Vous conduisez tranquillement votre bagnole, en mode pépère. Quand tout à coup, vous recevez un mail de votre assurance : « Cher M. Kéké, au vu de votre conduite dangereuse, nous devons augmenter votre prime de 150%».
WTF ?!
Vous n’avez eu aucun accident et respectez toujours les limitations…enfin presque… Mais comment votre assureur est-il au courant de votre dernière petite pointe à 135 km/h sur l’autoroute pendant que tout le monde dormait dans la voiture ?
La réponse est simple : votre voiture est une balance ! C’est ce qu’on appelle communément les « boîtes noires », ces petites boîtes qui enregistrent tous les paramètres de conduite : vitesse, accélérations, freinages, trajets…un vrai mouchard numérique. De nombreux constructeurs ont adopté cette technologie, soi-disant pour analyser les accidents ou améliorer la sécurité mais la plupart s’en servent surtout pour faire leur beurre en revendant les données à des tiers, comme les assurances donc.
Votre vie privée passe alors à la trappe et votre portefeuille en prend un coup !
Parmi les plus gros cafteurs, on retrouve General Motors. Le géant américain de l’automobile vient de se faire gauler dans un scandale retentissant. Comme le révèle le New York Times dans une enquête édifiante, GM a espionné des millions de conducteurs pendant des années via son système OnStar, sans leur consentement.
Concrètement, ils ont modifié en catimini leurs conditions d’utilisation pour se donner le droit de collecter un max de données de conduite et de géolocalisation, de manière continue, tout ça planqué au fin fond des CGU en police 2 ! Et le pire, c’est que GM revendait ces précieuses données à des courtiers comme Verisk Analytics, qui les refilaient ensuite aux assureurs pour profiler les conducteurs à leur insu et augmenter le tarif de leur assurance. Un business juteux sur le dos des clients, qui se retrouvent pris en otage.
Après ces révélations fracassantes, GM a été contraint de mettre fin en urgence à ces pratiques déloyales et fait désormais profil bas mais le mal est fait et la confiance durablement rompue. Certains clients furieux ont même lancé un recours collectif pour se faire indemniser. Je sens qu’ils vont casquer sévère !
Alors que faire pour se prémunir de ça ? Déjà, lisez les CGU avant d’accepter quoi que ce soit ! Je sais c’est chiant mais c’est important pour savoir à quelle sauce vous allez être mangés. Ensuite, désactivez toutes les fonctions de suivi que vous pouvez dans les réglages.
Ensuite si votre véhicule est équipé d’un système OnStar ou équivalent qui envoie en permanence des data sans fil, vous pouvez essayer de désactiver tout ça dans les paramètres voire de le débrancher physiquement si c’est possible mais attention à ne pas faire n’importe quoi. Renseignez vous bien avant.
L’espionnage des conducteurs par les boîtes noires est une dérive très préoccupante de l’industrie automobile moderne ultra-connectée et on en revient toujours au même débat : la technologie doit servir les gens, pas les asservir en marchandisant leur vie privée !
Alors soyez vigilants et n’hésitez pas à défendre vos droits.
Si vous êtes fan de partage de fichiers P2P, ça devrait vous plaire. En effet, des chercheurs de l’université de technologie de Delft qui sont derrière le projet Tribler, ont développé un moteur de recherche torrent complètement décentralisé et alimenté par l’intelligence artificielle.
Bizarre non ?
Alors attention, on n’est pas encore au niveau de Google Search mais l’idée est de combiner les deux technologies : les modèles de langage (les fameux LLM) et la recherche décentralisée. Le principe ensuite, c’est que chaque pair du réseau héberge une partie du modèle de langage, qui peut alors être utilisé pour trouver du contenu à partir de requêtes en langage naturel.
Concrètement, le framework De-DSI (Decentralized Differentiable Search Index) utilise des modèles de langage décentralisés stockés par les pairs et chaque utilisateur peut ainsi contribuer à l’entraînement du modèle.
Côté recherche, les infos sont réparties sur plusieurs pairs, sans besoin de serveurs centraux, comma ça, quand vous lancez une requête, le système d’IA va chercher les meilleurs résultats en fonction des données partagées par les pairs. Chaque pair étant spécialisé dans un sous-ensemble d’infos, ce qui permet aux autres de récupérer le contenu le plus pertinent.
Les grands principes derrière tout ça :
La décentralisation : vous stockez et partagez vos propres données, sans passer par un serveur central
L’apprentissage automatique : les modèles de langage sont entraînés à partir des infos partagées par les pairs
La spécialisation : chaque pair gère un type d’infos, pour fournir les résultats les plus adaptés
Au final, ça donne une IA décentralisée et résiliente, capable de répondre à vos recherches sans serveurs centraux.
Genre, vous pourriez lui demander un truc du style « trouve-moi un lien magnet pour le documentaire sur The Pirate Bay », et hop, le système vous renverrait direct le bon lien, sans même citer le nom du doc. Ou encore « C’est quoi déjà l’adresse Bitcoin de Wikileaks ? ».
Bon pour l’instant, c’est encore un proof of concept et les chercheurs ont testé ça sur un petit dataset avec des URLs YouTube, des liens magnet et des adresses de wallet Bitcoin, mais l’idée, c’est de pouvoir retrouver n’importe quel type de contenu, juste en tapant une requête en français (ou une autre langue). Ce qui est cool aussi, c’est qu’en étant complètement décentralisé, ça empêche n’importe qui de contrôler le système ou de le censurer.
A terme, les chercheurs espèrent carrément développer un « cerveau global pour l’humanité ». Rien que ça. L’idée, c’est d’utiliser l’apprentissage décentralisé pour que la technologie profite au plus grand nombre, sans être contrôlée par les grosses entreprises ou les gouvernements. Comme ils le disent, « la bataille royale pour le contrôle d’Internet est en train de s’intensifier ». Et leur but, c’est de redonner le pouvoir aux citoyens, petit à petit.
En attendant, si vous voulez tester leur proof of concept, je vous mets le lien. Et si vous voulez en savoir plus sur le côté technique, vous pouvez checker leur papier de recherche.
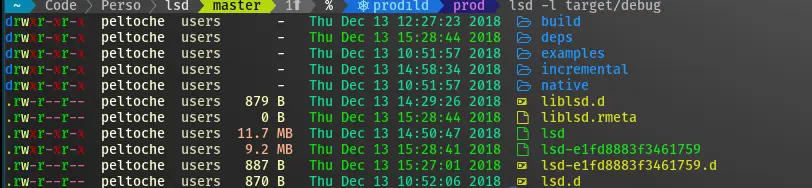
Aujourd’hui, on va parler d’un truc qui s’appelle LSD, mais attention hein, je parle pas de votre dernière soirée chemsex hein… C’est plutôt un clone open-source de la commande ls en mode survitaminé ! Développé par la communauté et écrit en Rust, il rajoute plein de fonctionnalités hyper stylées comme les couleurs, les icônes, la vue en arbre, des options de formatage en pagaille…
L’idée vient du projet colorls qui est vraiment super aussi. Mais LSD pousse le délire encore plus loin. Déjà il est compatible avec quasi tous les OS : Linux, macOS, Windows, BSD, Android…
Et hyper simple à installer en plus… un petit
apt install lsd ou brew install lsd
et c’est réglé.
Ensuite il est ultra personnalisable. Vous pouvez faire votre thème de couleurs et d’icônes sur mesure juste en bidouillant des fichiers de config en yaml. Et il supporte les polices Nerd Font avec des glyphes spéciaux trop classes ! Bon faut avoir la bonne police installée sur son système et le terminal configuré, mais c’est pas bien compliqué. Et si vous êtes sur Putty ou Kitty, y’a des tweaks spécifiques à faire, mais c’est expliqué dans la doc.
Mais attendez c’est pas fini ! LSD gère aussi les liens symboliques, la récursion dans les sous-répertoires (avec une profondeur max en option), des raccourcis pour les tailles de fichiers plus lisibles, des indicateurs pour les exécutables, les dossiers, etc. Il peut même vous sortir des infos de git sur les fichiers de ton repo si vous activez l’option ! Et pleins d’autres trucs que j’ai même pas encore testés…
Depuis que je l’ai installé et que j’ai changé mon alias ls, je me régale à chaque fois que je liste un dossier. J’ai l’impression d’être dans un vaisseau spatial avec des néons partout ! Bon j’exagère à peine, mais franchement ça envoie du lourd.
Allez je vais pas tout vous spoiler non plus, je vous laisse le plaisir de découvrir LSD par vous-même et customiser votre expérience du terminal. Moi en tout cas je suis fan, et je dis pas ça parce que je plane ! 😄
Attention, pépite de l’espace à vous faire découvrir aujourd’hui ! Ça s’appelle Durdraw et c’est un éditeur de folie pour créer de l’art ASCII, ANSI et Unicode dans votre terminal !
Imaginez pouvoir dessiner des animations old school avec une palette de 16 ou 256 couleurs, en mixant allègrement les caractères CP437 de l’époque MS-DOS avec de l’Unicode moderne. Le tout avec le support de thèmes customisés et de l’export en HTML et mIRC.
Si comme moi vous avez grandi avec des softs de légende comme TheDraw et PabloDraw, vous allez retrouver direct vos repères, mais avec la puissance et la souplesse du monde Unix en plus.
Durdraw est codé en Python donc pour l’installer c’est ultra simple, un petit coup de pip ou de git clone et vous êtes parés pour entrer dans la 4ème dimension de l’ANSI art 😎.
Les devs ont même pensé à inclure une config d’exemple et des thèmes bien sentis pour pas être largué en arrivant. Une fois lancé, préparez-vous à entrer dans la matrice : ça fourmille de raccourcis clavier dans tous les sens pour éditer au caractère et à la couleur près. Les nostalgiques des BBS apprécieront les commandes à base d’échappement, pendant que les plus modernes pourront même utiliser la souris pour peaufiner leurs chef d’oeuvres.
Et là où Durdraw se pose, c’est qu’il gère les animations image par image avec un contrôle total du timing. Fini l’époque où on dépendait du débit du modem, maintenant on créé des petits flip book ASCII qui restent stables même quand on redimensionne le terminal à la volée. Ça c’est de la qualité mes p’tits potes !
Bon après faut pas se leurrer, Durdraw ne rendra pas votre minitel compatible avec Unreal Engine 5 hein. Mais entre nous, est-ce qu’on a vraiment besoin d’aller jusque là quand on peut déjà pousser l’art ANSI dans ses derniers retranchements ? En plus l’auteur est hyper réactif sur GitHub pour améliorer son bébé au fil des contributions. C’est ça aussi la magie de l’open-source !
Bref, foncez sur https://durdraw.org, et lâchez-vous dans les créations bien rétro !
Multitasking MS-DOS 4. Rien que le nom ça fait rêver. Un nom qui respire le futur, qui transpire l’innovation. Mais c’est quoi en fait ?
Et bien au début des années 80, alors qu’on se battait encore en duel avec des disquettes 5″1/4, Microsoft avait dans ses cartons un projet d’OS révolutionnaire baptisé Multitasking MS-DOS 4. Bon, ce n’est pas le nom le plus sexy de l’histoire de l’informatique mais derrière cette appellation austère se cachait un système d’exploitation qui promettait déjà le multitâche et tout un tas de fonctionnalités incroyables pour l’époque !
L’histoire commence en 1983 lorsque Microsoft rassemble une équipe de développeurs talentueux pour plancher sur la nouvelle version de MS-DOS, qui doit apporter un max de nouveautés pour l’époque : multitâche, multi-threading, pipes, sémaphores… Tout ça sur les modestes processeurs 8086/8088 qui avaient une mémoire limitée.
Le projet s’appelle d’abord MS-DOS 3.0 avant d’être renommé MS-DOS 4.0 en avril 1984. En parallèle, Microsoft travaille sur le « vrai » DOS 3.0 qui sortira en août 1984. Vous suivez ? C’est un peu le bazar mais c’est ça qui est bon !
Puis en juin 1984, une première beta de Multitasking DOS 4 est envoyée à quelques privilégiés. Et autant vous dire que ça décoiffe ! Le multitâche fonctionne déjà, géré par un composant baptisé « Session Manager ». On peut lancer jusqu’à 6 applications en même temps en leur attribuant des raccourcis clavier. Le Session Manager gère aussi les fameuses « erreurs fatales » qui pouvaient faire planter tout le système. Avec lui, si un programme plante, il n’embarque pas tout le système avec lui. C’est un concept révolutionnaire pour l’époque !
MS-DOS 4.0 apportait également son lot d’améliorations comme une meilleure gestion de la mémoire, le support des disques durs de plus de 10 Mo (si si, à l’époque c’était énorme !), une API étendue, et même un système de fichiers réseau (Microsoft Networks).
Le développement de ce MS-DOS 4.0 s’est fait en étroite collaboration avec IBM car le géant informatique planchait à l’époque sur son propre OS avec une architecture similaire à MS-DOS 4.0. Mais plutôt que de se faire concurrence, Microsoft et IBM ont décidé de joindre leurs forces. MS-DOS 4.0 a ainsi servi de base au développement d’IBM PC-DOS 4.0. Les deux OS partageaient une grande partie de leur code source et étaient compatibles entre eux. Une belle démonstration du partenariat entre Microsoft et IBM !
Malheureusement, malgré toutes ses qualités, MS-DOS 4.0 n’a jamais été commercialisé. Son développement a été stoppé au profit d’OS/2, le nouveau projet de Microsoft et IBM et la plupart de ses fonctionnalités ont été recyclées dans ce nouvel OS.
Multitasking MS-DOS 4 est ainsi resté à l’état de projet, même si certaines de ses innovations ont survécu dans d’autres OS. Son code source est longtemps resté dans les cartons de Microsoft, jusqu’à ce que la société décide de le libérer en open source, sous licence MIT. Un joli cadeau pour les passionnés d’histoire de l’informatique !
Alors si vous êtes curieux d’essayer MS-DOS 4.0 par vous-même, sachez que c’est possible ! Grâce à la libération du code source, des passionnés ont pu recompiler l’OS et le faire tourner sur des machines modernes via des émulateurs comme DOSBox.
Voici les étapes pour lancer MS-DOS 4.0 sur votre PC :
Vous avez une vieille vidéo toute pourrie, floue à souhait, qui date de Mathusalem et bien avec VideoGigaGAN d’Adobe, elle va se transformer en une magnifique séquence HD, avec des détails si nets que vous pourrez compter les poils de nez des gens qui sont dessus !
VideoGigaGAN est ce qu’on appelle un modèle d’IA génératif. En gros, ce machin est capable de deviner les détails manquants dans une vidéo pourrave pour la rendre méga classe. Les petits gars d’Adobe ont balancé des exemples sur leur GitHub et franchement, c’est impressionnant. On passe d’une vidéo degueulasse à un truc ultra net, avec des textures de peau hallucinantes et des détails de fou !
En plus, cette IA est capable d’upscaler les vidéos jusqu’à 8 fois leur résolution d’origine, par contre, faut pas s’emballer car pour le moment, c’est juste une démo de recherche et y’a pas encore de date de sortie officielle. Mais connaissant Adobe, y’a moyen que ça finisse dans Premiere Pro un de ces quatre. Je vais pouvoir améliorer mes vidéos tournées à l’époque au format 3GP \o/.
D’ici là, va falloir continuer à se taper des vidéos de chat toutes pixelisées sur les réseaux sociaux.
Vous connaissez OpenELM ? Non, normal, ça vient de sortir. Et c’est une famille de modèles IA open-source made in Apple conçus pour tourner directement sur vos appareils, sans passer par le cloud. En gros, c’est de l’IA maison dans nos iPhone, iPad et Mac…etc.
OpenELM combine plusieurs modèles de langage naturel (LLMs) utilisant des algorithmes évolutionnistes qui exploitent les principes techniques suivants :
Layer-wise scaling strategy : Cette stratégie consiste à allouer les paramètres dans les couches d’un modèle transformeur pour améliorer l’exactitude. Les modèles sont pré-alourés avec un budget de paramètres de 270 millions, 450 millions, 1,1 milliard et 3 milliards.
Pré-entraînement : Les modèles ont été pré-entraînés à l’aide d’une combinaison de datasets, incluant une sous-ensemble de Dolma v1.6, RefinedWeb, deduplicated PILE et une sous-ensemble de RedPajama. Ce dataset contient environ 1,8 trillion de tokens.
Evolutionary algorithms : Les algorithmes évolutionnistes sont utilisés pour combiner les modèles LLM et améliorer l’exactitude. Cela permet d’exploiter les forces combinées des modèles pré-alourés et d’améliorer leur précision.
Alors évidemment, Apple arrive un peu après la bataille dans l’IA, pendant que Microsoft et Google déboulent à fond la caisse. Mais bon, mieux vaut tard que jamais, et puis ils compensent avec du lourd, soit 8 modèles OpenELM au total, dont 4 pré-entraînés avec CoreNet et 4 fine-tunés. Et avec leur stratégie de scaling par couche ça optimise à fond l’allocation des paramètres.
Allez, je traduits… En gros, ça veut dire qu’ils sont hyper efficaces et précis. Prenez le modèle à 1 milliard de paramètres et bien bah il explose un modèle équivalent comme OLMo de 2,36% en précision, avec 2 fois moins de tokens en pré-entraînement. Et ce qui est top, c’est qu’Apple balance tout : code, logs d’entraînement, configuration…etc et pas juste le modèle final. Et vu qu’ils utilisent des datasets publics, c’est top en matière de transparence et vérification des biais.
En tout cas, une chose est sûre, avec OpenELM, Apple nous prouve qu’ils sont dans la course, et qu’ils comptent bien mettre le paquet sur l’IA
Et Merci à Letsar pour l’info, c’est lui qui m’a mis la puce à l’oreille sur OpenELM. Tu gères !
Ah, les data brokers, ces entreprises mystérieuses dont on entend parler à peine plus souvent que de la météo sur Pluton (jamais en gros). Pourtant, ces entités obscures ont les mains (ou plutôt les serveurs) pleines de données, récoltées dans les plus sombres recoins numériques. J’ai déjà abordé le sujet sur ce site, mais comment opèrent-ils concrètement ? Voyage dans les entrailles du web pour percer le mystère des data brokers et comment lutter avec l’aide d’Incogni.
Qui sont-ils et que font-ils ?
Les data brokers, ce sont un peu les fantômes du cyberespace. On les connait rarement de nom, mais ils traquent nos traces numériques comme des chasseurs de primes à la recherche d’informations. Ils collectent des données de toutes sortes, du registre foncier à notre historique d’achat en passant par nos profils sociaux et nos activités en ligne. Une fois leur butin amassé, ils compilent le tout pour dresser un portrait-robot le plus précis possible et le revendent ou le partagent avec des tiers. Faisant de notre petite personne la cible d’un jeu de piste numérique. Tout ça pour quelques brouzoufs (enfin quelques … parfois ça peut se compter en centaines voire milliers d’euros). Le marché de la data étant en pleine phase d’expansion, ce marché juteux devrait quasiment doubler d’ici la fin de la décennie pour atteindre plus de 450 milliards de $.
Les types de data brokers
Et oui, contrairement à ce que vous pensez peut-être, tous les data brokers ne sont pas tous taillés dans le même moule. Ils offrent une variété de produits aux acheteurs. Cela va des informations financières à votre santé personnelle, en passant par le marketing et la publicité. Voici un petit tour d’horizon des espèces les plus répandues qui peuplent cet écosystème obscur.
Les brokers en recherche de personnes
Vous vous souvenez de ces annuaires téléphoniques épais et lourd comme un parpaing ? Eh bien ce type de broker fait la même chose, mais en version 2.0. Ils vous permettent de fouiller dans les profils d’autres consommateurs, de retrouver d’anciens amis ou de déterrer des secrets bien enfouis. Et pas besoin de sonner à leur porte pour qu’ils vous livrent leurs trouvailles, tout est en ligne et à portée de clic. Sans doute les brokers les plus visibles pour tous. Notamment accessibles sur des sites comme PeekYou, Spokeo ou White Pages. Une sorte de niveau 1 de l’espionnage, la base.
Les courtiers en marketing et publicité
C’est un peu comme la cour de récré pour les marketeurs. Ils segmentent les consommateurs en fonction de leur comportement et de leurs préférences, offrant des cibles sur un plateau d’argent aux annonceurs. Ils peuvent même enrichir nos profils avec des informations supplémentaires pour un ciblage ultra-précis (comme les géolocalisations ou le groupe ethnique). C’est pas cool, mais limite ce sont quasi les moins dangereux de l’histoire.
Les courtiers en informations financières
Si je vous cite des noms comme Experian, Equifax et Transunion il y a de grandes chances que cela ne vous dise rien. Pourtant, imaginez-les comme les trois mousquetaires de la data financière. Ils rassemblent tout ce qui s’y rapporte, que ce soit des rapports de crédit, des historiques de paiement et des informations sur les comptes débiteurs. Leur but ? Vendre les données aux institutions financières afin que celle-ci puisse prendre des décisions. Ils sont régis par diverses lois (notamment en Europe), mais ça ne les empêche pas de jouer les acrobates avec nos données. Un exemple concret ? Si l’on vous refuse un crédit de manière répétitive sans que vous compreniez trop pourquoi, c’est peut-être parce que les banques ont en stock vos précédents comportements et qu’ils n’ont pas assez confiance.
Les brokers en gestion des risques
Ces petits malins détectent les différentes fraudes que vous auriez pu commettre et vérifient les identités des clients en un clin d’œil. Avec des outils sophistiqués, ils peuvent traiter des millions de transactions par heure, gardant un œil vigilant sur nos activités et notre historique. Nos remboursements de crédit, nos salaires, les attestations ou amendes reçues, les découverts et autres agios, etc.
Les courtiers en santé
Ah, la santé, un sujet cher à nos cœurs et à nos portefeuilles. Ces brokers traquent par exemple nos achats de médicaments en vente libre, nos recherches sur les symptômes d’une maladie, nos abonnements à des magazines de santé, l’installation de certaines applications, etc. Ils vendent alors ces informations à des compagnies pharmaceutiques et d’assurance santé, faisant de notre bien-être une marchandise à échanger.
Mais d’où viennent ces données ?
Vous vous demandez peut-être comment ces brokers mettent la main sur nos données. Eh bien, c’est un peu comme un jeu de piste géant, avec des indices cachés dans tous les coins du web, parfois là où l’on ne s’y attend pas (voir mon article sur les différents leaks du milieu de l’automobile).
Les sources gouvernementales
Les gouvernements sont généreux avec nos informations, fournissant des données sur tout, des naissances aux décès en passant par les permis de conduire. Les data brokers se servent à pleines mains dans ce buffet à volonté de données publiques, construisant des profils détaillés sans jamais nous demander notre avis. Et je ne parle même pas de ces derniers mois ou les organismes officiels de notre cher gouvernement sont entrés en mode « grande braderie » (fuites France Travail, Urssaf, etc.). Servez-vous ma bonne dame, 80% de la population française est à portée de clavier, livrée de bon coeur.
Les sources commerciales
Les entreprises aussi sont des donneurs généreux. Elles fournissent des historiques d’achat, des données de garantie et même des informations de carte de fidélité. Et comme un bon ami qui prête sans jamais demander à être remboursé, elles donnent tout ça gracieusement aux data brokers, qui se régalent sans se poser de questions.
Les sources publiquement disponibles
Nos vies numériques (ou tout du moins une partie) sont des sortes de livres ouverts pour les data brokers. Ils parcourent nos profils sociaux, nos messages sur les forums et nos commentaires sur les blogs pour trouver des indices sur nos vies. Des enquêteurs privés, mais avec des algorithmes à la place de loupes. Le point positif c’est qu’au moins sur cet aspect nous avons notre mot à dire. Nous pouvons limiter les informations que nous partageons, utiliser des identités alternatives, sécuriser et chiffre nos échanges, etc.
Le pistage web
Et enfin, il y a le traçage en ligne, la cerise sur le gâteau des data brokers. Avec des cookies et des identifiants publicitaires, ils suivent nos moindres mouvements sur le web, collectant des informations sur nos habitudes de navigation et nos achats en ligne, récupèrent la liste des applications que nous utilisons, etc. Comme si Big Brother avait embauché des paparazzis pour nous suivre partout où nous allons. Mais là encore nous avons une part de responsabilité et nous pouvons agir de manière proactive (navigateur sans traqueurs, VPN …).
C’est déjà trop tard ?
Peut-être, mais cela peut éventuellement changer. Ils sont partout, ils savent tout, et nous, on est là, à ne pas trop savoir quoi faire. Mais nous pouvons décider d’au moins leur donner du fil à retordre. Déjà en faisant attention à ce que nous partageons en ligne, en utilisant les bons outils, etc. Et en faisant appel à un service comme Incogni pour tout ce qui est déjà dans la nature et que l’on ne peut rattraper.
Incogni, le désormais bien connu outil de Surfshark, propose un abonnement pour vous aider à nettoyer les données personnelles des bases de données des courtiers en données et des entreprises qui les stockent. Basé sur des réglementations comme le RGPD en Europe et la CCPA en Californie, Incogni impose aux courtiers en données de supprimer les informations des utilisateurs. Ces données peuvent être des choses comme vos noms, adresses, numéros de téléphone, etc.
Son gros avantage est de tout automatiser. Vous n’avez pas besoin de contacter chaque broker pour lui demander de vous supprimer de sa base de données. Incogni va le faire pour vous et surtout, va s’assurer que le retrait perdure. Un autre aspect intéressant du tableau de bord de l’outil est que vous allez visionner très rapidement les différents niveaux de dangerosité des courtiers. Mais aussi de connaitre le champ d’action de chacun d’entre eux et si vous trainez plutôt du côté des données de santé ou de la publicité.
Concrètement pour voir comment cela se passe, je vous redirige vers mon test Incogni sur une période d’un an. On va dire que le gros du travail se fait sur les 3 premiers mois, et qu’ensuite les récalcitrants finissent pas craquer au fil des relances du service. En ce moment ce dernier est d’ailleurs à moins de 95€ TTC par an, environ 7.8€/mois.
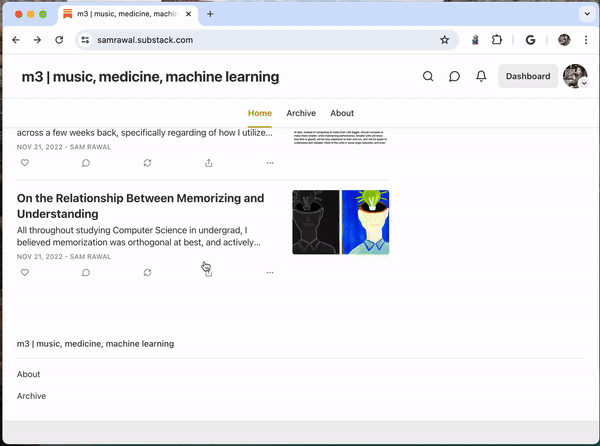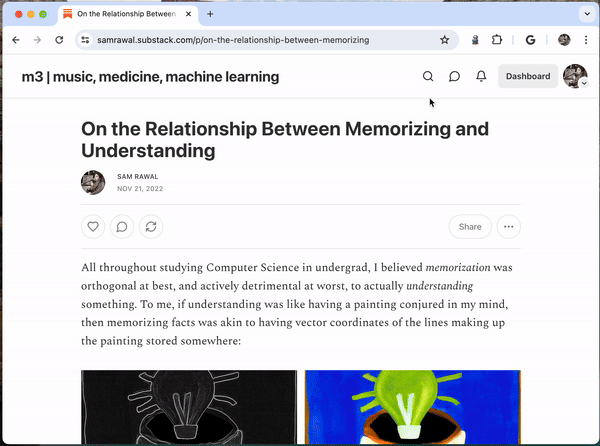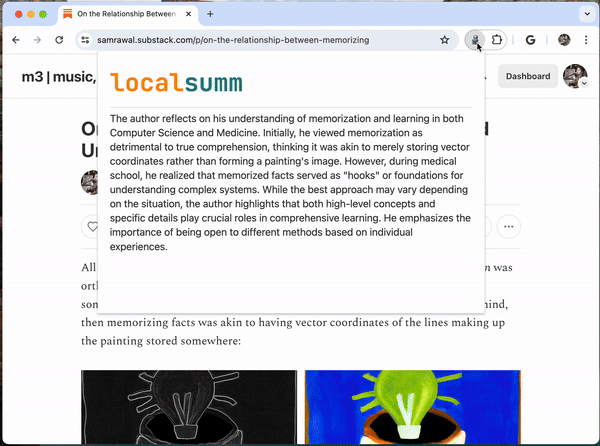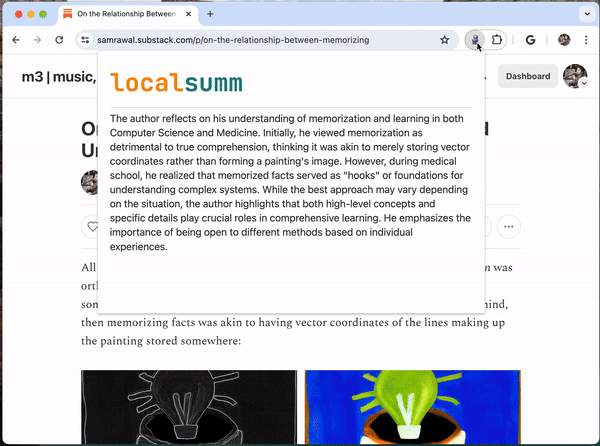
Localsumm est un générateur de résumés nouvelle génération qui tourne direct dans votre navigateur Chrome, sans envoyer vos données sur le cloud. Sous le capot, cette petite extension magique utilise un modèle de langage maison développé par Microsoft : le fameux Phi-3. C’est une sorte de cousin du célèbre GPT, mais en version allégée et spécialisée dans le résumé de texte.
Pour tester cette merveille, c’est assez simple. Déjà, il faut avoir Chrome (ou un clone open source comme Brave ou Chromium) puis :
Clonez le code source de Localsumm depuis GitHub avec Git : git clone https://github.com/samrawal/localsumm.git
Allez dans les extensions Chrome (chrome://extensions), activez le mode développeur, cliquez sur « Charger l’extension non empaquetée » et sélectionnez le dossier localsumm
Et voilà, vous avez votre assistant de lecture perso, prêt à croquer des articles et recracher des résumés bien juteux !
Localsumm est encore tout jeune et son code est en cours de développement, alors forcément il y a quelques bugs et fonctionnalités manquantes. Perso, j’ai déjà quelques idées d’amélioration :
Ajouter la génération automatique d’un tweet avec les points clés de l’article, pour envoyer sur mes réseaux
Intégrer les résumés dans le moteur de recherche de l’historique Chrome, pour retrouver facilement les derniers trucs que j’ai lu
Pouvoir partager un résumé en 1 clic avec ses contacts
Créer une version mobile de l’extension pour résumer le web sur son smartphone
Et bien sûr un portage sur Firefox parce que moi, j’utilise surtout ce navigateur là.
En tout cas, je trouve que Localsumm est vraiment une chouette idée pour les gens pressés.
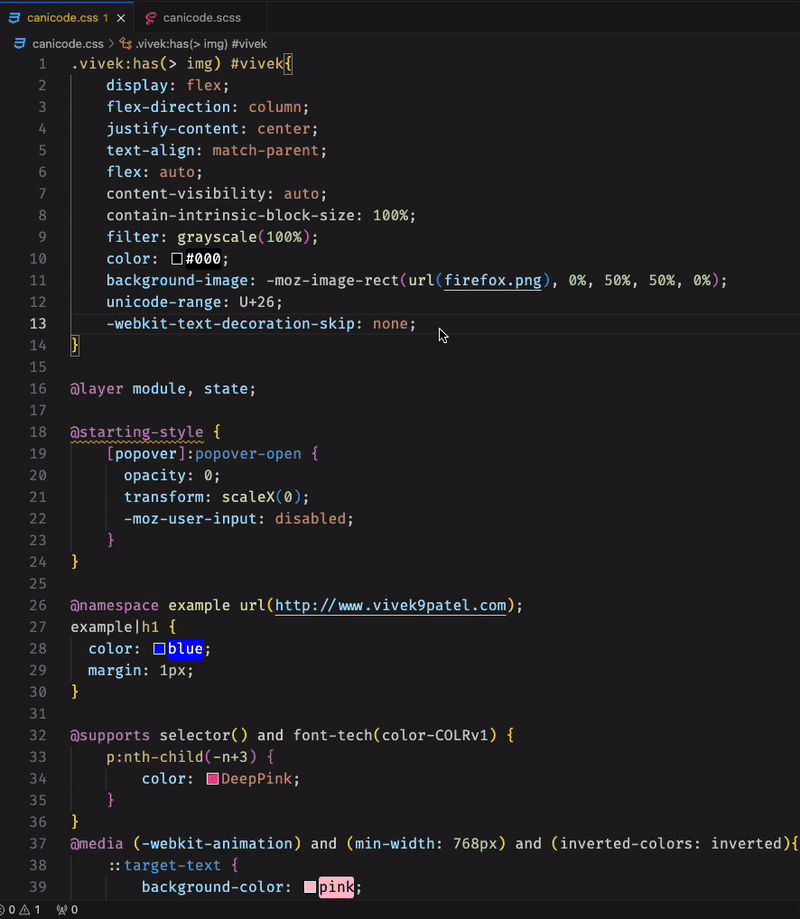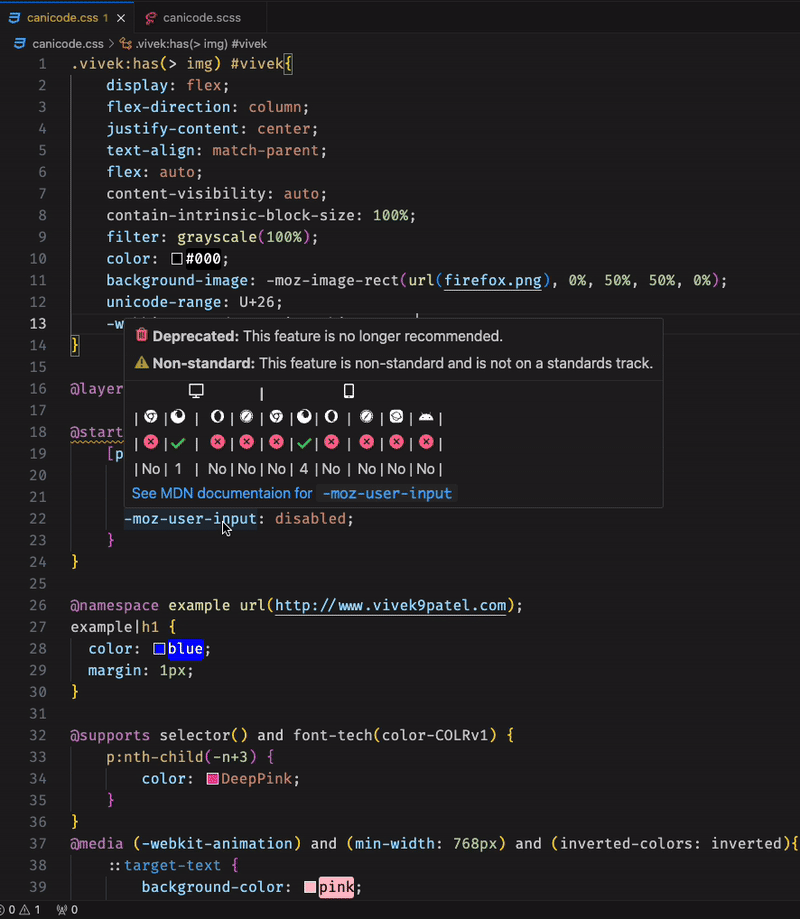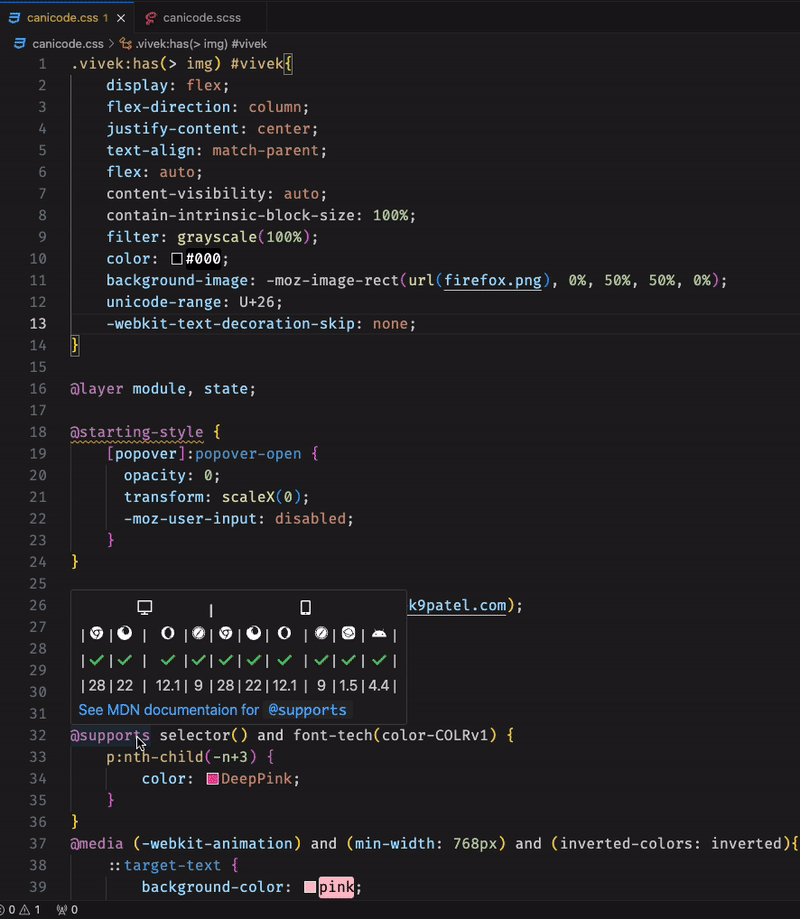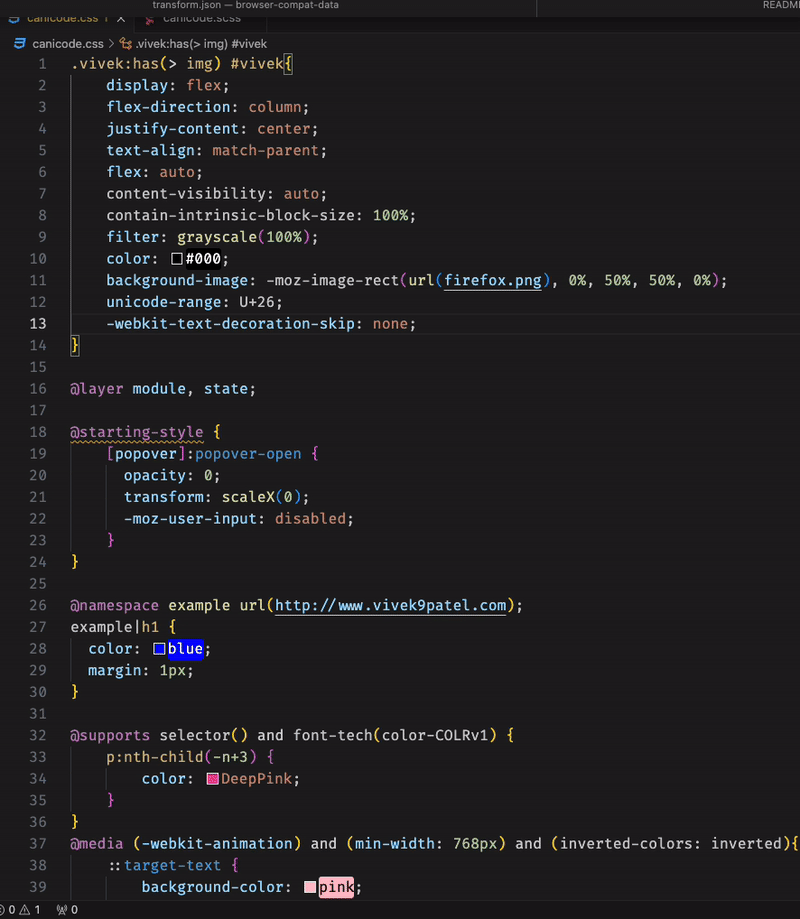
Et si aujourd’hui, on parlait un peu de l’extension CSS Compatibility Checker pour Visual Studio Code ? Un outil juste dingue qui va vous aider à voir en un clin d’œil si votre code est compatible avec tous les navigateurs. Plus besoin de passer des heures à éplucher la doc ou de croiser les doigts en espérant que ça passe, cette petite merveille va vous changer la vie !
Imaginez un peu le topo : vous êtes tranquillou en train de tapoter votre CSS, vous balancez une propriété backdrop-filter pour flouter votre background avec classe et là bim 💥, l’extension vous remonte direct que c’est pas compatible avec certaines vieilles versions de navigateurs.
Ou alors vous utilisez un mot-clé un peu exotique genre unset et hop, elle vous alerte que c’est potentiellement casse-gueule. C’est ti pas beau ça ?
CSS Compatibility Checker s’adresse donc aux développeurs frontend un peu soucieux de la compatibilité de son code. Je sais, ils ne sont pas nombreux ^^. En un survol de souris, vous avez accès à toutes les infos dont vous avez besoin : si telle syntaxe, fonction ou propriété est dépréciée, non-standard, expérimentale ou pas supportée partout. Et c’est valable pour un tas de versions de navigateurs différentes !
Pour en profiter, vous devrez installer l’extension depuis la marketplace de VS Code, et ensuite il vous suffit d’ouvrir un fichier CSS, SCSS ou LESS et de laisser le curseur survoler l’élément qui vous intéresse. Et là, magie, une petite bulle s’affiche avec toutes les infos de compatibilité. De quoi prendre les bonnes décisions pour votre projet !
Alors certes, CSS Compatibility Checker ne va pas non plus révolutionner le monde du développement web du jour au lendemain mais pour tous ceux qui en ont un peu ras la casquette de se farcir des heures de tests sur 15 versions d’Internet Explorer, c’est définitivement une extension à avoir sous la main. Et puis c’est gratuit et open-source en plus, alors que demande le peuple ?
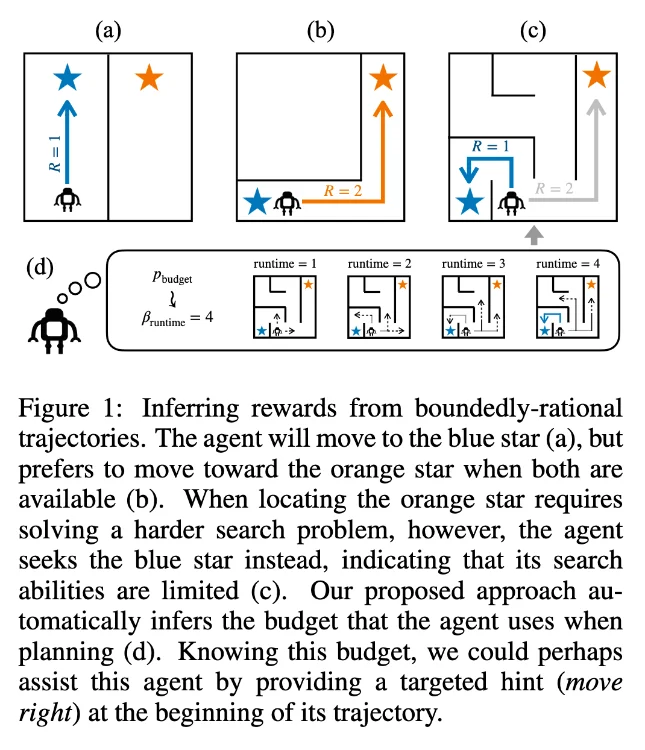
Imaginez un monde où les ordinateurs pourraient prédire ce que vous allez faire avant même que vous ne le fassiez. Ça peut sembler tout droit sorti d’un film de science-fiction du style de Minority Report, mais les chercheurs du célèbre MIT (Massachusetts Institute of Technology) sont en train de rendre ça possible ! En effet, ils ont mis au point un modèle d’IA (intelligence artificielle) qui est capable d’analyser les limitations d’un agent, qu’il soit humain ou artificiel, pour en déduire ses actions futures les plus probables.
Dingue, non ?
Mais comment ce modèle s’y prend-il pour jouer les madame Irma ? En fait, tout est une question de limites. Nan, je ne parle pas des limites de vitesse ou des dates de péremption, hein. Je parle des contraintes qui pèsent sur un agent peu importe sa nature, biologique ou numérique.
Prenons un exemple concret : Vous êtes en train de jouer aux échecs contre un ordinateur. Vous avez vos propres contraintes : votre niveau de jeu, votre connaissance des ouvertures et des fins de partie, votre capacité à anticiper les coups de l’adversaire… Bref, tout un tas de facteurs qui limitent vos possibilités d’action. Eh bien, c’est exactement ce que le modèle d’IA du MIT analyse !
En se basant sur ces fameuses limites, il est capable d’inférer les coups que vous avez le plus de chances de jouer. Pas besoin d’être Garry Kasparov pour comprendre à quel point c’est bluffant. Votre ordinateur sera bientôt meilleur que vous aux échecs… et dans plein d’autres domaines !
Mais attention, le modèle du MIT ne prétend pas prédire l’avenir avec une précision de 100%. Il s’agit plutôt d’identifier des tendances et des schémas de comportement en fonction des limitations d’un agent. Ça reste néanmoins un outil très puissant pour anticiper les actions les plus probables.
D’ailleurs, les applications de cette technologie vont bien au-delà des jeux de société. Je pense par exemple au voitures autonomes qui pourraient anticiper les mouvements des piétons et des autres véhicules, des assistants virtuels qui sauraient exactement ce que vous allez leur demander avant même que vous n’ouvriez la bouche, des robots industriels capables de s’adapter en temps réel aux changements de leur environnement… Les possibilités sont infinies !
Bien sûr, tout cela soulève aussi son lot de questions éthiques. Est-ce qu’on a vraiment envie que les machines lisent dans nos pensées comme dans un livre ouvert ? Est-ce que ça ne risque pas de créer de sacrés problèmes de vie privée et de manipulation ? Imaginez que votre enceinte connectée décide de vous commander une pizza quatre fromages parce qu’elle a deviné que vous aviez un petit creux… Flippant, non ?
Mais bon, on n’en est pas encore là. Pour l’instant, les chercheurs du MIT sont encore en train de plancher sur leur modèle pour le perfectionner et étendre ses capacités. Et croyez-moi, c’est loin d’être un long fleuve tranquille ! L’IA a beau faire des progrès de géant, prédire le comportement humain reste un sacré défi. On est tellement imprévisibles et irrationnels, nous autres mortels…
En attendant de pouvoir déléguer toutes nos décisions à une machine, le modèle du MIT nous offre un aperçu de ce que pourrait être le futur de l’interaction homme-machine. Un futur où les ordinateurs nous comprendraient mieux que nous-mêmes, pour le meilleur et pour le pire. Perso, j’oscille entre fascination et inquiétude.
Vous pensiez connaître Castlevania sur le bout des doigts ? Eh bien 25 ans après la sortie de Castlevania: Legacy of Darkness sur notre bonne vieille Nintendo 64, des petits malins ont déniché un tout nouveau code Konami planqué dans les entrailles du jeu.
Ce code Konami est une vraie petite bombe puisqu’il déverrouille d’un coup TOUS les personnages et leurs costumes alternatifs, et ce dès le début de l’aventure ! Fini de devoir se farcir le jeu deux fois pour accéder à Henry et Carrie. Là c’est open bar direct, et ça change complètement la donne !
Moises et LiquidCat, deux fans passionnés du jeu, ont également déniché deux autres codes bien sympathiques. Le premier remplit entièrement votre inventaire, peu importe le héros que vous incarnez. Fini la galère pour trouver des potions et des équipements, vous voilà paré pour latter du vampire en claquant des doigts. Le second code, disponible uniquement dans les versions japonaise et européenne, booste votre arme au max et vous file un stock de joyaux dont même Picsou serait jaloux. De quoi rendre votre quête bien plus funky !
Pour activer ces codes, rien de plus simple :
Ouvrez le jeu et sélectionnez le mode histoire.
Tapez le code en doublant les inputs du code Konami classique : Up, Up, Down, Down, Left, Right, Left, Right, B, A, Start.
Utilisez les boutons directionnels et A/B de votre manette N64.
Appuyez sur Start pour confirmer l’activation.
Enjoy ! Vous pouvez maintenant jouer avec tous les persos dès le début.
Codes bonus pour les plus curieux :
Inventaire au max : Up, Up, Down, Down, Left, Right, Left, Right, B, A, Start (x2)
Arme boostée et argent illimité (versions PAL/JPN uniquement)
Alors certes, dit comme ça, ça peut sembler un poil cheaté mais ça fait un quart de siècle que ce jeu nous nargue avec ses secrets, donc ça va, y’a tolérance. En plus, avouons-le, ces codes tombent à pic pour (re)découvrir cet opus culte car s’il y a bien un reproche qu’on pouvait faire à Legacy of Darkness, c’était ce côté un peu prise de tête avec un seul personnage jouable au début. Un choix curieux qui pouvait rebuter certains joueurs. Mais grâce à ce code Konami providentiel, ce problème est relégué aux oubliettes ! Vous pouvez enfin profiter des cinq perso et de leurs capacités uniques sans vous prendre le chou.
Alors si vous aussi vous avez une Nintendo 64 qui prend la poussière dans un coin (ou un émulateur), c’est le moment ou jamais de ressortir Castlevania: Legacy of Darkness et de tester ces fameux codes.
Figurez-vous qu’Elektrobit, le géant allemand de l’électronique automobile, vient de nous pondre un truc qui va faire plaisir aux fans de libre : EB corbos Linux, le premier système d’exploitation open source qui respecte les normes de sécurité les plus pointues du monde de la bagnole.
En gros, les constructeurs en ont marre de se trimballer des kilomètres de câbles et des centaines de boîtiers noirs dans leurs caisses-. L’idée, c’est de tout centraliser sur quelques « super ordinateurs » qu’ils appellent des « plateformes de calcul haute performance ». Et chacun gère son domaine : la conduite, l’info-divertissement, les aides à la conduite… Bref, ça simplifie le bordel et ça permet de faire évoluer les fonctionnalités sans toucher au hardware.
Le hic, c’est que tout ce bazar logiciel doit être hyper sécurisé. Parce que si votre autoradio plante, c’est pas bien grave, mais si c’est votre direction assistée qui décide de partir en vacances, bonjour les dégâts ! C’est là qu’EB corbos Linux entre en scène.
Grâce à son architecture unique, ce système d’exploitation prend Linux et le rend compatible avec les exigences les plus draconiennes en matière de sécurité automobile, genre les normes ISO 26262 et IEC 61508 en utilisant un hyperviseur et un système de monitoring externe qui valide les actions du noyau. En gros, Linux peut continuer à évoluer tranquillou sans compromettre la sécurité.
Comme cette distrib est basé sur du bon vieux Linux, il profite de toute la puissance de l’open source. Genre les milliers de développeurs qui bossent dessus, les mises à jour de sécurité en pagaille, la flexibilité, la rapidité d’innovation… Tout ça dans une distrib’ véhicule-compatible, c’est quand même cool. En plus, Elektrobit a développé ce petit miracle main dans la main avec l’équipe d’ingénieurs d’Ubuntu Core chez Canonical. Autant dire que c’est du lourd !
Elektrobit a pensé à tout puisqu’ils proposent même une version spéciale pour les applications critiques, genre les trucs qui peuvent tuer des gens s’ils plantent. Ça s’appelle EB corbos Linux for Safety Applications, et c’est le premier OS Linux à décrocher la certification de sécurité automobile auprès du TÜV Nord.
Mais le plus cool, c’est qu’avec cet OS, vous pouvez laisser libre cours à votre créativité de développeur automobile. Vous voulez intégrer les dernières technos de conduite autonome, d’intelligence artificielle, de reconnaissance vocale… Pas de problème, Linux a tout ce qu’il faut sous le capot.
Imaginez que vous bossiez sur un système de reconnaissance de panneaux pour aider à la conduite. Avec ça, vous pouvez piocher dans les bibliothèques open source de traitement d’image, de machine learning, etc. Vous adaptez tout ça à votre sauce, en respectant les contraintes de sécurité, et voilà ! En quelques sprints, vous avez un truc qui déchire, testé et approuvé pour la route. Et si un autre constructeur veut l’utiliser, il peut, c’est ça la beauté de l’open source !
Autre exemple, vous voulez développer un système de monitoring de l’état de santé du conducteur, pour éviter les accidents dus à la fatigue ou aux malaises. Là encore, EB corbos Linux est votre allié. Vous pouvez utiliser des capteurs biométriques, de l’analyse vidéo, des algorithmes de détection… Tout en étant sûr que votre code ne mettra pas en danger la vie des utilisateurs.
Bref, vous l’aurez compris, c’est le meilleur des deux mondes avec d’un côté, la puissance et la flexibilité de Linux, de l’open source, de la collaboration à grande échelle et de l’autre, la rigueur et la sécurité indispensables au monde automobile, où la moindre erreur peut coûter des vies.
Vous pensiez avoir tout vu en matière de distributeurs automatiques ? Et bien le pays du Soleil Levant repousse une fois de plus les limites de l’imagination avec une machine pour le moins insolite : un distributeur de… CPU Intel ! Si, si, vous avez bien lu. Au pays des capsules toys, tout est possible même de tomber sur un Core i7-8700 pour la modique somme de 500 yens, soit environ 3 dollars.
La scène se passe devant une boutique d’informatique nommée 1’s PC, qui a visiblement eu l’idée farfelue de recycler ses vieux processeurs en les mettant dans un distributeur façon gacha. Le principe est simple : vous insérez une pièce, tournez la manivelle, et hop ! Voilà votre petite capsule contenant un CPU mystère. C’est comme une pochette surprise, mais avec des puces en silicium dedans. Évidemment, c’est la loterie : vous pouvez aussi bien tomber sur un vieux Celeron tout poussiéreux que sur une pépite comme ce fameux i7-8700.
Un YouTubeur japonais nommé Sawara-San a tenté sa chance et a eu la main particulièrement chanceuse en décrochant le précieux sésame pour seulement 500 yens. Ni une ni deux, notre bidouilleur s’est empressé de rentrer chez lui pour tester la bête et vérifier si le CPU est fonctionnel ou non. Parce que bon, à ce prix-là, on peut légitimement avoir des doutes.
Après un montage express sur une carte mère d’occasion, première tentative de boot et… rien. Nada. Que dalle. L’écran reste désespérément noir. Le CPU serait-il mort ? Que nenni ! Après quelques secondes de panique, notre cher Sawara-San s’est rendu compte qu’il avait juste oublié de brancher le câble d’alimentation du GPU. Une fois ce léger détail corrigé, l’ordinateur a enfin daigné s’allumer.
Direction le BIOS pour checker les infos CPU et là, bingo ! C’est bien un Core i7-8700 qui est détecté. Ce processeur possède 6 cœurs et 12 threads, avec une fréquence de base de 3.2 GHz et un boost jusqu’à 4.6 GHz. Il est compatible avec les cartes mères équipées d’un socket LGA 1151 et d’un chipset de la série 300. Maintenant, il faut installer Windows et vérifier que tout fonctionne correctement. Et c’est là que les choses se corsent un peu…
L’installation se passe sans accroc, mais une fois sur le bureau, Sawara-San remarque quelques artefacts graphiques suspects. Après investigation, il semblerait que la puce graphique intégrée du CPU ait morflé. Ces soucis semblent spécifiques à ce processeur en particulier et ne sont pas forcément représentatifs de tous les Core i7-8700. Bon, tant pis, il décide de passer outre et de lancer quelques benchmarks pour voir ce que le proc a dans le ventre.
Résultat : l’i7-8700 se comporte plutôt bien malgré son statut de rescapé d’un distributeur automatique ! Sous Cinebench R15, il atteint un score de 992 points en multi-thread. Certes, c’est un poil en-dessous d’un modèle fraîchement sorti d’usine, mais pour 3 dollars, on va éviter de faire la fine bouche, hein.
En fouillant un peu dans le Gestionnaire des tâches, Sawara-San se rend compte que le CPU ne compte que 5 cœurs actifs au lieu de 6. Étrange… Serait-ce un autre dommage collatéral ? Ni une ni deux, il fonce dans le BIOS et décide de désactiver manuellement le cœur défectueux. Et voilà, le tour est joué ! Windows ne voit plus que 5 cœurs, mais au moins, le système est stable.
Au final, ce Core i7-8700 bradé dans un distributeur aura fait le bonheur de Sawara-San qui, pour seulement une poignée de yens, a pu mettre la main sur un CPU encore vaillant. Certes, la puce a quelques défauts, comme son iGPU aux fraises et un cœur en moins, mais pour ce prix, c’est tout bonnement exceptionnel. Un vrai coup de bol !
Et vous, seriez-vous prêt à tenter votre chance dans ce drôle de distributeur de CPU ?
Qui sait, peut-être que la chance vous sourira aussi ! En attendant, si vous passez devant la boutique 1’s PC au Japon, n’hésitez pas à faire un petit tour au rayon gacha, car c’est peut-être vous le prochain gagnant d’un processeur haut de gamme pour le prix d’un café !
Comme tout le reste, le prix des instruments de musique s’envole. Bien sûr, vous rêvez de jouer du piano mais vous n’avez pas les moyens de vous en payer un. Snif c’est trop triste ! Heureusement, tonton Korben est là, c’est plus la peine de faire les brocantes, puisque j’ai déniché un petit bijou qui devrait vous plaire !
Grâce au projet Paper Piano disponible sur GitHub, vous allez pouvoir vous improviser pianiste avec juste une feuille de papier, un feutre et votre webcam. Si si, je vous jure, c’est possible et en plus c’est fun !
Bon, évidemment, on est loin des sensations d’un vrai piano à queue, faut pas rêver non plus mais le concept est super cool et ça permet de s’initier au piano sans se ruiner. Pour l’instant, le projet ne supporte que 2 doigts maximum (un de chaque main) mais le développeur bosse dur pour améliorer ça et permettre de jouer avec tous les doigts comme un vrai pro.
Alors comment ça marche ce truc ?
En fait c’est plutôt simple, il suffit de cloner le repo GitHub, d’installer les dépendances Python en lançant
pip install -r requirements.txt
dans votre terminal et d’exécuter le script
run.py
Jusque là, rien de bien sorcier pour ceux qui sont un peu à l’aise avec la ligne de commande.
La partie un peu plus délicate, c’est l’installation de la webcam. Vu que le programme va devoir détecter votre doigt et son ombre sur le papier, il faut la positionner au bon endroit, avec le bon angle et à la bonne distance. En gros, il faut qu’elle puisse voir votre doigt et les deux rectangles que vous aurez dessinés au marqueur noir de chaque côté de votre feuille A4. Ça demande un peu de bidouille mais en suivant bien les instructions et en regardant la vidéo démo, vous devriez y arriver !
Un petit tips au passage : pensez à bien éclairer votre zone de jeu. Plus la lumière sera forte, mieux l’ombre de votre doigt sera visible et meilleurs seront les résultats. Évitez quand même d’avoir une lumière directe dans l’objectif de la webcam, ça risquerait de tout faire foirer.
Une fois votre matos en place, vous allez pouvoir passer à la phase d’entraînement du modèle. Pour ça, une fenêtre va s’ouvrir et une boîte va s’afficher autour du bout de votre doigt. Vérifiez bien qu’elle englobe tout le doigt et ses environs proches, sinon réglez à nouveau le positionnement de la caméra.
Ensuite c’est parti pour la séance de muscu des doigts !
Alors un conseil, allez-y mollo sur les mouvements. Pas la peine de vous exciter comme un fou jusqu’à trouer le papier, faites ça doucement en montrant bien tous les angles de votre doigt. Et quand vous appuyez, appuyez normalement, pas besoin d’écraser votre feuille non plus. Idem quand vous relevez le doigt, levez le franchement mais pas trop près du papier non plus. En gros, faites comme si vous jouiez sur un vrai piano.
Le projet utilise un réseau de neurones convolutif (CNN) pour apprendre à distinguer les états « doigt en contact » et « doigt levé ». Et bien sûr, si les résultats ne vous conviennent pas, vous pouvez relancer une session d’entraînement pour affiner le modèle.
L’objectif à terme pour le dev, ce serait d’arriver à transformer ce prototype en un vrai piano fonctionnel sur papier. Vous imaginez un peu le truc ? Ça permettrait à tous ceux qui n’ont pas les moyens de s’acheter un piano d’apprendre à en jouer quand même. La classe non ?
Après comme c’est un projet open-source, y’a pas vraiment de mode d’emploi gravé dans le marbre. Toutes les bonnes idées et les améliorations sont les bienvenues !
Je suis sûr qu’on n’a pas fini d’entendre parler de ce genre d’expériences de Papier Augmenté. Qui sait, bientôt on pourra peut-être transformer une simple feuille en un véritable home-studio ! Vous imaginez, une batterie en papier, une basse en carton, une guitare en origami… Ok je m’emballe un peu là, mais l’avenir nous réserve sûrement encore plein de surprises de ce type.
Sur ce, joyeux bidouillage à tous et à la prochaine pour de nouveaux projets délirants !
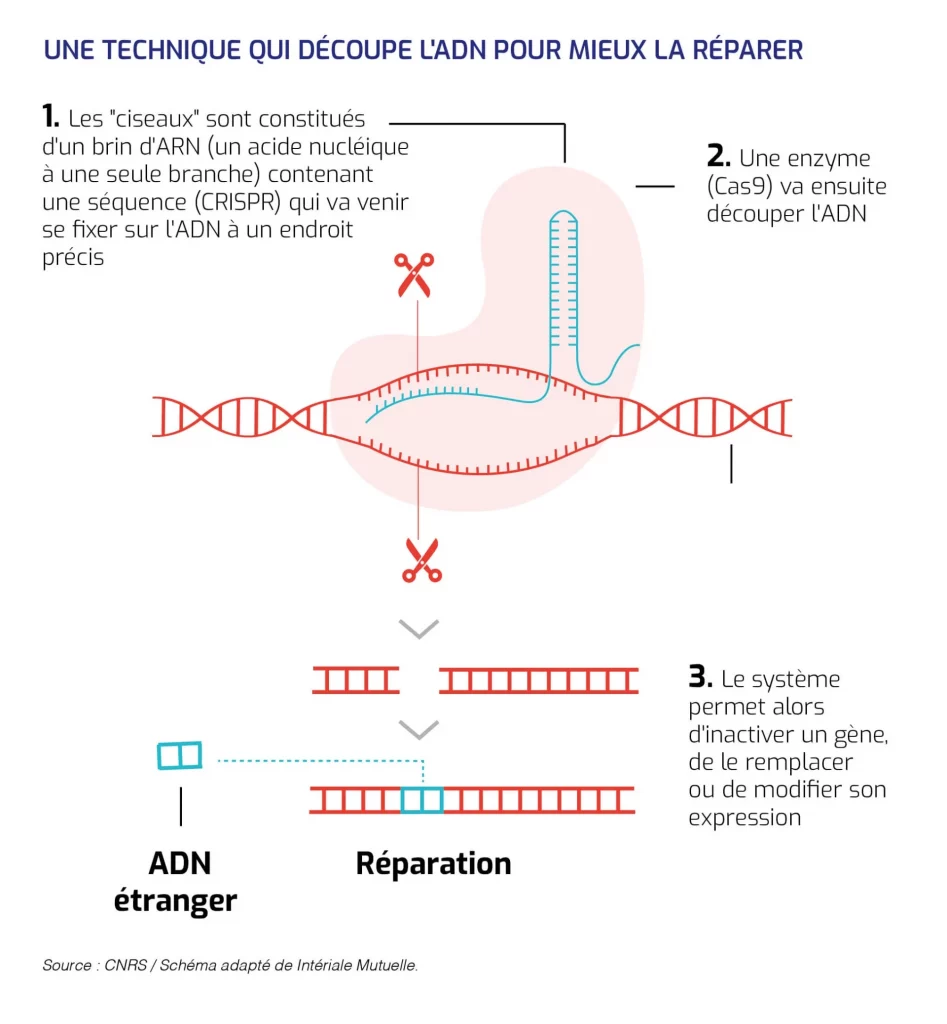
Vous avez sans doute entendu parler de CRISPR-Cas9 (non), cet outil d’édition génétique révolutionnaire qui permet de modifier l’ADN avec une précision chirurgicale. Et bien, figurez-vous que cette technologie déjà impressionnante pourrait être boostée par une autre innovation majeure : l’IA générative !
Attention, on est sur du lourd. En gros, l’idée c’est d’utiliser la puissance des algorithmes d’IA pour prédire les meilleurs « guides ARN » qui vont diriger les ciseaux moléculaires de CRISPR pile poil où il faut sur le génome. Plus besoin de faire de nombreux tests, il suffit de demander à votre IA favorite de vous générer le guide ARN parfait !
Mais à quoi ça va servir tout ça ?
Déjà, ça pourrait bien révolutionner la recherche biomédicale. Imaginez qu’on puisse modeler des lignées cellulaires ou des organismes modèles avec les mutations souhaitées rapidement, le gain de temps serait considérable ! Surtout que l’IA ne va pas juste prédire l’efficacité des guides ARN, mais aussi les potentiels effets secondaires. Parce que c’est bien beau de jouer avec le code de la vie, mais il faut éviter les conséquences indésirables… Là, l’IA va pouvoir modéliser les modifications « off-target » et réduire les risques.
Et à terme, ça ouvre des perspectives intéressantes pour la médecine personnalisée. Des thérapies géniques sur-mesure, où il suffirait de séquencer votre ADN, le fournir à une IA qui va déterminer le traitement CRISPR optimal, et hop, traiter des maladies génétiques ! Bon après, il faudra encore travailler sur les vecteurs pour acheminer ça dans les bonnes cellules…
Cela dit, on n’en est pas encore là, et il y a quand même des défis importants à relever. Déjà, éthiquement ça soulève des questions. Est-ce qu’on est prêts à laisser une IA influencer le génome humain ? Et il va falloir un cadre réglementaire solide et beaucoup de transparence pour éviter les dérives… Et puis techniquement, c’est loin d’être gagné ! Les interactions génétiques sont très complexes, avec de nombreux phénomènes comme l’épistasie et la pléiotropie. Pas sûr que les IA arrivent à modéliser un système aussi compliqué, même avec du deep learning poussé… Sans compter les contraintes pour synthétiser les guides ARN.
Mais bon, c’est le genre de défi stimulant non ? Si des IA peuvent générer des images bluffantes ou écrire du code, pourquoi pas des modifications génétiques ? En tout cas, une chose est sûre, la convergence de l’IA et des biotechs promet des avancées passionnantes.
Alors oui, certains diront que tout ceci relève encore de la spéculation, voire de la science-fiction. Que l’édition génétique est trop complexe pour être entièrement automatisée, même avec l’aide de l’IA. Que les risques de dérives sont trop grands et qu’il faut appliquer le principe de précaution. Ce sont des arguments à prendre en compte. Mais bon, on a dit pareil pour la fécondation in vitro, les OGM, les thérapies géniques…
À chaque fois, on nous dit que c’est contre-nature, que ça va avoir des conséquences désastreuses, et au final ça finit par entrer dans les mœurs et faire progresser la médecine. Alors sur l’IA et CRISPR, voyons jusqu’où ça nous mène, tout en étant vigilants sur les enjeux éthiques. Parce qu’on parle quand même de technologies avec un potentiel énorme pour soigner des maladies et améliorer notre compréhension du vivant. Ce serait dommage de tout bloquer.
Maintenant, si vous voulez en savoir plus sur la révolution CRISPR-IA, je vous invite à lire cet excellent article du New York Times.
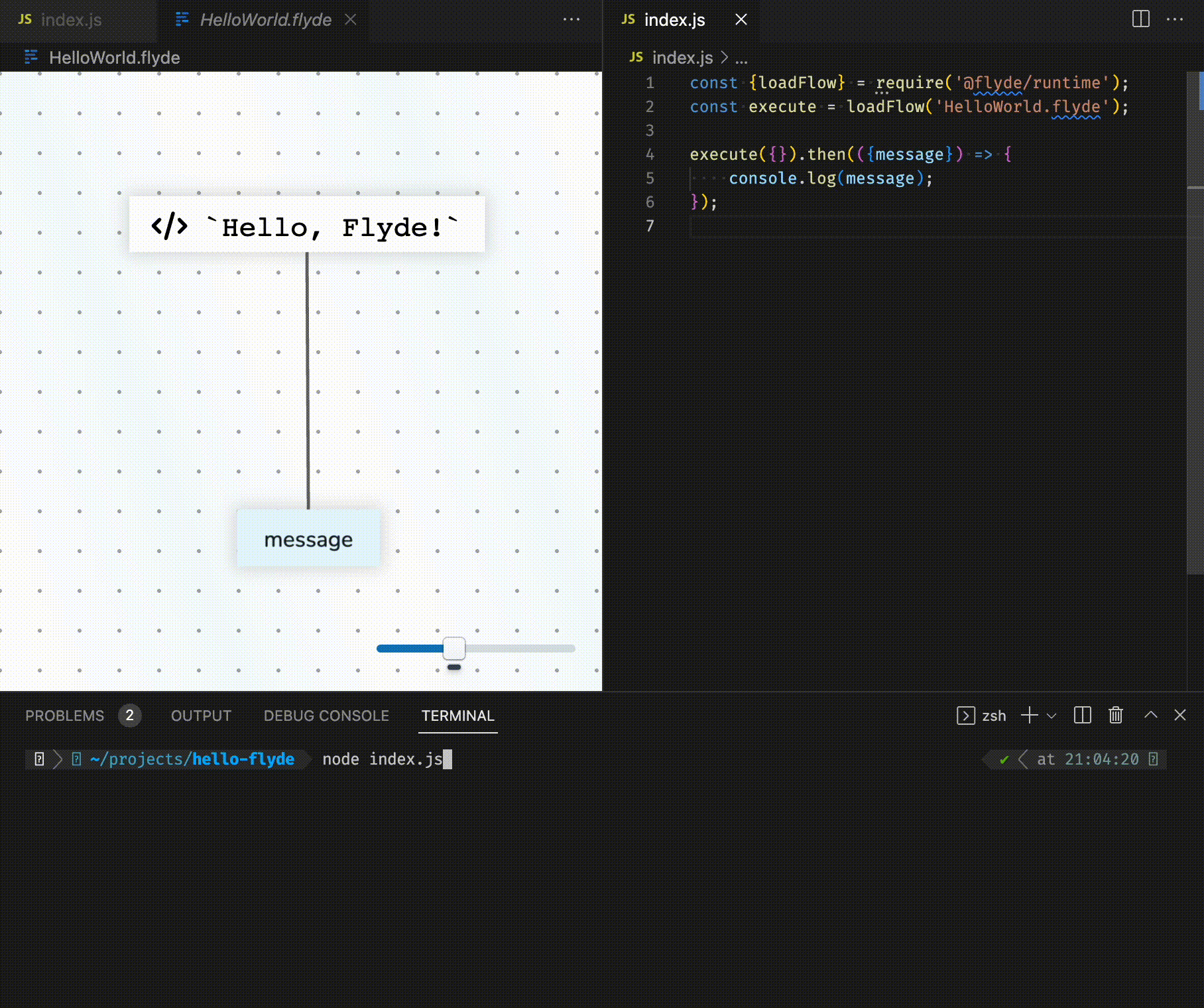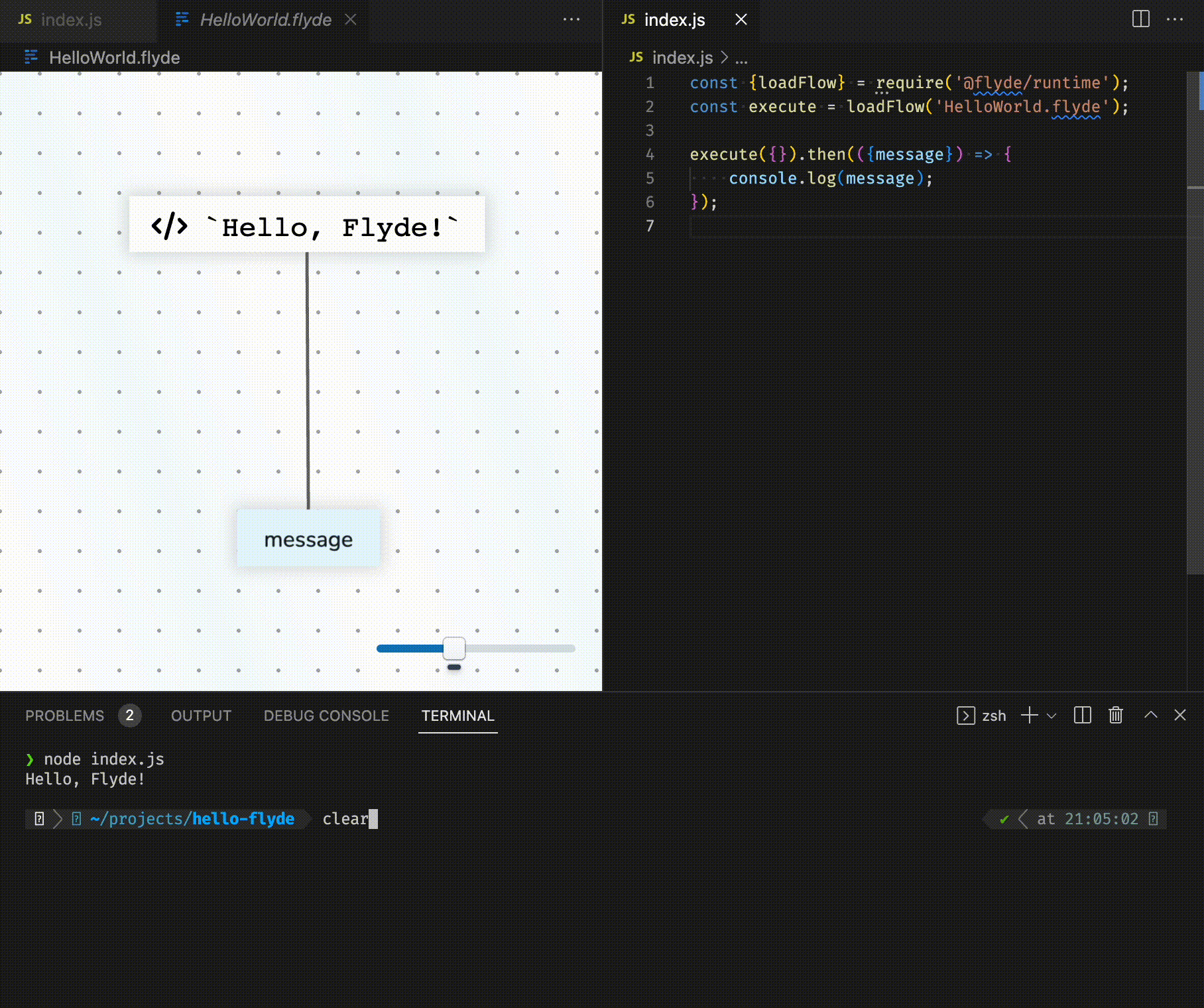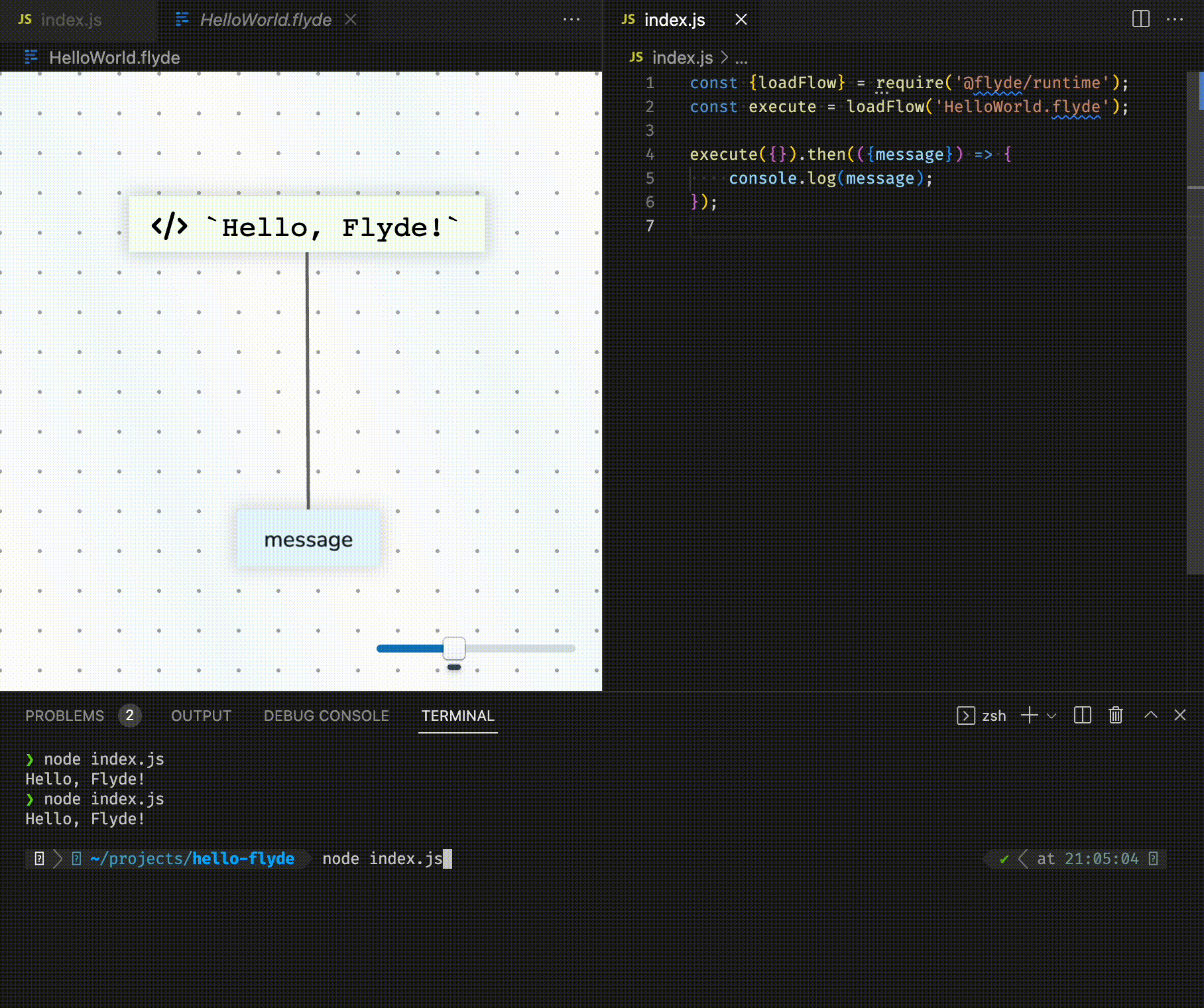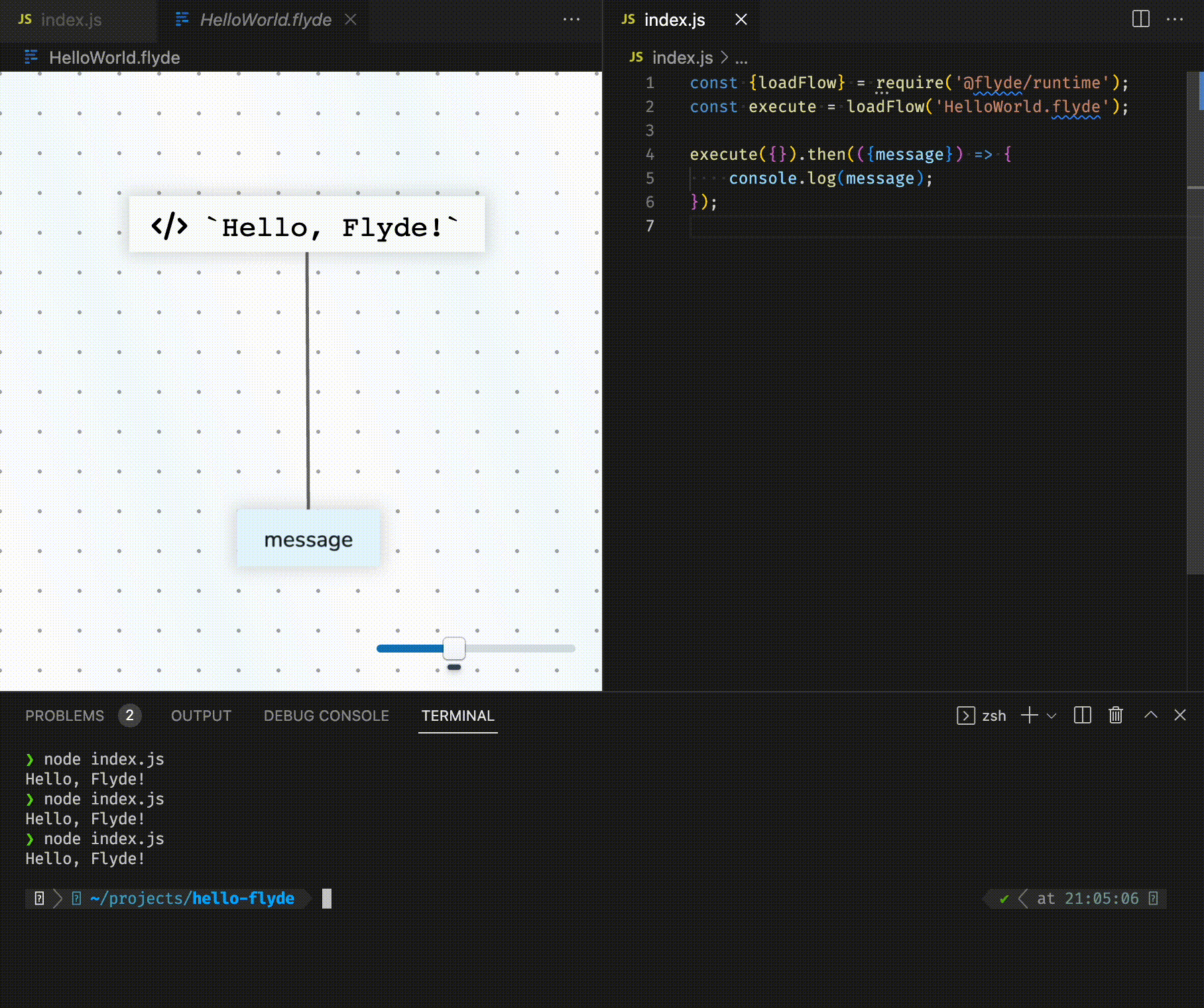
Bonne nouvelle ! Flyde, un nouvel outil de programmation visuelle pour les développeurs, vient de sortir en Alpha et ça déchire grave !
Bon, je vous vois venir : « Encore un énième outil low-code à la mode… » Que nenni ! Flyde est vraiment unique et a été conçu pour s’intégrer parfaitement à votre base de code existante, que ce soit pour du back-end, du front, des scripts d’automatisation ou même des outils en ligne de commande.
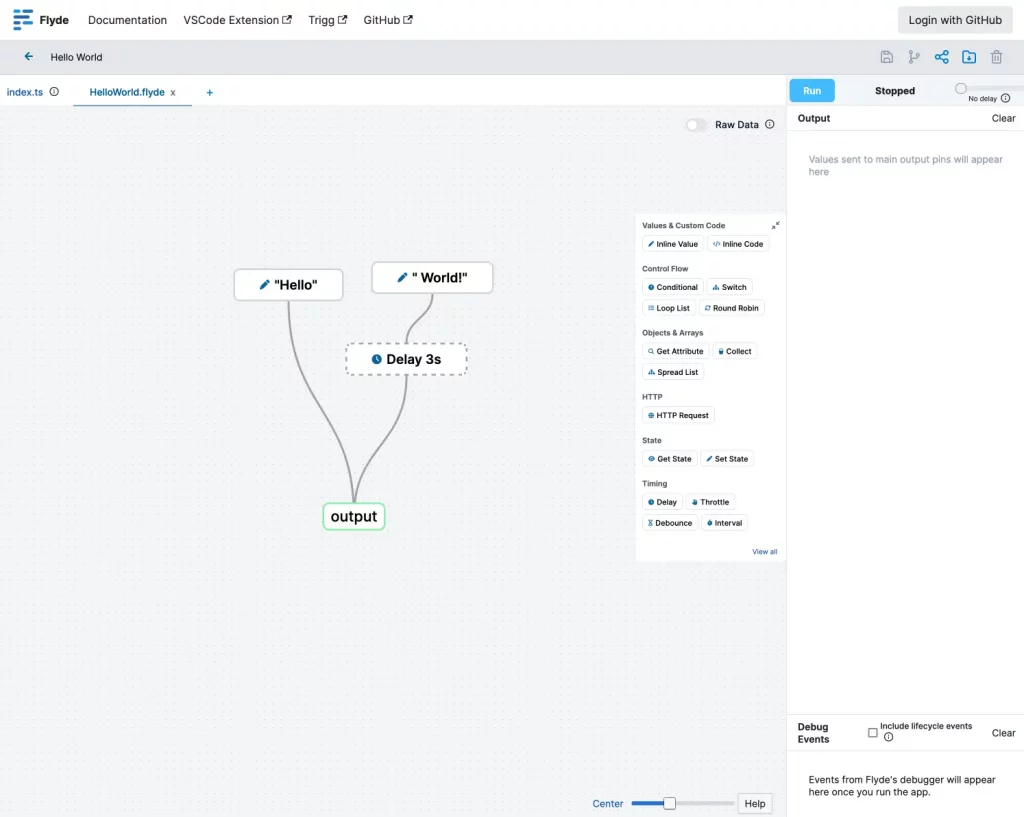
Le truc de ouf avec Flyde, c’est qu’il permet de visualiser et de créer facilement les flux haut-niveau (flows en anglais) de votre application, tout en gardant votre code textuel pour ce qui est bas-niveau. En gros, il sublime votre code « de plomberie » qui intègre plusieurs API de manière hyper concurrente. Vos diagrammes sur Powerpoint deviennent enfin une réalité !
Et les avantages sont multiples :
La collaboration avec les profils non-dev (product owners, QA, support…) devient hyper intuitive. C’est comme si Zapier et votre base de code avaient un bébé !
Les flux servent de documentation vivante et toujours à jour pour les nouveaux membres de l’équipe.
La programmation visuelle ouvre de nouveaux modes de réflexion sur le code. Les nœuds s’illuminent même quand les données les traversent, c’est hypnotique !
Et les données de monitoring sont directement sur le « code » lui-même. Ainsi, le débogage n’a jamais été aussi rapide.
Mais alors comment ça marche ce truc ?
Et bien Flyde est composé d’un éditeur visuel (extension VS Code ou standalone), d’une bibliothèque d’exécution et d’une bibliothèque plutôt bien fournie de composants prêts à l’emploi.
Dans l’éditeur visuel, on construit des flux en connectant des nœuds via une interface « nodes-and-wires ». On peut alors mixer des nœuds customs et ceux de la bibliothèque de composants. Une fois un flux créé, on peut ensuite l’exécuter depuis son code en utilisant la bibliothèque d’exécution de Flyde. Et c’est là que la magie opère !
Car Flyde ne cherche pas à remplacer vos workflows existants mais à les sublimer. Contrairement à d’autres outils low-code qui vivent en dehors de votre base de code, Flyde s’y intègre complètement. Les fichiers de flux sont committés dans votre gestionnaire de version comme n’importe quel autre fichier, les branches, les pull requests, les revues de code fonctionnent de manière transparente, les flux sont exécutés depuis votre base de code, en réutilisant votre environnement de prod. Comme ça, pas besoin de gérer une plateforme externe ni de vous soucier de la sécurité. Enfin, ces même flux peuvent être testés avec vos frameworks de test habituels. Vous pouvez même écrire des tests en Flyde qui testent votre code traditionnel !
L’intégration avec le code existant se fait de deux manières astucieuses : Premièrement, les noeuds Flyde peuvent être des noeuds visuels ou des noeuds basés sur du code. On peut donc wrapper n’importe quelle fonction de sa base de code dans un noeud Flyde utilisable dans un flux.
Secondo, les flux de Flyde peuvent s’exécuter depuis votre code. Par exemple, si vous construisez my-cool-flow.flyde, il faudra appeler execute('my-cool-flow') dans votre code puis gérer la réponse. Les cas d’usage sont infinis : Gestionnaire de requêtes HTTP, bot, scripts, etc.
Bon, vous l’aurez compris, Flyde s’inspire des principes de programmation basée sur les flux (FBP) mais d’autres outils font déjà ça, comme Node-RED ou NoFlo, bien avant l’arrivée du bouzin.
Quelle est la plus-value de Flyde du coup ?
Déjà, Flyde adopte une approche plus pragmatique et simple que NoFlo qui était un poil trop inspiré par la vision puriste de J. Paul Morrison, l’inventeur du FBP. Ensuite, l’éditeur est une extension VS Code, donc intégré à votre IDE, alors que les autres ont des éditeurs indépendants voire carréement datés. Et surtout Flyde est davantage taillé pour coexister avec les bases de code traditionnelles et toucher un public de développeurs plus large sur des projets variés.
Si vous voulez vous faire la main sur Flyde, le mieux est d’aller direct sur la sandbox en ligne qui permet de créer et d’exécuter des flux dans le navigateur. Puis jetez un œil aux tutos pour intégrer Flyde dans un vrai projet.
Perso, je vois plusieurs cas d’usage hyper prometteurs pour Flyde. C’est d’abord un super accélérateur pour les juniors et les non-devs qui pourront prototyper rapidement des trucs qui claquent sans se prendre la tête. Ca permet également de booster la collaboration en ouvrant sa base de code aux gens du marketing ou à l’équipe produit.
De plus, c’est un formidable outil pédagogique aussi ludique que scratch pour enseigner des concepts de programmation avancés aux étudiants. Sans oublier le gain de productivité pour les devs expérimentés qui aiment bien avoir une vue d’ensemble sur des architectures d’API ou de microservices complexes.
Bref, je suis convaincu que Flyde (ou un de ses futurs fork) va changer notre façon de coder dans les années à venir. Si vous couplez ça à l’IA, ça va faire un malheur.
Ça y est, la vénérable sonde spatiale Voyager 1 de la NASA refait parler d’elle ! Après des mois de silence radio qui ont fait transpirer les ingénieurs, notre exploratrice de l’espace lointain a enfin daigné donner de ses nouvelles puisque pour la première fois depuis le 14 novembre 2023, elle renvoie des données utilisables sur l’état de santé de ses systèmes embarqués. Ils respirent mieux à la NASA.
Il faut dire que la mission nous a offert quelques sueurs froides ces derniers temps car depuis cette date, elle continuait bien à recevoir et exécuter les commandes envoyées depuis la Terre, mais impossible d’obtenir en retour des infos cohérentes sur son fonctionnement. Alors les enquêteurs du Jet Propulsion Laboratory de la NASA ont mené l’enquête et ont fini par identifier le coupable : un des trois ordinateurs de bord, le fameux « flight data subsystem » (FDS) responsable de la transmission des données, était en cause. Un seul circuit défectueux qui stocke une partie de la mémoire du FDS avec une portion cruciale du logiciel… et bim, panne générale avec perte des trames de données !
Pas évident de réparer ça à des milliards de kilomètres de distance et comme souvent, quand on ne peut pas changer le hardware, il faut ruser avec le software. L’équipe a alors élaboré un plan génial : découper le code incriminé et le stocker à des endroits différents de la mémoire du FDS. Un vrai casse-tête type jeu de « Mémory » pour recoller les morceaux correctement sans faire sauter la banque mémoire !
Puis banco ! Premier essai le 18 avril, ils transfèrent le nouveau code maison spécial « télémétrie de l’état des systèmes » dans la mémoire du FDS et environ 45 heures plus tard, en comptant les 22h30 de trajet aller-retour du signal radio, les ingénieurs reçoivent les précieuses données tant attendues.
Yes !!! Voyager 1 est de retour aux affaires et recommence à parler de sa santé !
Regardez comme ils sont contents à la NASA :
Outre le soulagement de voir la communication rétablie, c’est une belle prouesse technique et un formidable pied-de-nez à l’obsolescence programmée. Pas mal pour une sonde lancée en 1977 et qui fête ses 46 ans ! Quand on vous dit que le matériel était bien meilleur à l’époque. 😉😜
Maintenant l’équipe du JPL va pouvoir se consacrer aux prochaines étapes à savoir relocaliser petit à petit les autres bouts de code du FDS pour retrouver une configuration nominale, puis renouer avec la transmission des données scientifiques et le but premier de la mission, à savoir explorer les confins de l’espace interstellaire !
Pendant ce temps, sa petite sœur Voyager 2, lancée 16 jours plus tard en 1977, poursuit tranquillement sa route aux frontières du système solaire sans faire de vagues. Une fiabilité à toute épreuve pour ces deux merveilles technologiques qui auront marqué l’histoire de l’exploration spatiale qui avant même de s’aventurer dans le « grand vide » interstellaire, nous ont offert des clichés époustouflants de Jupiter, Saturne, Uranus et Neptune.
Et qui sait, peut-être qu’un jour, elle captera peut-être un signal extraterrestre ou tombera nez-à-nez avec une civilisation alien super évoluée technologiquement…
Mercedes secoue le monde automobile avec le lancement de Drive Pilot aux États-Unis, le premier système de conduite autonome de niveau 3 commercialisé directement auprès des consommateurs. Ça y est les amis, le futur nous rattrape ! Bientôt, on pourra enfin lâcher le volant et vaquer à d’autres occupations pendant les longs trajets…
Concrètement, dans certaines conditions bien spécifiques, Drive Pilot permet au conducteur de détourner son attention de la route pour se concentrer sur des activités non liées à la conduite, comme consulter ses mails, surfer sur internet ou regarder un film. Mais attention, il faudra toujours rester prêt à reprendre le contrôle du véhicule à tout moment si nécessaire. J’imagine qu’en cas de problème, la voiture saura vous tirer de votre session de TikTok avec des bip bip.
Pour cela, Drive Pilot s’appuie sur une multitude de capteurs ultra-perfectionnés : caméras, radars, LiDAR, capteurs à ultrasons… Un véritable concentré de technologies de pointe pour analyser l’environnement en temps réel. Un puissant ordinateur de bord exploite ensuite toutes ces données pour prendre les meilleures décisions de conduite de manière autonome.
Il y a cependant quelques conditions à respecter pour pouvoir activer Drive Pilot : Le système ne peut être utilisé que sur certaines portions d’autoroutes spécifiques, avec un marquage au sol suffisamment clair et visible, une densité de trafic modérée à élevée et une vitesse limitée à 60 km/h. Ça fait beaucoup de conditions à la con quand même.
Le conducteur doit aussi rester visible par la caméra située au-dessus de l’écran conducteur. On est donc encore loin d’une conduite 100% autonome en toutes circonstances, mais c’est un premier pas très prometteur ! Pour l’instant, seuls les propriétaires des dernières Mercedes Classe S et EQS pourront profiter de Drive Pilot, moyennant un abonnement annuel à 2500$ (lol). Bref, c’est une technologie encore réservée à une élite friquée, mais on peut espérer que Mercedes la démocratisera rapidement sur des modèles plus abordables.
Malgré ses limitations actuelles, Drive Pilot représente une avancée majeure vers une conduite plus sûre, plus confortable et plus… productive. Fini le stress des embouteillages, ce temps pourra être mis à profit pour avancer sur son travail, discuter avec ses proches ou se détendre devant un bon film. Tout ça pendant que l’IA gère la conduite de manière sereine et vigilante.
Bien sûr, de nombreux défis restent encore à relever avant de voir des voitures 100% autonomes partout sur nos routes. Les questions de responsabilité juridique en cas d’accident, de sécurité face au piratage ou encore d’éthique et de contrôle humain sont complexes. Et il faudra aussi s’assurer de la fiabilité totale du système pour éviter tout bug ou panne aux conséquences potentiellement dramatiques.
Mais une chose est sûre, la conduite autonome sera l’un des enjeux majeurs de la mobilité du futur. Avec des acteurs de poids comme Comma, Mercedes, Tesla ou Waymo qui investissent massivement sur le sujet, on peut s’attendre à des progrès rapides et à une démocratisation progressive de cette technologie dans les années à venir.