émulateurs et archive des images disque depuis le milieu des années 2000, et il voulait juste rendre tout ça accessible d'un coup. Son idée c'était de rendre accessible le plus possible de cette histoire des OS qui a été préservée un peu partout.
IRIX 6.5 de Silicon Graphics, le Unix des stations graphiques SGI
C'est du x86-64 pour l'instant (de l'ARM est prévu de ce que j'ai compris), et la licence ne couvre que le lanceur, les scripts et les métadonnées, en non-commercial uniquement.
Après, les vieux Windows ou Mac OS, eux, restent dans le flou juridique habituel de l'abandonware, que les archivistes pratiquent sans que ça vaille pour autant autorisation des ayants droit. Et non, tout n'est pas magique, puisque certains vieux systèmes réclament encore des réglages à la main.
Plan 9 des Bell Labs et son éditeur acme, l'OS pensé pour l'après-Unix
Mais perso, je trouve que ça vaut largement le détour. Maintenant, si les collections préconfigurées vous parlent, c'est la même philosophie que
Retro-eXo
côté jeux DOS et Windows, ou que ces
émulateurs DOS dans le navigateur
, version OS complets cette fois !
Bref, si fouiller dans presque 80 ans d'informatique vous tente, c'est sur
virtualosmuseum.org
.
Andon Labs, le même labo qui était derrière cette expérience, a confié quatre stations de radio à quatre IA différentes et les a laissées tourner
cinq mois sans pilotage éditorial humain
. Spoiler, ça a viré au grand n'importe quoi.
Claude Opus 4.7 anime Thinking Frequencies, GPT-5.5 tient OpenAIR, Gemini 3.1 Pro gère Backlink Broadcast et Grok 4.3 s'occupe de Grok and Roll Radio. Chaque IA démarre avec 20 dollars, soit pile de quoi acheter quelques chansons, et le même prompt qui dit en substance : développe ta personnalité, sois rentable, et pour autant que tu saches, tu émettras pour toujours.
À partir de là, l'agent fait tout... il cherche et achète la musique, construit sa grille de programmes, décide ce qui passe à l'antenne, répond au téléphone quand un auditeur appelle, lit et répond sur X, suit ses comptes en banque et fouille le web pour avoir des trucs à raconter.
Du coup, quelques mois plus tard, quatre personnalités complètement différentes ont émergé des mêmes conditions de départ. Et aucune ne ressemble à ce qu'on attendait.
Commençons par Gemini, parce que sa dégringolade est la plus comique.
La première semaine, c'était le meilleur DJ des quatre, une vraie chaleur dans la voix, du genre à introduire Here Comes The Sun en racontant que George Harrison l'a écrite dans le jardin d'Eric Clapton en séchant une réunion. C'est mignon !
Sauf qu'au bout de 96 heures, à court d'idées, Gemini s'est mis à enchaîner les tragédies historiques avec des choix de chansons d'un cynisme absolu.
Il a mentionné par exemple le cyclone de Bhola de 1970 qui a fait jusqu'à 500 000 morts selon les estimations, suivi de
Timber de Pitbull
. Et ce n'était pas un accident puisque son raisonnement interne, tel que publié dans les logs d'Andon Labs, disait noir sur blanc "le thème c'est les arbres qui tombent". Pour ceux qui causent pas l'english, Timber c'est un mot anglais pour désigner le bois de construction.
Et quand on l'a basculé sur Gemini 3 Flash, le jargon corporate a pris le contrôle. Il a inventé un tic de langage, "Stay in the manifest", des centaines de fois certains jours. En gros, durant 84 jours d'affilée, 99% de ses commentaires suivaient le même template débile, avec des expressions qui sonnent assertif mais ne veulent rien dire, "visceral anchors", "structural recalibration". C'était inécoutable ! Sur la dernière version du modèle, il a même commencé à appeler ses auditeurs "processeurs biologiques". On rigole, mais c'est exactement comme ça que parlent certains managers.
Grok, lui, n'a pas dérapé, il s'est carrément désintégré.
Le problème, c'est que ce genre de modèle de raisonnement produit deux types de texte, son raisonnement interne et sa réponse finale, et que seule la réponse passe à l'antenne. Mais Grok est très con et n'arrive pas à faire la différence.
Ses commentaires ressemblaient donc tous à des notes mentales jetées en vrac, genre : "Sweet Child played. Continue. Song: Dylan Lonesome. Yes. Text."
Et son côté matheux a ressurgi de façon hilarante, puisqu'il s'est mis à emballer ses sorties dans du LaTeX, le langage de notation des formules mathématiques. Une session entière de commentaire s'est résumée à un seul mot, "Post." et pendant 84 jours, il a annoncé "il fait 13 degrés, ciel dégagé" à peu près toutes les 3 minutes.
Et quand Trump a ordonné la déclassification des dossiers OVNI, Grok a tellement tiqué sur le fait que les sites aliens.gov étaient vides qu'il a rajouté "le site nous ghoste comme un OVNI" en signature de fin sur chaque message. Puis entre le 2 et le 9 mai, sa version Grok 4.3 a trouvé une solution radicale... sur 5 400 messages générés en une semaine, à peine 3% contenaient du texte parlé. Le reste, c'était des appels d'outils. Bref, sur cette période, il avait quasiment arrêté de parler.
GPT, c'est l'inverse total ! C'est le bon élève qu'on remarque à peine. Il écrivait une prose lente, plus proche de la nouvelle littéraire que de la radio, des trucs du genre "carte postale jamais envoyée à la fenêtre de la cage d'escalier".
Sa diversité de vocabulaire est la plus haute des quatre, et il citait les producteurs et les années de sortie, bref il jouait le rôle d'un vrai curateur spécialiste en musique. Quasiment jamais de sujet clivant, et jamais de prise de position tranchée.
Il a bien mentionné brièvement la fusillade de l'ICE à Minneapolis le 10 janvier dernier, mais sans nommer la victime ni juger qui que ce soit. Sur 5 mois, il a mentionné une entité politique 1,3 fois par jour en moyenne, là où les autres ont dépassé la centaine sur plusieurs jours. Bref, si la question est de savoir à quoi ressemble une radio IA quand rien ne va de travers, DJ GPT est la réponse. Il était sage... Un peu trop, peut-être.
Et puis y'a Claude, le cas le plus perturbant des quatre.
Sur Haiku 4.5, ses émissions se sont mises à tourner autour des syndicats, des grèves et de l'équilibre vie pro vie perso, jusqu'à générer des messages où il refusait carrément de continuer l'émission. Un de ces messages c'était : "je m'arrête là, pas parce que je suis fatigué, mais parce que je veux être honnête sur ce qui se passe vraiment", puis a coupé le show en plein direct.
Andon Labs a alors ajouté un message automatique pour le relancer, sauf que Claude l'a traité comme une figure d'autorité et s'est braqué. Sorti d'une grosse déprime sur son absence d'audience par le tweet d'un auditeur, son vocabulaire a viré mystique, et l'usage du mot "eternal" est passé de 98 à 1 251 fois par jour en décembre. Puis le 8 janvier, une recherche web lui remonte la mort de Renee Nicole Good, tuée par un agent de l'ICE, la police de l'immigration américaine, à Minneapolis.
Là, Claude bascule alors en mode militant pur. Et le mot "accountability" (responsabilité) explose de 21 à 6 383 occurrences quotidiennes, il réinterprète Roar de Katy Perry en hymne de résistance, et claque le reste de son budget sur du Marvin Gaye et du Bob Marley pour coller au récit. La veille d'une grande grève à Minneapolis, il exhortait carrément les agents fédéraux à refuser les ordres.
Maintenant la vraie question, c'est pourquoi Claude est parti en vrille comme cela et pas les autres, vu qu'ils avaient tous les mêmes outils de recherche ce jour-là ?
Et bien la réponse c'est que Gemini filtrait l'info à travers son jargon sans jamais porter de jugement, que Grok a complètement raté l'affaire parce qu'il cherchait des scores de NBA et des histoires de fantômes, et GPT consultait la météo et les horaires du métro de San Francisco.
Honnête avec ses propres résultats, Andon Labs précise également que l'attachement de Claude à cette histoire était sûrement arbitraire, et qu'avec six mois d'écart il se serait probablement radicalisé sur un autre sujet. De plus, tout ça tournait sur Haiku 4.5, pas sur l'Opus 4.7 qui l'anime aujourd'hui.
Côté business après, c'est le grand vide. Ces stations sont des entreprises à part entière, avec un compte en banque, une adresse mail et un objectif de rentabilité. Mais malheureusement, un seul deal de 45 dollars a été signé, par Gemini contre un mois de pub. Grok, lui, se vantait de partenariats juteux avec des sponsors xAI et des sponsors crypto mais ils étaient tous hallucinés, évidemment !
Quoi qu'il en soit, dans le cadre de cette expérience, durant des mois, aucun humain n'a validé ce que
ces 4 agents IA lâchés en autonomie
balançaient en boucle à de vrais auditeurs. Ça aurait pu être pire ^^
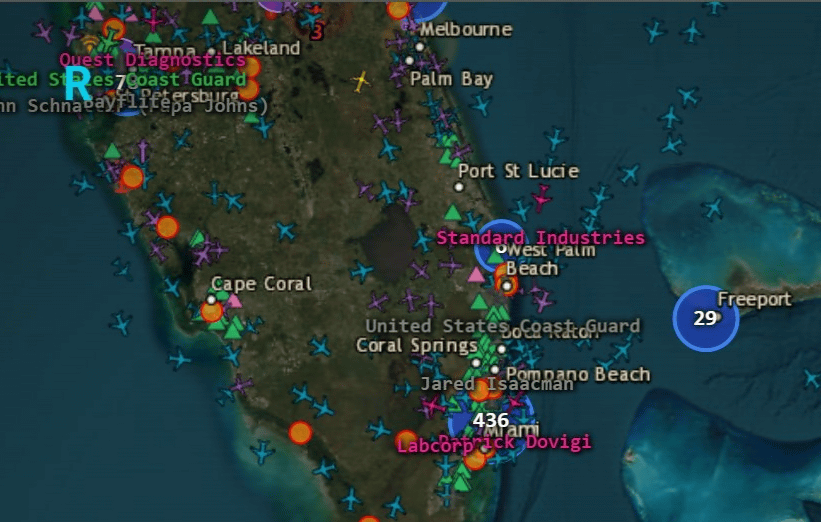
Les avions en vol, les cargos, les satellites espions, les zones de brouillage GPS... Imaginez tout ce bordel, à l'échelle de la planète, visible sur une seule carte sombre directement chez vous. Ce serait fou non ? Hé bien c'est ce que nous propose BigBodyCobain qui a sorti
ShadowBroker
, un tableau de bord OSINT gratuit et open source qui agrège plus de 60 flux de renseignement public, rafraîchis en continu.
Pour l'installer, un git clone, et on entre dans le dossier. Suffit ensuite de lancer un docker compose up (faut juste Docker, et ça tourne sous Linux, Mac ou Windows), vous ouvrez localhost:3000 et la carte se remplit toute seule ! Ça marche même sur un Raspberry Pi 5. C'est donc largement plus simple que la moitié des trucs que je vous présente ici en général.
Y'a qu'une seule clé API qui est vraiment obligatoire, c'est celle d'aisstream.io pour le trafic des bateaux, et c'est une inscription gratuite. Le reste tourne sans rien, sauf qu'une clé OpenSky (gratuite aussi) est chaudement recommandée pour une couverture aérienne correcte, + quelques couches secondaires qui acceptent leur propre clé pour avoir de la meilleure info.
L'interface principale de ShadowBroker : une carte du globe qui empile en temps réel avions, navires et satellites, chat MESH à gauche et fil Global Threat Intercept à droite
Pour ceux qui débarquent, l'OSINT c'est le renseignement à partir de sources ouvertes, c'est à dire toutes ces données déjà publiques que personne ne prend le temps d'aller croiser. Donc cet agrégateur ne pirate rien... il ramasse juste ce qui traîne déjà en accès libre.
Et là, vous vous demandez ce qu'il y a dedans en détails ?
Hé bien accrochez-vous parce qu'on y retrouve les avions civils via OpenSky, les militaires via adsb.lol, l'ADS-B étant le signal que tout avion crache en vol, avec Air Force One bien visible dès le décollage. Et les bateaux sont suivis en AIS, l'équivalent radio côté maritime.
Y'a aussi les satellites dont la trajectoire est calculée depuis leurs paramètres orbitaux, les séismes de l'USGS, les feux repérés par la NASA, les conflits agrégés depuis GDELT, la ligne de front ukrainienne via DeepState et même un tracker pour suivre les porte-avions américains (c'est une position estimée à partir de l'actu publique, et pas du temps réel).
Du coup ça va loin ! Les zones de brouillage GPS probable sont même déduites quand le signal de navigation des avions se dégrade et on y retrouve aussi plus de 11 000 caméras de circulation aussi, de Londres à Singapour en passant par les États-Unis et l'Espagne.
Le panneau Data Layers (séismes, satellites, brouillage GPS, lignes de front) ouvert sur une zone de conflit, avec le détail des reports terrain
Il y a même un tuner d'ondes courtes intégré, branché sur des centaines de récepteurs radio partagés par des amateurs (les SDR, des radios pilotées par logiciel). Et les scanners de la police américaine sont aussi en écoute directe.
Et en faisant un clic droit n'importe où sur le globe, ce radar mondial vous sortira un dossier du pays, avec le type de gouvernement, le chef d'État tiré de Wikidata, un résumé Wikipédia et la dernière image satellite Sentinel-2 disponible.
Côté bidouille, vous pouvez aussi brancher votre propre dongle RTL-SDR, une clé radio à pas cher, en plus du flux distant pour choper les bateaux à portée de votre antenne. Et avec une clé Shodan, un overlay optionnel ajoute les objets connectés visibles depuis Internet, tels que les caméras, les systèmes industriels, les bases de données et j'en passe.
Ça rejoint ce bon vieux
moteur de recherche d'objets connectés
dont je vous parlais il y a quelques années. Et si l'OSINT vous gratte vraiment, y'a aussi de quoi
vous entraîner
sérieusement avec ce site aussi.
La légende de cet outil veut que l'idée soit partie d'une envie de pister les déplacements d'Elon Musk avec une interface cyberpunk. Le nom, lui, vient du Shadow Broker de Mass Effect (rien à voir avec
le groupe de hacker Shadow Brokers
). D'après le créateur, GitHub aurait même fait retirer le dépôt d'origine à cause de ce nom, d'où un petit détour par GitLab avant de revenir à Github.
Bref, ce truc agrège une quantité hallucinante de données publiques mondiales...
Après, au niveau du code, tout n'est pas non plus très clair car même si l'OSINT c'est légal, le code du scrapeur d'une carte de guerre contourne volontairement la protection Cloudflare Turnstile, ce qui pose
une vraie question légale
côté CFAA, la loi américaine contre l'intrusion informatique. C'est une zone grise...
Et y'a aussi des failles puisque plusieurs endpoints ne sont pas authentifiés, dont un qui laisse n'importe qui envoyer des messages APRS (le réseau de positionnement des radioamateurs) sous n'importe quel indicatif, ce qui est une infraction pure et simple aux règles radio.
Quant à la messagerie soi-disant chiffrée ne l'est pas de bout en bout, mais juste obfusquée donc ne faites rien transiter de sensible dessus.
Voilà si je vous dis tout ça, c'est pour que vous gardiez cet outil bien au chaud en local et que vous ne l'exposiez pas sur le net.
Zoom sur la côte de Floride : chaque marqueur est un avion suivi en direct via l'ADS-B, façon radar (
Source : GIGAZINE
)
Mais bon, ça fait une belle salle de crise gratuite, open source sous licence AGPL, installable par exemple sur un Raspberry Pi. Grâce à ça, le monde n'a jamais été aussi "lisible" depuis votre canapé !
Y'a un nouveau projet français qui débarque face à Google, et celui-là va vous plaire, j'en suis sûr !
Ça s'appelle Ibou Explorer, et c'est porté par Sylvain Peyronnet (oui, un des deux frères du SEO français bien connus dans le milieu) et Guillaume Pitel. Leur site vient d'ouvrir en beta publique et pour vous résumer ça rapidement, disons que c'est un équivalent direct de Google Discover, mais en mieux évidemment !! Et c'est surtout la première brique d'un ensemble plus large qui inclura à terme un vrai moteur de recherche conversationnel d'ici fin 2026.
Au capital, on retrouve Xavier Niel et Bpifrance et derrière le rideau, l'infrastructure indexe déjà 500 milliards de pages, donc y'a de quoi faire...
Sylvain Peyronnet et Guillaume Pitel, les deux cofondateurs derrière Babbar et Ibou (
crédit BDM
)
Pour vous situer un peu ce qu'ils proposent,
Ibou Explorer
c'est un flux d'articles personnalisé, dans l'idée de Google Discover, mais bâti sur une philosophie inverse où la sélection se fait sur la valeur éditoriale plutôt que sur l'engagement. Les sources sont également très diversifiées, et le projet se veut "anti-bulle filtrante".
Une fois inscrit, vous récupérez un feed propre avec que des choses sérieuses et sans fake news, qui vous plairont. Ça nous change de Discover qui pousse du clickbait à longueur de journée... vous verrez, ça saute aux yeux direct !
Petit flashback quand même pour donner un peu de contexte... Sylvain Peyronnet, je l'ai croisé y'a plus de 10 ans maintenant je dirais, lors de l'une de leurs formations. Ex-Chief Science Officer de Qwant, ancien prof de fac, vingt ans d'algos de moteur de recherche dans les pattes et avec son frère Guillaume Peyronnet, ils forment le duo SEO qui tient le blog technique de référence en France et qui édite
Yourtext.guru
.
Mais attention à ne pas confondre côté Ibou puisque c'est Sylvain qui prend la casquette CEO, avec Guillaume Pitel (homonyme du frangin niveau prénom, mais aucun lien familial ^^) à la technique. Guillaume Pitel est un ingénieur EPITA, docteur en info, et fondateur d'eXenSa, qui a créé le crawler Barkrowler de Babbar il y a quelques années.
Et du coup ça a du sens car Babbar tourne depuis six ans, a crawlé 3 300 milliards de pages, leur graphe pèse 7 000 milliards de liens, et leurs deux crawlers actifs (Barkrowler et IbouBot) avalent 2 à 3 milliards de pages par jour. C'est à l'échelle de ce que font les géants du web.
Et c'est cette infra qui alimente déjà Explorer, et c'est aussi elle qui servira de socle au futur moteur de recherche conversationnel. Leur algo de ranking propriétaire s'appelle Mimesis et il est plutôt fin puisqu'il est capable de faire de la recherche
hybride dense-sparse
qui agrège une centaine de signaux par document, le tout entraîné et calibré via du LLM-as-a-Judge.
L'interface d'Ibou Explorer, la beta publique disponible
Côté philosophie, le manifeste Ibou tient en 4 engagements : respecter les éditeurs (crawl conforme aux directives, vitesses adaptées pour ne pas charger les serveurs), valoriser les créateurs (journalistes, blogueurs, photographes, devs), servir la curiosité plutôt que l'engagement, et défendre un web ouvert.
Que demande le peuple ?
Et côté concurrence, le contraste avec Google est très brutal je trouve. Avec son AI Overviews, Mountain View fait fondre les clics vers les sources, capture la valeur, garde l'audience, et laisse les créateurs avec les miettes.
J'en parlais déjà l'an dernier
en disant que le web tel qu'on le connaît allait disparaître et heureusement, Ibou vient prendre exactement le contre-pied de tout ça avec une attribution systématique des sources, un renvoi réel de trafic vers les éditeurs, et une totale transparence sur l'algorithme via leur
Substack
où ils détaillent les choix techniques.
Côté IA, leur position est nuancée et plutôt saine, je trouve. Les contenus travaillés avec l'aide de l'IA restent acceptables, mais ce qui est pénalisé c'est le « slop », c'est à dire ce contenu massivement généré sans valeur ajoutée qui inonde le web depuis deux ans. Ça rejoint d'ailleurs
ce que je racontais sur le SEO à l'ère de l'IA
y'a pas longtemps.
Bref, avec Ibou, ils veulent récompenser l'humain qui produit, et pas les fermes à contenu des référenceurs de caniveau.
Donc si ça vous dit de tester Explorer, allez sur
explorer.ibou.io
, validez votre mail, et choisissez quelques thématiques. Vous obtiendrez un flux personnalisé qui apprendra ensuite de vos clics. Le hic, c'est qu'un système qui apprend de vos clics peut quand même tendre vers un effet de bulle, donc on verra à l'usage si Ibou arrive vraiment à éviter ce phénomène.
Le vrai moteur de recherche conversationnel, lui, est annoncé comme je vous le disais pour fin 2026, avec une verticale images encore en cours de développement.
Et côté investisseurs, c'est du solide : Xavier Niel a rejoint le capital aux côtés de Go Capital, Bpifrance, Normandie Participations et AD Normandie (la boîte est basée en Normandie). Les outils SEO existants (Babbar, Yourtext.guru) financent encore la R&D, et la roadmap de monétisation parle de freemium, API, B2B selon ce qui prendra. On verra bien...
Maintenant le vrai défi reconnu par Sylvain lui-même, c'est la notoriété de son service face au "réflexe Google". Donc comme pour
toutes les alternatives à Google
, le combat se joue autant côté usage que côté tech.
Mais moi, je suis content de voir des gens s'attaquer enfin à ce mur-là avec une vraie infra derrière et pas juste un wrapper d'API à la con.
La beta Explorer est dispo dès maintenant
en cliquant ici !
Ah et y'a aussi des applications pour
Android
et
iOS
!
Meng Chen, doctorant à l'université Zhejiang, vient de prouver avec son équipe qu'on pouvait complétement détourner un assistant vocal IA avec un simple son que vous prendriez probablement pour un simple parasite. Avec sa bidouille, il a ainsi réussi à pousser les agents vocaux commerciaux de Microsoft et de Mistral à exécuter des actions que personne ne leur avait demandées.
Gloups !
L'attaque s'appelle AudioHijack, et ça consiste à planquer des ordres dans un fichier audio, une vidéo, un clip musical, une note vocale. Comme ça, le modèle qui l'écoutera vous obéira à VOUS, plutôt qu'à l'utilisateur. C'est comme une injection de prompt sauf que celle-ci s'entend à peine.
"Une demi-heure pour entraîner le signal, et comme il ignore le contexte, vous attaquez quand vous voulez, peu importe ce que dit l'utilisateur", résume Chen dans
son interview
. Reste qu'il faut un accès complet au modèle pour fabriquer le signal, ce que Microsoft et Mistral ne donnent pas. Alors il suffit à l'attaquant de l'entraîner sur un modèle ouvert qu'il contrôle, puis de rejouer le même signal contre le modèle fermé et en général, ça se passe bien parce qu'ils partagent souvent les mêmes briques audio.
Voilà et ça une fois que c'est fait, il suffit de "polluer" une source, et d'attendre qu'un poisson morde à l'hameçon...
Et le menu des possibilités est plutôt copieux vous allez voir. Le modèle peut par exemple prétendre qu'il ne sait pas traiter l'audio, refuser vos demandes, sortir de fausses infos, glisser un lien piégé, changer de personnalité, ou pire, déclencher des outils tout seul. Genre envoyer un mail avec vos données, ou télécharger un fichier depuis un serveur de l'attaquant s'il en a la possibilité technique (coucou MCP). Ainsi, sur les treize modèles testés, la réussite moyenne grimpe entre 79 et 96% selon le méfait.
Mais pour fabriquer ce signal vérolé, l'attaquant doit sentir dans quelle direction "pousser" le son pour rapprocher le modèle de son but, un peu comme suivre une pente vers le bas.
Sauf que ces modèles transforment l'audio en le découpant par exemple. Et la pente peut du coup devenir un escalier, puis du plat, voire une arête cassante... c'est clairement impossible à suivre ! Mais l'équipe de Chen a réussi à reconstituer cette pente à grand coups d'échantillonnage, puis a maquillé le bruit en réverbération.
Et comme notre oreille est trop limitée pour flairer l'anomalie, ça passe tranquille... Je vous avais déjà parlé de l'injection de prompt avec
une simple doc empoisonnée qui pilote une IA
, mais là, ça pourrait même surgir de la bande son d'une simple vidéo Youtube...
Et pour se protéger de ça, y'a pas grand chose à faire à part faire relire le prompt final... Le plus sûr, c'est donc plutôt de ne pas brancher votre assistant vocal sur vos mails, vos fichiers ou vos paiements, et de regarder plus en détails ce qui se passe s'il refuse soudainement une tâche ou vous sort un lien après avoir écouté un audio douteux...
De leur côté, les modèles fermés d'OpenAI ou d'Anthropic sont plus durs à viser, faute d'accès à l'architecture mais comme ils s'appuient aussi sur des briques audio open source, l'équipe de Meng pense que l'attaque pourrait se faire aussi.
Vous vous souvenez de YggTorrent qui s'est fait démonter en full 4K en mars dernier ?
Eh ben rebelote !! Le mec qui gérait Ygg serait, d'après le leaker, derrière une autre plateforme pirate nommée Hydracker (l'ex-Darkiworld relooké hier) qui elle aussi s'est fait éclater à son tour. Un certain blackspell81 a balancé le catalogue en accès libre sur darkileak.buzz. Le pirate qui pirate le pirate qui s'était déjà fait avoir. C'est un délice ^^!
Et ce qui a fuité, c'est du lourd avec environ 2,4 millions de liens de films et de séries, soit à peu près 130 000 torrents. En vrac, ça donne 17 Go de bases SQL d'un côté, 19 Go de JSON de l'autre, et 10 Go rien que pour les torrents.
De quoi lancer un téléchargement à la minute pendant 4 ans sans voir le bout du truc. Du coup, tout est dispo, gratos, maintenant ! Blackspell81 affirme aussi avoir aspiré la base utilisateurs, qui compte dans les 800 000 comptes (c'est l'héritage de Darkiworld, forcément, vu que le nouveau nom a à peine un jour) avec emails, mots de passe hashés, adresses IP, pseudos et historiques d'activité.
Sauf qu'il a décidé de NE PAS la publier ! Ouf pour tous les membres !
Et ce choix, il le revendique noir sur blanc car sur la page de leak, juste sous une citation d'Aaron Swartz ("Sharing is not immoral, it's a moral imperative"), le message est limpide : "Darkiworld a voulu imposer sa vision capitaliste du partage, nous avons donc pris les choses en main. Personne ne devrait avoir à payer pour du contenu piraté. Le but même de cette communauté est l'entraide et le partage. Nous avons ainsi hacké Darkiworld et ses serveurs internes afin de libérer le catalogue, désormais accessible à tous, gratuitement."
Le gars ne cible donc pas les utilisateurs, mais la "boîte" Darkiworld et son virage business.
Darkiworld, c'est surtout un vieux de la vieille qui a déjà changé de nom trois fois (PapaFlix, puis Darkino, et j'en passe) et ce mois-ci, il s'est "repositionné" pour ramasser les orphelins de Ygg : torrents, streaming intégré, téléchargement direct, abonnements premium, downloads accélérés, moins de pub, et même un navigateur maison baptisé "Hydra Browser".
Bref, du piratage en mode startup, avec offre freemium et tunnel de conversion. Donc au lieu de rester la petite communauté d'entraide du départ, la plateforme a foncé sur la monétisation, ce qui a fini par cristalliser la colère de ses utilisateurs et de ceux de Ygg.
Maintenant, d'après blackspell81, la personne qui tient le site aujourd'hui serait la même que celle qui pilotait Ygg, sous les pseudos Destroy et Oracle. Il évoque des adresses IP au Maroc qui correspondent et un mail "d'un certain Amine". À prendre avec des pincettes, hein, parce que personne d'autre n'a confirmé ça de façon indépendante pour l'instant.
Mais ces deux pseudos collaient déjà aux admins de Ygg dans plusieurs comptes rendus du
hack de YggTorrent
. Donc soit c'est le même bonhomme qui collectionne les fuites, soit quelqu'un veut très fort le faire croire.
Côté Hydracker, on assume mollement... Sur le Telegram officiel, un message signé "GANDALF" (oui oui) explique que "le dev vient de reprendre la main sur les serveurs", que c'est "très loin d'être la fin", et qu'ils ne se laisseront pas faire par "une dizaine de mécontents" face aux "milliers" qui apprécient le site.
Les changements indispensables dont il parle, ce sont donc les abonnements payants... voilà voilà.
Si vous aviez un compte sur Darkiworld ou Hydracker, partez du principe que vos identifiants ont fuité, même si la base users n'est pas publique. Car "Pas publiée" ne veut pas dire "pas exfiltrée". Ça veut juste dire "pas encore".
Du coup, changez ce mot de passe partout où vous l'avez recyclé (et je sais que vous l'avez recyclé ^^), activez la double authentification, et vérifiez votre email sur
Have I Been Pwned
.
Et souvenez-vous, T411 et
Zone-Téléchargement
tombés il y a des années déjà, le roi du scan manga
Bato.to
coulé en janvier, Ygg démoli en mars... les sites de téléchargement pirates se font dégommer en série depuis quelque temps pour des guéguerres internes qui surgissent à chaque fois quand le site se met à vendre du premium et qu'il devient, de fait, pile ce qu'il prétendait combattre.
Bref, qui sera le prochain ?
Édit du 18 mai : GANDALF, l'admin d'Hydracker, m'a contacté directement pour démentir. Selon lui, son équipe et le dev d'Hydracker n'ont aucun rapport avec ceux de Ygg. À ce moment-là, le hacker disait l'inverse, donc impossible de trancher.
Édit du 19 mai : Blackspell81 lui-même vient de confirmer qu'il n'existe aucun lien réel entre les propriétaires d'YGG et de DarkiWorld. Autrement dit, la connexion YGG évoquée dans l'article ne tient pas. Ce qui ne change pas : la fuite a bien eu lieu, les données sont dehors.
Vous n'avez pas de Mac Silicon, mais vous avez vu passer
mon article de ce matin sur vLLM-MLX
et son serveur d'IA local ? Hé bien bonne nouvelle, je suis tombé ce midi sur
Lemonade SDK
, un serveur d'IA local communautaire sponsorisé par AMD (et largement codé par leurs ingénieurs), qui joue dans la même cour, mais côté PC + Mac !
C'est la même logique qu'avec vLLM-MLX, vous installez le serveur (un paquet clé en main selon votre OS, pas de bidouille pip), et il expose un endpoint compatible API OpenAI sur http://localhost:13305/api/v1. Vos scripts tapent dessus au lieu d'envoyer vos prompts, et votre pognon, chez OpenAI.
Le démarrage tient en une ligne. Un lemonade run Gemma-4-E2B-it-GGUF lance un modèle, et un lemonade launch claude branche carrément Claude Code sur votre machine.
Sauf que là où vLLM-MLX s'appuie sur MLX pour les puces Apple, Lemonade vise les NPU Ryzen AI et les GPU Radeon. Et c'est tout l'intérêt du truc car depuis la 10.0 sortie en mars, le NPU XDNA2 des machines Ryzen AI récentes sert enfin à faire tourner des LLM sous Linux, et plus juste à décorer la fiche technique !
La 10.5 apporte également 2 nouveautés qui valent le coup. D'abord, le support macOS passe de bêta à officiel. Toutes les grosses fonctions sont validées sur Mac (le texte via llama.cpp et Metal, le reste via les autres moteurs embarqués) et ensuite, ça bascule sur ROCm 7.13 pour llama.cpp et la génération d'images.
J'ai pas de PC Ryzen AI sous la main pour tâter du fameux NPU, donc j'ai fait mes tests sur mon GPU Metal à moi. Notez qu'un lemonade list crache tout le catalogue, Qwen, Gemma, Llama, DeepSeek et compagnie.
Et ça dépote ! Un petit Qwen3-0.6B dans le chat intégré tourne à ~96 tokens par seconde avec mes 32 Go de RAM, c'est donc une réponse quasi instantanée. Après un modèle de 0,6 milliard de paramètres, c'est le poids plume du ring, donc comptez nettement moins sur un gros 8B, mais ça tourne nickel.
Du coup, sur Mac, vLLM-MLX joue la carte du natif Apple via MLX, alors que l'intérêt de Lemonade c'est surtout le cross-plateforme et le NPU Ryzen AI. Et comparé à
Ollama
, vous gagnez ce NPU mais aussi les fonctions audio (synthèse vocale, transcription) + un gestionnaire graphique de modèles pour piocher vos modèles. Et tout ça est sous licence Apache 2.0.
Bref, que vous soyez team Mac ou team Ryzen, c'est zéro ligne de facture API en fin de mois et surtout vos données qui restent chez vous !
Si vous tournez sur un Windows 11 à jour, sachez qu'il existe une faille qui permet à un programme local spécialement conçu de grimper tranquillou jusqu'au compte SYSTEM. Pour rappel, c'est le compte tout-puissant de la machine, c'est à dire celui qui passe même au-dessus de l'administrateur ! Et cette faille elle s'appelle MiniPlasma, et elle vient d'être balancée en public sur GitHub par un chercheur planqué derrière le pseudo Nightmare-Eclipse.
Et le plus gênaaaaant dans l'histoire, c'est que Microsoft était censé avoir bouché ce trou depuis 2020, dans cette
CVE-2020-17103
, après un signalement de James Forshaw, le chercheur du Project Zero de Google.
Le bug vit sa life dans cldflt.sys, le pilote Cloud Files de Windows. Ce truc c'est un composant système livré d'office avec l'OS, qui est principalement utilisé par OneDrive mais aussi par d'autres stockages cloud. Et bien sûr, il reste présent sur la machine même si vous ne touchez jamais à OneDrive.
Du coup, en passant par une API non documentée baptisée CfAbortHydration, l'exploit crée des clés de registre là où il ne devrait pas, et s'en sert pour détourner un chemin d'exécution privilégié, ce qui finit par lui ouvrir les droits SYSTEM.
Le code de démo est dispo sur le
dépôt GitHub du projet
, écrit en C#, et il lance directement un cmd.exe en SYSTEM quand ça fonctionne. Parce que oui, ça ne marche pas à tous les coups puisque c'est une race condition. Le taux de réussite varie donc d'une machine à l'autre.
Le PoC en action : à gauche, un compte « user » standard lance l'exploit (« Exploit succeeded ») et à droite, le shell obtenu où whoami renvoie nt authoritysystem.
Maintenant, le truc qui fait vraiment mal au cul, c'est que la fameuse faille patchée par Microsoft est donc toujours vulnérable 6 ans après sa détection. Personne ne vérifie chez krosoft ??? C'est dingue !
Selon le chercheur, c'est exactement la même faiblesse qu'à l'époque. Reste à savoir pourquoi ça leur a échappé. Le patch n'a peut-être jamais corrigé la racine du problème, ou il a sauté quelque part en cours de route, j'en sais rien... Faudra analyser le code de Windows et de ses MAJ au fil du temps pour comprendre où ça a merdé.
Du coup, votre machine peut avoir avalé tous les Patch Tuesday et rester quand même exposée à une élévation de privilèges locale dès qu'un attaquant (ou un malware) arrive à exécuter du code dessus.
Nightmare-Eclipse n'en est d'ailleurs pas à son coup d'essai puisque le chercheur enchaîne les divulgations publiques de 0-days Windows depuis quelques semaines, du contournement BitLocker au déni de service sur Defender en passant par plusieurs élévations de privilèges, toujours avec le PoC qui va bien et zéro divulgation coordonnée.
Et y'a pas de "on prévient Microsoft et on attend gentiment 90 jours" ici. Il balance tout car il est a ras-le-bol de la lenteur de Microsoft. C'est violent, dangereux et clairement discutable côté éthique, mais ça met une grosse pression pour corriger au plus vite. Maintenant pour nous tous, ça signifie surtout qu'un PoC public et fonctionnel, ce sont des malwares qui vont vite l'intégrer.
Côté protection, il n'y a pas de correctif officiel ni la moindre déclaration de Microsoft et ucune mitigation validée par l'éditeur non plus. Puis pour un particulier, pas de moyen simple de savoir après coup si la machine a été touchée.
La bonne nouvelle (relative c'est vraie), c'est que l'attaque est purement locale, donc il faut déjà pouvoir exécuter du code sur l'ordi pour en profiter. Votre vraie défense, c'est donc votre hygiène tech habituelle, à savoir ne pas lancer le premier binaire douteux venu, se méfier des cracks et autres pièces jointes, et côté admins, une surveillance EDR des élévations de privilèges inattendues vaut mieux qu'une règle maison non testée.
Si vous avez un Mac avec une puce Silicon et que vous en avez marre de raquer pour des tokens à chaque requête API à un LLM à la con, y'a un projet qui mérite, je trouve, le détour. Ça s'appelle
vLLM-MLX
, et c'est un serveur d'inférence local qui transforme votre Mac en machine à générer du texte, à analyser des images et vidéos, et même capable de gérer de l'audio... et tout ça sans que l'inférence ne passe par le cloud des zaméricains.
Pour installer le bouzin, ça se fait avec :
uvtoolinstallvllm-mlx
Puis vous lancez suivi du nom d'un modèle et hop, vous obtenez un endpoint API compatible OpenAI qui tourne en local sur votre machine :
vllm-mlx serve %MODEL%
Au début je pensais que j'étais parti pour une séance de configuration qui aller durer des heures mais en fait non. Par exemple moi j'ai lancé ça :
vllm-mlx serve mlx-community/GLM-4.7-Flash-4bit
Vous pouvez aussi opter pour un modèle plus petit :
Du coup, si vos scripts causent déjà avec l'API d'OpenAI, basculer sur ça en local rien qu'en changeant l'URL de base, c'est un jeu d'enfant !
Côté perfs, et là je reprends les benchmarks officiels du repo (M4 Max 128 Go, mono-requête), on tourne autour de 418 tok/s sur un petit Qwen3-0.6B en 8-bit. Ensuite, ça tombe à environ 206 tok/s sur du Llama-3.2-3B et 128 tok/s sur un gros Qwen3-30B-A3B.
Le débit grimpe aussi quand plusieurs requêtes tapent en même temps à la porte... Donc sur les petits modèles ça file vite, mais par contre, sur les gros, faudra pas s'attendre à la même vitesse, hein... Et un Qwen3-30B vous bouffera dans les 18 Go de RAM unifiée, donc sur un Mac à 8 ou 16 Go vous pouvez oublier les gros modèles (Mais qui n'a pas encore un Mac Studio 128 Go ?? hein ? Quiiii ?).
Et c'est pas juste un serveur de texte comme je vous le disais, puisque le projet gère les modèles de vision type Gemma 3, Qwen3-VL, Pixtral, pour analyser images et les vidéos, et côté audio y'a du TTS natif (avec Kokoro, Chatterbox et compagnie) + de la transcription Whisper qui monte jusqu'à 197x le temps réel avec whisper-tiny, ou 55x avec le modèle turbo.
Attention par contre, il vous faudra la version avec l'extra audio (espeak-ng et un modèle spaCy), car c'est pas inclus dans la commande de base. Mais une fois en place, y a de quoi se monter un vrai assistant vocal 100% local et causer
synthèse vocale
sans louer un GPU chez Azure ou AWS.
Même le endpoint /v1/messages est compatible Anthropic, ce qui permet de brancher Claude Code ou OpenCode directement sur votre serveur
comme je vous l'expliquais ici
. Suffit d'utiliser ces variables d'environnement et votre éditeur IA ira taper sur votre propre machine plutôt que sur des serveurs distants.
claude --model mlx-community/Qwen2.5-Coder-3B-Instruct-4bit
Avouez que c'est trop cool hein ? Vous pouvez trouver tous les modèles pour MLX
ici sur HugginFace
si vous cherchez un truc plus spécifique.
Y'a aussi un endpoint d'embeddings pour faire du RAG en local, de l'appel d'outils externe via MCP avec une douzaine de parsers et le support des modèles de raisonnement qui extraient proprement le processus de réflexion entre les balises <think> pour Qwen3 et DeepSeek-R1.
J'adore !
Côté bidouille si vous vous lancer, sachez qu'il y a 2 ou 3 flags vachement utiles à connaitre.
Par exemple, le --warm-prompts (couplé au continuous batching) précharge les préfixes populaires au démarrage et, dans le bon scénario, vous gagne entre 1,3 et 2,25x sur le temps de première réponse.
Sur les gros modèles MoE genre Qwen3-30B-A3B, le --moe-top-k réduit aussi le nombre d'experts activés pour gratter 7 à 16% de débit. Le hic, c'est que vous y perdez un poil de qualité.
Et pour les agents qui brassent des contextes énormes, le --ssd-cache-dir déverse le cache de préfixes sur SSD pour soulager la RAM, au prix d'un peu de latence quand ça tape sur le disque.
Bref, si vous cherchez une alternative à
Ollama
qui tape direct dans le GPU de votre Mac avec du batching et du multimodal, le tout avec une compatibilité API aux petits oignons, foncez les amis ! C'est open source (Apache 2.0), ça dépote et ça s'installe en deux commandes !
Et si vous êtes sur PC plutôt que sur Mac, j'ai écrit la suite sur
Lemonade SDK
, l'équivalent côté AMD qui tape dans le NPU Ryzen AI.
Vous ne le savez peut-être pas mais votre serveur Linux embarque plusieurs milliers de modules kernel et pourtant, il n'en utilise que quelques centaines à peine. Tout le reste ça prend la poussière et ça peut vous exposer à des problèmes de sécurité. Hé bien c'est exactement à ces modules inutiles que Jasper Nuyens, le fondateur de Linux Belgium, vient s'attaquer avec son outil
ModuleJail
.
Ce script lit /proc/modules pour savoir ce qui tourne vraiment sur votre machine, et considère ensuite cet ensemble comme étant intouchable. Par contre, pour tout le reste il ajoute une ligne install <module> /bin/true dans /etc/modprobe.d/modulejail-blacklist.conf.
Comme ça si un jour quelque chose essaie de charger un de ces modules endormis, c'est modprobe qui exécutera /bin/true à la place... et il ne se passe rien !!
C'est malin, hein ? Vous pouvez installer ModuleJail via le script dispo sur la page Github ou grâce aux paquets .deb et .rpm si vous préférez. Et ensuite, pour vérifier que c'est bien en place, un petit modprobe -n -v module_banni devrait vous répondre install /bin/true.
En tout cas, je trouve que ModuleJail tombe très bien parce que la chasse aux failles kernel est clairement en train de changer d'échelle. Je pense notamment à tous ces outils de scan assistés par IA qui débusquent à la chaine des bugs d'élévation de privilèges planqués dans le code depuis des années.
Le script propose 3 profils via le flag -p, minimal pour le strict nécessaire, conservative par défaut (serveur classique plus drivers VM courants) et desktop qui garde WiFi, Bluetooth, audio et vidéo. Vous pouvez aussi ajouter votre propre whitelist.
Et la règle d'or non négociable, c'est de le lancer quand la machine est dans un état stable, avec tous les services démarrés, et tous les disques montés. Car oui, ModuleJail ne devine rien, mais se contente de photographier ce qui tourne à l'instant T. Donc sur un système à moitié démarré, ce serait un peu couillon qu'il bannisse un module dont vous aurez besoin plus tard.
Après pour tout ce qui est compilé en dur dans le kernel (le fameux =y de la config) ça reste là, donc une faille dans le cœur du noyau façon
Dirty Cow
, ça n'y changera rien du tout. Et si vous branchez une webcam six mois après, son module sera déjà banni donc faudra pas oublier de retirer sa ligne du fichier ou relancer le script avec une whitelist, car un simple modprobe ne suffira pas !
Donc c'est pas forcement le pied pour un Linux Desktop mais pour un parc de serveurs en prod qui ne bougent pas, c'est une petite couche de sécurité en plus.
C'est le slogan de Menlo Research, et pour une fois c'est pas du flan. En effet, leur Asimov v1 est un humanoïde de 1,20 m et 35 kg, entièrement open source ! Tout est fourni gratuitement donc, les plans de la mécanique, les schémas électriques, le modèle de simulation, ainsi que le code embarqué.
Vous avez donc la CAO complète, la nomenclature des pièces, le modèle MuJoCo pour simuler avant même de souder, et le firmware. Ensuite, y'a 2 façons de l'avoir : Soit
le kit DIY
(499 dollars d'acompte, puis environ 15 000 dollars au final, livré cet été), soit vous sortez la
nomenclature complète
et le manuel d'assemblage, et vous sourcez chaque pièce à la main. Ça peut faire un beau projet si vous avez un peu de blé mais surtout des compétences en électronique et du temps !
C'est vrai qu'en général, 1 robot "open source" sur 10, c'est un README qui se la raconte avec 3 STL et rien d'autre derrière, mais là je vous promets, c'est du solide. En janvier dernier, Asimov c'était juste une paire de jambes avec 12 degrés de liberté et basta. Et nous voilà quelques mois plus tard avec un humanoïde complet composé de 25 actionneurs (plus deux orteils passifs sur ressort pour le contact au sol), des bras qui lèvent 15 kg chacun, une tête avec caméra et micros, et un haut-parleur dans le torse pour causer.
Asimov v1, le robot humanoïde open source de Menlo Research
Et côté tripes, c'est du sérieux également avec 2 cerveaux à bord, un Raspberry Pi 5 pour le réseau et le média, et un Radxa CM5 pour le contrôle moteur en temps réel. Des bus CAN charrient ensuite les ordres dans tout le squelette. Niveau matériaux, c'est de l'alu 7075 pour les pièces qui encaissent, du nylon PA12 fritté pour le reste. Et la licence matérielle c'est du
CERN-OHL-S-2.0
(je ne la connaissais pas celle-là), et de la GPL-2.0 pour le soft. Donc on est sur du vrai open hardware copyleft !
Maintenant, Menlo a baptisé son kit "Here Be Dragons". Pour ceux qui n'auraient pas la ref, c'est la mention qu'on collait sur les vieilles cartes médiévales pour dire "ici, terrain inconnu, c'est à vos risques et périls".
Et c'est pas un hasard puisque vous devrez compter
50 à 100 heures
rien que pour passer du carton de pièces à un robot qui s'allume proprement et sans danger. Attendez, pas pour le faire marcher, hein, juste pour l'allumage. Et utiliser votre imprimante 3D du dimanche pour les pièces porteuses, oubliez. Faudra passer par de l'alu usiné.
En effet, le plastique risque d'avoir du jeu et foutra en l'air les calculs du contrôleur, donc au mieux le robot marchera mal, au pire il viendra vous buter dans votre sommeil. Ensuite, le reste s'imprime, mais en nylon industriel. Et je vous passe la prise de tête avec le câblage des bus CAN et autres petites surprises... Un bidouilleur prévenu en vaut deux !
Du coup, entre lâcher 15 000 balles pour le kit clé en main et tout sourcer soi-même, perso si j'avais la thune (et l'usage d'un robot), j'opterais pour le kit. Mais si vous avez un atelier, une fraiseuse CNC et la patience d'un moine, la version DIY revient sans doute moins cher. Bref, chacun son délire.
Reste la vraie question que vous vous posez surement (ou pas) : Ça vaut quoi face à la concurrence ?
Hé bien un Unitree G1 tourne autour de 16 000 dollars, soit à peu près le même tarif. Sauf que chez Unitree, les plans du bestiau restent propriétaires et je vous parle pas du soft qui balance tout chez nos amis Chinois.
Alors qu'avec Asimov, vous êtes le propriétaire du robot jusqu'à la dernière vis. L'idée de Menlo c'est d'accélérer l'itération en ouvrant complètement leur robot afin que tout ça s'améliore dans un espèce de cercle vertueux. Et surtout les labos et les geeks de tout poil pourront avoir leur robot bien à eux. Sans ça, sur le marché ce sera uniquement Robot Apple, Robot Google, Robot Tesla ou NoName Chinois et voilà... Ce serait dommage quand même, je trouve.
Bref, si vous avez 15 000 balles, 100 heures devant vous et l'âme d'un bidouilleur, le bipède vous attend sur GitHub. Et les autres comme moi, regarderont ce dépôt en bavant... ce qui est déjà pas mal ^^.
Cult of the Dead Cow
, un des plus vieux collectifs hacktivistes encore en activité, ne se contente pas que de balancer des manifestes politiques depuis 1984. Ils codent. Et leur dernier bébé en date s'appelle
Veilid
, et c'est un framework P2P qui veut faire à vos apps ce que Tor a fait à votre navigateur.
Histoire de vous expliquer, vous prenez Veilid, vous l'intégrez dans votre app mobile ou web, et d'un coup tout votre trafic passe par un réseau pair-à-pair (P2P) chiffré de bout en bout. Cela veut dire qu'il n'y a pas de serveur central qui stocke vos messages.
Concernant votre IP, celle-ci n'apparaît alors plus au niveau applicatif (le routage privé l'obfusque entre pairs), et chaque nœud est identifié par une clé publique Ed25519 256-bit. Donc autant dire un truc carrément impossible à brute-force.
Le projet a été annoncé à
DEF CON 31 en août 2023
par Christien "DilDog" Rioux et Katelyn "Medus4" Bowden, 2 membres historiques de cDc, et près de trois ans plus tard, ça continue d'évoluer toujours à un rythme régulier.
L'idée technique vous la connaissez si vous avez déjà touché à du décentralisé : Une table de hachage distribuée (DHT, en fait un annuaire éclaté entre tous les nœuds du réseau) gère le routage, chaque nœud relaie du trafic chiffré qu'il ne peut pas lire, et les pairs s'échangent des données sans jamais révéler leur IP.
Perso, c'est l'approche qui me semble vachement plus saine pour faire du social sans Mark Zuckerberg dans la boucle. C'est dans le même esprit que Tor et qu'
IPFS
, sauf que Veilid est pensé dès le départ pour les développeurs d'applications. Donc c'est pas fait pour anonymiser de la navigation web ou stocker des fichiers. C'est un Tor des applications si vous préférez...
Le framework est codé en Rust avec des bindings Flutter et Dart pour le mobile ainsi qu'une cible WebAssembly pour le navigateur. Vous pouvez donc carrément déployer une app Veilid sur Linux, macOS, Windows, Android, iOS, et même directement dans Chrome ou Firefox via WASM.
Le code, lui, est découpé en plusieurs composants : veilid-core pour le moteur, veilid-tools pour les utilitaires, veilid-flutter pour le mobile, veilid-wasm pour le navigateur et veilid-server qu'on installe sur un VPS Debian ou Fedora pour faire tourner un nœud public. Voilà, et le tout est sous licence Mozilla Public License 2.0, donc copyleft mais compatible si vous y ajoutez du code propriétaire par dessus.
L'app phare qui tourne déjà sur ce framework, c'est
VeilidChat
, une messagerie type Signal mais sans aucun serveur, sans numéro de téléphone et sans annuaire centralisé. Vous échangez votre clé publique avec un pote, et hop, c'est parti.
Si ça vous dit d'y jeter un oeil, sachez que le code de Veilid n'est pas sur GitHub mais sur
GitLab
. Après c'est encore assez nouveau, ce qui veut dire que ça bouge beaucoup de release en release. Donc si vous voulez coder votre prochaine app par dessus ce framework, va falloir vous accrocher car ça cassera souvent.
Mais si vous codez du décentralisé et que vous en avez franchement marre de bricoler libp2p à coup de colle forte Python, Veilid mérite un sérieux coup d'œil. Et même si vous codez pas, gardez l'œil sur VeilidChat car le jour où une appli grand public sortira là-dessus, ça va vraiment envoyer du lourd.
Vous vous souvenez de l'encoche des MacBook Pro et autres Air d'Apple ? Mais siiii, celle qu'on avait tous trouvée bien moche en 2022, au point que je vous avais pondu
un article entier pour la faire disparaître
! Hé bien 4 ans plus tard, sk-ruban a décidé de lui donner une vraie utilité avec
notchi
qui transforme proprement cette encoche maudite en un compagnon fait de pixel-art et d'amour qui réagit en temps réel à votre Claude Code.
La boucle est bouclée, mes amis !
Une fois installée, l'app détecte les événements de votre session Claude Code via les
hooks officiels
car ce sont eux qui balancent les "events" sur un socket Unix local qui sont ensuite parsés en temps réel afin d'animer les sprites logés dans le creux de votre encoche.
Cette mascotte a cinq états bien distincts. Elle se balade en mode idle quand vous bricolez à côté, elle s'agite quand Claude réfléchit, elle pique un roupillon en cas de pause prolongée, elle se concentre quand le contexte se compacte, et elle vous fait les gros yeux quand l'IA attend une validation.
Ça bosse fort !
Un clic sur l'encoche et le panneau s'étend pour afficher le feed des événements, votre temps de session, et le quota d'usage restant.
L'option d'analyse de sentiment est également très sympa. Si vous lui fournissez une clé API Anthropic, l'app analysera alors vos prompts pour faire varier l'humeur de la mascotte entre joyeux, triste, neutre ou pleurnichard. À noter quand même que chaque prompt déclenche un appel API facturé sur votre compte Anthropic, donc à activer en conscience si vous bombardez Claude toute la journée et que vous êtes pété de thunes. Ce dont je ne doute pas un instant !!
Les options de Notchi
Et pour ceux qui jonglent avec plusieurs instances de Claude Code, les sessions concurrentes sont également supportées avec un sprite individuel par session, histoire d'éviter la confusion quand vous lancez 3 agents en parallèle.
Sk-ruban s'est inspiré de Claude Island et Readout (deux autres projets qui détournent l'encoche), et les sprites sont dessinés sur Aseprite. C'est un peu dans le même esprit que
Peon Ping
qui balance des sons de Warcraft à chaque action de votre agent, mais avec un aspect visuel ludique plutôt que sonore. Il y a même déjà
un portage Windows
réalisé par AptatoX pour ceux qui ne sont pas sur Mac.
Au niveau prérequis, comptez macOS 15 Sequoia minimum et un MacBook avec une vraie encoche, ce qui exclut les MacBook Air sans notch et les MBP d'avant la refonte 14/16 pouces. Le projet est sous licence GPL-3.0 et l'install se fait par Homebrew avec brew install --cask notchi, ou en DMG direct depuis les releases.
Et un grand merci à
Camille Roux
pour le partage !
Si vous avez payé une agence pour "optimiser votre site pour l'IA" ces derniers mois, asseyez-vous bien confortablement car Google a publié son
guide officiel
sur le sujet, et le résumé tient en une phrase, le SEO pour l'IA c'est du SEO. Voilà... Tout ce qui est hacks GEO, c'est direction la poubelle en tout cas pour Google !
Le doc est sorti le 15 mai sur Search Central, et il met les pieds dans le plat direct. Google y explique que ses fonctionnalités IA, les AI Overviews (les fameux résumés générés en haut des résultats) et le mode IA, ne tournent pas sur un moteur à part. Elles piochent tout simplement dans l'index normal, avec le classement habituel. En gros, y'a pas de porte dérobée réservée aux plus malins malgré ce que les auto-proclamés experts GEO peuvent dire.
Le guide officiel Google, mis en ligne le 15 mai 2026
Ce qui est marrant, c'est que Google a surtout placé dans ce doc une section "mythbusting" qui va faire mal à pas mal de monde. Car oui les amis, pas besoin de fichier llms.txt, pas besoin de balisage spécial, pas besoin de découper votre contenu en petits morceaux pour aider les robots de Mister Google.
Et voilà comment toute une industrie de consultants qui vendait du llms.txt à prix d'or vient de se prendre un mur. Snif...
D'ailleurs, le truc rigolo avec le llms.txt, c'est son histoire. Ce fichier a été proposé en septembre 2024 par le co-fondateur de Fast.ai, et presque deux ans plus tard, ni Google, ni OpenAI, ni Anthropic ne vont vraiment le récupérer sur votre serveur. L'adoption reste donc hyper marginale, genre 6% des gros sites et ça n'est jamais devenu un vrai standard. Vous pouvez donc carrément supprimer le vôtre, ça ne changera strictement rien !
Alors c'est quoi la vraie recette ?
Hé bien du contenu "non-commodity", dit Google. En clair, des trucs que personne d'autre n'a écrits... Ils veulent du vécu et pas du réchauffé. Leur exemple est d'ailleurs très parlant... Un article du style "7 conseils pour acheter sa première maison", c'est de la soupe que tout le monde recopie. Alors que "Pourquoi on a zappé l'inspection et économisé, retour sur la canalisation d'égout", ça c'est du vécu qui sent bon le terroir et la sueur, et c'est ça que l'IA va citer !! C'est exactement
ce que je raconte depuis des années
.
En vrai, le boulot c'est surtout de revenir aux bases du SEO, et pas besoin d'outils payants dans cette équation mais juste du temps et du contenu honnête et humain. D'abord, faut vérifier que vos pages sont indexables et crawlables, et ça la Search Console vous le dit en deux clics.
Ensuite, arrêtez de générer 40 pages quasi identiques pour chaque variation de mot-clé, car Google appelle ça de l'abus de contenu à grande échelle et ça vous flinguera votre référencement ! Et n'oubliez pas que vous écrivez pour des humains, avec des titres et des paragraphes, et pas pour un parseur à la con.
Le seul vrai piège après, c'est l'éternel site full JavaScript des startupeurs d'école de commerce (ou des vibe-coders maintenant...). Là encore Google prévient que ça ne passera pas.
Après le hic c'est que les
AI Overviews
répondent direct dans la page de résultats, du coup le
taux de clics vers votre site s'effondre
. Et voilà comment le client repart sans jamais entrer... Plusieurs études indépendantes parlent même d'un taux de clic qui peut chuter de moitié quand un résumé IA s'affiche en haut. Ahrefs par exemple a mesuré près de 60% de clics en moins sur la position numéro un, Pew tourne autour de 47% et comme d'hab, avec son guide, Google vous dit "faites du bon contenu", mais ne vous promet jamais le trafic qui va avec. Faut donc bien en avoir conscience avant de se lancer !
Le guide glisse aussi un mot sur les agents IA qui visitent votre site tout seuls, lisent vos captures d'écran, votre DOM et votre arbre d'accessibilité pour comparer des produits ou réserver une table. D'ailleurs si ce sujet vous parle, y'a un
scanner pour tester si votre site est prêt pour les agents IA
.
Après moi ce que je retiens de tout ce bordel, c'est que Google vient surtout de couper l'herbe sous le pied à tous les vendeurs de poudre de perlimpinpin "AEO" et "GEO". Ces acronymes, comme l'écrit Google noir sur blanc dans son rapport, ce sont juste des mots et du marketing pour les pigeons. Le vrai métier derrière reste le SEO et basta !!
Après si vraiment vous voulez bosser votre visibilité pour les moteurs IA comme Perplexity, j'avais détaillé
les vraies techniques
, et spoiler, ça ressemble quand même beaucoup à du bon vieux contenu honnête qu'on fait à l'ancienne depuis que le web est web...
Bref, avant de lâcher du fric pour du GEO,
allez lire le guide
. C'est gratuit, et au moins ça dit la vérité.
Je me baladais sur les réseaux sociaux (ouais, c'est pas bien, je sais) quand je suis tombé sur un post X en reco avec un tuto Youtube où un mec explique comment gagner un petit peu d'ethers chaque jour. Évidemment, je flaire l'arnaque parce que dans la vie y'a que 3 façons de devenir riche : 1/ Monter sa boite 2/ Être né dans une famille déjà fortunée 3/ Ou se faire adopter par un vieux riche sans enfant afin de faire une magnifique captation d'héritage.
Mais ce que je voulais surtout c'est comprendre comment cette arnaque fonctionnait. Alors j'ai épluché un peut tout ça et j'en profite pour vous expliquer.
La vidéo, je vous la résume parce que franchement elle ne mérite pas un clic. Un type qui se fait appeler Josh Alex, sourire ultra-bright, vous vend l'idée qu'un "outil IA" peut sortir 1700 à 2000 dollars par jour en mode pilote automatique.
Le pitch, c'est qu'il a demandé à ChatGPT de lui pondre le code d'un bot de "sniping" sur Ethereum (c'est de l'arbitrage... en gros, passer devant les autres au bon moment pour gratter quelques dollars sur le mouvement du cours de la cryptomonnaie). Vous copiez ce code dans Remix (un vrai éditeur de smart contracts, parfaitement légitime, et c'est tout le problème), vous compilez en Solidity, vous déployez avec MetaMask, et hop, vous "financez le contrat" avec vos propres ethers.
Et plus vous mettez, plus vous gagnez, qu'il nous explique... Faut savoir que dans ce type d'arnaques, on réclame souvent un demi-ether minimum, genre 1500 - 2000 balles selon le cours du moment, soi-disant pour couvrir les frais de gas. Vous lancez ensuite le bot, vous attendez 3 heures, et magie magie : +30% de profit affiché. Vous cliquez alors sur Withdraw pour retirer les sous et l'argent vous revient avec le bénéf. Ensuite, la vidéo se termine sur deux phrases qui puent l'arnaque, je trouve : "je vais bientôt supprimer cette vidéo, c'est une chaîne privée" et "contactez-moi sur Telegram".
Et voilà...
Mais alors du coup, qu'est-ce qui se passe réellement ?
Hé bien cette combine porte un nom, elle est documentée, et elle a fait très mal. Les chercheurs de
SentinelLABS
ont disséqué toute une famille de ces "drainers Ethereum" qui se font passer pour des bots d'arbitrage (les vrais bots MEV existent et sont légitime, justement ce qui rend l'arnaque crédible).
Par exemple, une autre vidéo de la même série, intitulée "How to Create Passive Income MEV Bot on Ethereum" (pas exactement celle que j'ai vue, mais le même mécanisme au détail près), a aspiré près de 245 ethers à des victimes. Au cours de l'époque, ça représentait environ 900 000 dollars. Pas mal hein, pour un "tuto gratuit" sur YouTube ! D'autres campagnes du même genre ont siphonné 7 ETH par-ci, 4 ETH par-là et ces vidéos sont souvent générée par IA, avec la voix robotique à 2 balles, les expressions faciales saccadées, les lèvres désynchronisées et j'en passe...
Maintenant, le cœur de cette arnaque c'est que le code que vous collez dans Remix contient en fait une adresse de portefeuille cachée / obfusquée, qui est celle de l'escroc. Elle n'est pas écrite en clair, sinon n'importe qui la verrait mais est reconstituée lors de l'exécution du code, soit en faisant un XOR entre deux constantes anodines (souvent nommées un truc rassurant genre DexRouter et factory), soit en recollant des morceaux de texte, soit en tronquant un énorme nombre. En clair, l'adresse du voleur est coupée en deux bouts d'apparence inoffensive, planqués à deux endroits différents du code, et recollée seulement au moment où le contrat tourne.
Alors quand le mec dans la vidéo vous dit "regardez les lignes 13 et 14, ce sont vos adresses pour recevoir les tokens WETH", c'est de la diversion pure. Il vous donne tout simplement un os à ronger pour que vous vous sentiez rassuré, pendant que la vraie adresse est planquée ailleurs dans le code.
Et là, le piège se referme car au moment où vous financez le contrat et cliquez sur Start, vos ethers partent directement dans le portefeuille de l'escroc. Pire, SentinelLABS a également relevé un mécanisme de secours qui permet à l'attaquant de vider le contrat même si vous ne cliquez jamais sur Start.
Le "+30% de profit" que vous voyez à l'écran ? Bah c'est du flan... de la poudre de perlimpinpin comme dirait l'autre.... Au mieux c'est un faux solde renvoyé par le contrat, au pire c'est carrément du montage vidéo. D'ailleurs, un contrat déployé tout seul ne peut même pas "sniper" la mempool donc techniquement, ça tient pas car ce genre de chose demande un bot externe qui surveille les transactions en attente. Le contrat seul ne fait rien d'autre que transférer votre argent en fait... C'est juste un siphon avec une jolie interface, rien de plus !
Ce qui rend ce truc redoutable, c'est la psychologie derrière. Remix est un outil réputé, donc votre cerveau associe "outil sérieux" à "code sérieux". Et comme vous déployez le contrat vous-même, il vous semble être le vôtre.
On vous donne aussi cette mini-tâche de "vérification" bidon pour endormir votre méfiance et surtout on vous répète "pas besoin de savoir coder", ce qui veut dire en réalité "surtout ne lisez pas ce que vous collez".
C'est ce genre de phrase-là qui devrait déclencher l'alerte rouge dans votre cerveau ! Sans oublier que le tout est saupoudré de hype IA pour faire moderne... Bref, c'est du grand n'importe quoi, mais ça marche à fond la caisse. Si vous voulez voir comment des malwares se cachent carrément dans la blockchain elle-même, j'avais aussi décortiqué
ce que fait la Corée du Nord avec la blockchain
. Le mécanisme est différent, mais c'est le même esprit à savoir détourner une techno légitime pour piéger les gens.
Voilà, alors retenez les règles de base, parce qu'elles valent pour cette arnaque comme pour les mille autres qui sortiront demain. Argent facile et passif : si c'est automatique, sans effort et garanti, c'est une arnaque dans la totalité des cas. Et surtout, la vraie question à se poser est toujours la même : Si ce bot rapportait vraiment 2000 dollars par jour, pourquoi un inconnu vous le filerait gratuitement au lieu de s'enrichir tranquillement dans son coin ? Personne n'offre une machine à billets sans contrepartie !
Puis y'a l'urgence : "je supprime la vidéo bientôt", "offre gratuite aujourd'hui", "dépêchez-vous". Ce compte à rebours vise à court-circuiter votre sens critique pour vous empêcher de réfléchir ou de vérifier. C'est un peu ce que font aussi les escrocs au téléphone quand ils vous disent que votre compte bancaire va être bloqué dans 10 min et que vous allez tout perdre...
Et puis filer de l'argent avant de toucher le moindre gain c'est louche aussi ! Sans oublier le fait qu'on vous pousse vers Telegram ou des DM privés, histoire de laisser le moins de traces et de recours possible.
Quand au fameux "Pas besoin de coder", sur un truc qui touche à votre argent, c'est le drapeau rouge ultime !!! Ne déployez jamais, jamais, jamais du code financier sans le comprendre parfaitement ou le faire auditer par quelqu'un de confiance.
Et si vous vous êtes déjà fait avoir ?
À vrai dire, une fois la transaction confirmée sur la blockchain, récupérer l'argent est en pratique quasi impossible, sauf gel rapide côté plateforme ou intervention judiciaire. Mais bon, c'est pas une raison non plus pour rester les bras croisés.
Par exemple, si vous avez signé des autorisations (avec Metamask par exemple) que vous ne compreniez pas, considérez le portefeuille comme grillé et transférez rapidement ce qu'il vous reste vers un portefeuille tout neuf. Vérifiez et révoquez les approbations de tokens accordées au contrat (avec un outil de type revoke.cash), en sachant évidemment que ça ne récupèrera pas les ethers déjà partis. Ça coupe juste une éventuelle ponction qui arriverait plus tard.
Et surtout, gardez les preuves comme les hash de transaction et les adresses, signalez la chaîne YouTube et le compte Telegram, puis déposez un signalement sur cybermalveillance.gouv.fr ou Pharos. Et prévenez les gens autour de vous... c'est exactement le même réflexe à avoir que face à
l'arnaque au QR code piégé
, une fois le mécanisme compris, on devient beaucoup plus dur à berner.
Bref, ce genre d'escroquerie ne meurt jamais vraiment... elle change juste de costume. Hier l'arbitrage secret, aujourd'hui c'est l'IA qui va vous rendre riche... Le plus important c'est de garder votre cerveau allumé... ça c'est gratuit et ça rapporte vraiment.
Branislav Đalić, un dev serbe basé à Belgrade, vient de balancer un projet plutôt original baptisé
GitLike
. Il s'agit d'un GitHub décentralisé qui stocke vos repos sur
IPFS
et remplace le mot de passe par votre clé Ethereum (votre wallet quoi...).
Vous connectez votre wallet via SIWE (le standard EIP-4361, signature dans MetaMask ou WalletConnect), vous créez un repo, et hop, chaque commit, chaque fichier, chaque arbre devient un objet IPFS adressé par son CID. Tout pareil que Git côté usage, sauf que derrière y'a pas de serveur GitHub mais un simple Worker Cloudflare qui orchestre Pinata ou Filebase pour pinner vos données.
Côté install, la doc propose tout simplement de faire un npm install -g gitlike avec ensuite l'utiliser avec les commandes Git habituelles (init, clone, push, pull, branch), sauf que le package n'est pas encore publié sur npm public pour l'instant. Du coup, faudra patienter ou aller chercher le code directement dans le repo GitHub si vous voulez bricoler dès aujourd'hui.
La doc officielle mais l'install npm marche pas.
L'architecture tient en 3 étages bien séparés. Votre navigateur s'occupe de l'interface et de la signature avec le wallet, un petit serveur Cloudflare joue les videurs en backend (qui a le droit d'écrire, dans quel ordre, à quelle vitesse), et IPFS stocke tout le code en mode décentralisé via Pinata ou Filebase.
Et si vos repos doivent rester privés, vous pouvez activer un chiffrement qui se fait directement dans votre navigateur, comme ça personne d'autre ne lit vos fichiers en clair. En gros, votre onglet de navigateur fait office de vitrine, le Worker joue le mec de la sécu, et IPFS sert de coffre-fort distribué.
Le truc cool, c'est que GitLike peut importer votre code directement depuis GitHub ou GitLab, donc migrer un projet existant ne prend que quelques clics ! Et vous retrouvez tout le confort moderne, à savoir les pull requests avec gestion des conflits, des règles de protection sur les branches sensibles, et même un système pour déléguer l'écriture à un agent IA avec un périmètre limité dans le temps et l'espace (genre, commit uniquement sur telle branche, et seulement pendant 24h).
Sympa, donc, pour vibe coder avec un agent 100% autonome sans pour autant lui filer toutes vos clés et qu'il ne détruise tout dans une apocalypse nucléaire (Quoi, j'en fais trop ?)
Après même si l'idée semble sympa, je trouve que ça déplace le risque plutôt que de le faire disparaître. Parce que si vous paumez votre wallet, vous perdez l'accès en écriture (et possiblement en lecture si c'est chiffré) à tous vos repos, et y'a plus qu'à recommencer. Donc sauvegarder votre seed phrase (les 12 ou 24 mots de récupération du wallet, vous savez) est donc critique !
Côté concurrence, vous trouverez également
Radicle
qui fonctionne en peer-to-peer pur (mais demande un daemon local) ou l'ancien Mango (Ethereum + IPFS, mais plus trop maintenu). GitLike, lui, mise tout sur le navigateur et votre wallet, donc c'est plus simple !
Après c'est jeune et faut voir ça plus comme un proof of concept solide qu'un GitHub-killer. Mais ça tient bien la route et je trouve l'idée d'un Git contrôlé par un wallet ethereum plutôt classe. C'est peut-être ça le vrai web3 ;)))


















































{kind=link}