Le code source perdu de Sierra retrouvé par miracle !

Il y a longtemps, à l’époque héroïque des jeux d’aventure Sierra, au milieu des années 80, un jeu venait juste de sortir : Space Quest II. Des milliers de joueurs s’empressent alors de se le procurer (en disquettes) pour partir dans de nouvelles aventures spatiales déjantées. Jusque là, rien d’anormal.
Sauf que… en réalité ces disquettes de Space Quest II (SQ2 pour les intimes) cachaient un secret incroyable que personne n’a décelé jusqu’à aujourd’hui ! En effet, sur la plupart des disquettes du jeu (versions 2.0D et 2.0F), les dev de Sierra avaient accidentellement laissé traîner près de 70% du code source original de leur moteur de jeu AGI (Adventure Game Interpreter) !
Car oui, sur ces disquettes qui tournaient sur tous les PC de la planète, il y avait non seulement le jeu mais aussi la majeure partie du code source normalement tenu secret qui faisait tourner tous leurs jeux depuis le premier King’s Quest !
Mais comment un truc pareil a pu arriver ?
Eh bien tout simplement à cause d’une petite erreur de manipulation lors de la préparation des disquettes master pour la duplication. À l’époque, le processus de fabrication des disquettes impliquait de copier l’intégralité des secteurs de la disquette master, y compris l’espace libre. Sauf que, manque de bol, les disquettes master utilisées pour SQ2 contenaient auparavant le code source AGI. Les fichiers avaient bien été effacés, mais les données étaient toujours présentes dans les secteurs non utilisés. Et avec la duplication, hop, le code source s’est retrouvé à l’insu de Sierra sur les disquettes de dizaines de milliers de joueurs !

Une simple commande DIR sur les répertoires de la disquette ne révélait rien d’anormal. Les fichiers principaux du jeu, comme PICDIR, LOGDIR, VIEWDIR, SNDDIR, VOL.0 et VOL.1, étaient bien daté de mars 1988. Cependant, l’espace libre sur la disquette 1 de la version 2.0D contenait des fragments de code source, issus des fichiers effacés mais non complètement supprimés et découvert simplement avec l’aide d’un éditeur hexadécimal.
En furetant dans les recoins des disquettes, Lance Ewing a pu retrouver 93 fichiers source éparpillés dans les secteurs oubliés ! La majeure partie de ces fichiers sont écrits en langage C, le reste est composé d’un peu d’assembleur et de scripts batch DOS. Une véritable caverne d’Ali Baba pour les passionnés de code rétro.
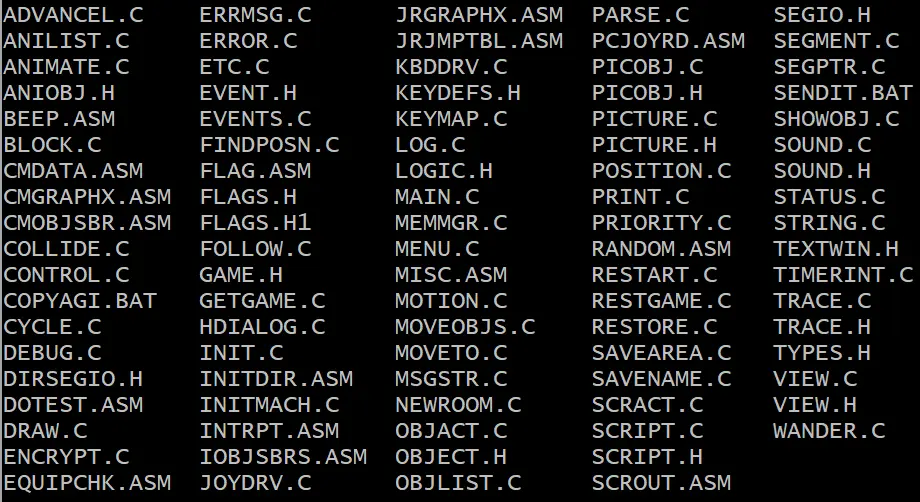
Le plus fou dans cette affaire, c’est que certains de ces fichiers C contenaient même des commentaires et un historique de modifications ultra détaillés ! On peut donc y voir apparaître les noms des développeurs, les dates, les descriptions de chaque changement…etc. C’est un véritable trésor archéologique pour comprendre comment ces pionniers du jeu d’aventure bossaient à l’époque.
On apprend ainsi que le code AGI a été principalement développé par Jeff Stephenson et Chris Iden entre 1985 et 1987, avec les dernières modifs début 88. On y voit leur labeur acharné pour peaufiner sans cesse le code, optimiser, débugger, ajouter de nouvelles fonctionnalités. Un boulot de fou qui a pavé la voie à tous les chefs d’œuvre d’aventure Sierra : King’s Quest, Larry, Space Quest, Police Quest… toutes ces légendes du genre sont passées par cette machinerie logicielle brillamment huilée !
Imaginez un peu si ce code source d’AGI s’était réellement retrouvé entre de mauvaises mains à l’époque, genre un concurrent peu scrupuleux… Celui-ci aurait pu le récupérer discrètement et l’utiliser dans ses propres jeux, en piquant toutes les idées révolutionnaires de Sierra sans aucune honte (enfin un peu quand même). Heureusement ce petit incident de sécurité est resté sans conséquence. Un miracle quand on y pense !
Lance a eu la bonne idée de partager toutes ses trouvailles dans un dépôt GitHub dédié donc avis aux amateurs de code old school, c’est une mine d’or à explorer ! En plus, il a développé son propre interpréteur AGI moderne basé sur ce code source original, pour faire tourner tous ces classiques directement dans le navigateur. Le dénommé AGILE, un projet aussi fou qu’admirable que vous pouvez tester avec de vrais jeux ici.
Et si vous aussi, vous avez de vieilles disquettes qui traînent, ça vaut peut être le coup d’y jeter un œil avec un éditeur hexa, car on ne sait jamais, elles ont peut-être été mal effacées avant le passage pour le master et vous pourriez y découvrir quelques trucs marrants.