En ce moment, les développeurs s’extasiaient sur un truc appelé Jujutsu, ou “jj” pour les intimes. Au début, j’ai cru à une énième tentative de réinventer la roue puis j’ai creusé, et j’ai compris pourquoi ça fait autant parler.
Vous connaissez cette frustration avec Git ? Quand vous galérez avec l’index, que vous oubliez de stash vos modifs avant de changer de branche, ou que vous priez pour ne pas foirer votre rebase ? Eh bien, Martin von Zweigbergk, ingénieur chez Google et ancien contributeur Mercurial, a décidé qu’on méritait mieux.
Du coup, il a créé Jujutsu, un système de contrôle de version qui garde tous les avantages de Git en supprimant ses complexités.
Le principe de Jujutsu tient en une phrase : votre répertoire de travail EST un commit. Poh Poh Poh !!
Pour installer jj, vous avez plusieurs options selon votre OS. Sur macOS avec Homebrew :
brew install jj
Sur Linux, utilisez le gestionnaire de paquets de votre distribution ou installez via Cargo :
# Via Cargo (nécessite Rust)
cargo install --locked jj
# Sur Arch Linux
pacman -S jujutsu
# Sur NixOS
nix-env -iA nixpkgs.jujutsu
Sur Windows, utilisez Winget ou Scoop :
# Via Winget
winget install --id martinvonz.jj
# Via Scoop
scoop bucket add extras
scoop install jujutsu
Une fois installé, configurez votre identité (comme avec Git) :
jj config set --user user.name "Votre Nom"
jj config set --user user.email "[email protected]"
Premiers pas avec Jujutsu
Pour initialiser un nouveau repo jj ou coexister avec un repo Git existant :
# Créer un nouveau repo jj
jj git init myproject
# Coexister avec un repo Git existant
cd existing-git-repo
jj git init --git-repo=.
# Cloner un repo Git avec jj
jj git clone https://github.com/user/repo.git
Concrètement, ça change tout. Plus besoin de git add, plus de git stash avant de changer de contexte, plus de commits temporaires pour sauvegarder votre travail en cours. Jujutsu traite votre copie de travail comme n’importe quel autre commit dans l’historique, ce qui simplifie drastiquement le modèle mental.
Voici les commandes de base pour travailler avec jj :
# Voir l'état actuel (équivalent de git status + git log)
jj st
jj log
# Créer une nouvelle branche de travail
jj new -m "Début de ma nouvelle feature"
# Modifier des fichiers (pas besoin de git add !)
echo "Hello Jujutsu" > README.md
# Les changements sont automatiquement suivis
# Voir les modifications
jj diff
# Créer un nouveau commit basé sur le précédent
jj new -m "Ajout de la documentation"
# Revenir au commit précédent
jj edit @-
# Naviguer dans l'historique
jj edit <change-id></change-id>
Gestion des conflits façon Jujutsu
Le système gère aussi les conflits différemment car là où Git vous force à résoudre immédiatement,
jj peut sauvegarder les conflits directement dans l’arbre de commits
, sous forme de représentation logique plutôt que de marqueurs textuels. Vous pouvez donc reporter la résolution et vous en occuper quand vous avez le temps. Une fois résolu, jj propage automatiquement la solution aux commits descendants.
# Merger deux branches (les conflits sont sauvegardés si présents)
jj new branch1 branch2
# Voir les conflits
jj st
# Les conflits sont stockés dans le commit, vous pouvez continuer à travailler
jj new -m "Travail sur autre chose pendant que le conflit existe"
# Revenir résoudre le conflit plus tard
jj edit <conflict-commit-id>
# Après résolution manuelle
jj squash # Pour intégrer la résolution</conflict-commit-id>
Manipulation de l’historique
L’outil brille aussi par sa puissance d’annulation. L’operation log dépasse largement les reflogs de Git en gardant une trace atomique de toutes les modifications de références simultanément. Comme ça, vous pouvez expérimenter sans crainte, sachant qu’un simple jj undo peut rattraper n’importe quelle erreur.
# Voir l'historique des opérations
jj op log
# Annuler la dernière opération
jj undo
# Revenir à un état précédent spécifique
jj op restore <operation-id>
# Réorganiser des commits (équivalent de rebase interactif)
jj rebase -s <source> -d <destination>
# Éditer un commit ancien
jj edit <change-id>
# Faire vos modifications
jj squash # Pour intégrer dans le commit actuel
# Split un commit en plusieurs
jj split</change-id></destination></operation-id>
Workflow quotidien avec Jujutsu
Voici un exemple de workflow typique pour une journée de développement :
# Commencer une nouvelle feature
jj new main -m "feat: ajout authentification OAuth"
# Travailler sur les fichiers
vim auth.js
vim config.js
# Pas besoin de git add ! Les changements sont auto-trackés
jj diff # Voir ce qui a changé
# Créer un checkpoint pour continuer
jj new -m "wip: OAuth provider setup"
# Oh, un bug urgent à fix sur main !
# Pas besoin de stash, on switch directement
jj new main -m "fix: correction crash login"
# Fix le bug
vim login.js
# Revenir à notre feature OAuth
jj edit @- # Revient au commit précédent
# Finaliser la feature
jj describe -m "feat: authentification OAuth complète"
# Pusher vers Git
jj git push
Intégration avec Git
Côté compatibilité, c’est du 100% Git. Jujutsu utilise les dépôts Git comme backend de stockage, ce qui signifie que vos collègues peuvent continuer avec Git classique sans même savoir que vous utilisez jj. Et si vous changez d’avis, supprimez juste le dossier .jj et tout redevient normal.
# Synchroniser avec le remote Gitjjgitfetch# Pusher vos changementsjjgitpush# Créer une branche Git depuis un change jjjjbranchcreatema-featurejjgitpush--branchma-feature# Importer les changements depuis Gitjjgitimport# Exporter vers Git (automatique généralement)jjgitexport
Commandes avancées utiles
Selon les retours d’utilisateurs
, même les experts Git qui maîtrisent parfaitement les rebases complexes découvrent qu’ils n’ont plus peur de manipuler l’historique. Réordonner des commits, corriger une modification ancienne, jongler avec plusieurs branches non mergées… tout devient trivial avec jj.
# Voir l'historique en mode graphique
jj log --graph
# Chercher dans l'historique
jj log -r 'description(regex:"fix.*bug")'
# Travailler avec plusieurs parents (merge commits)
jj new parent1 parent2 parent3
# Abandonner des changements locaux
jj abandon <change-id>
# Dupliquer un commit ailleurs
jj duplicate <change-id> -d <destination>
# Voir les changements entre deux commits
jj diff -r <from> -r <to>
# Créer un alias pour une commande fréquente
jj config set --user alias.l 'log --graph -r "ancestors(., 10)"'
jj l # Utilise l'alias</to></from></destination></change-id></change-id>
Configuration et personnalisation
Pour personnaliser jj selon vos besoins :
# Définir votre éditeur préféré
jj config set --user ui.editor "code --wait"
# Activer les couleurs dans le terminal
jj config set --user ui.color "always"
# Configurer le format de log par défaut
jj config set --user ui.default-revset "@ | ancestors(@, 10)"
# Voir toute la configuration
jj config list --user
# Éditer directement le fichier de config
jj config edit --user
Le projet évolue rapidement et l’équipe travaille sur plusieurs backends, y compris un natif qui pourrait dépasser Git en performance sur de gros dépôts.
Évidemment, Jujutsu reste expérimental. L’écosystème est plus petit, les intégrations IDE limitées (bien qu’il y ait déjà des extensions VSCode et Vim), et la terminologie différente demande un temps d’adaptation. Mais pour ceux qui cherchent une approche plus intuitive du contrôle de version, ça vaut franchement le détour.
Pour aller plus loin, je vous conseille de parcourir le
tutoriel officiel
qui couvre des cas d’usage plus avancés, ou de rejoindre le
Discord de la communauté
où les développeurs sont très actifs et répondent aux questions.
Bref, vous l’aurez compris,
jj ne remplace pas Git dans l’immédiat
. Il le sublime en gardant la compatibilité totale. C’est une approche intelligente qui permet d’adopter progressivement un workflow plus fluide sans perturber les équipes de dev.
Vous la connaissez cette fatigue de quand vous lancez votre serveur de dev et que ce satané message d’erreur EADDRINUSE vous annonce que le port 3000 est déjà utilisé ? Et bien moi oui, et visiblement je ne suis pas le seul puiqu’un développeur de talent a décidé que c’était la goutte d’eau et a créé Port Kill, une petite app macOS qui vit tranquillement dans votre barre de menu et qui surveille les ports ouverts comme le vigile de Franprix vous surveille.
Comme ça, au lieu de jouer au jeu du chat et de la souris avec lsof, netstat et kill dans votre terminal, Port Kill scanne automatiquement tous les ports entre 2000 et 6000 toutes les 5 secondes et vous dit ce qui est ouvert. Alors pourquoi cette plage ? Hé bien parce que c’est là que la plupart d’entre nous faisons tourner nos serveurs de développement. React sur 3000, Vue sur 8080, votre API custom sur 5000… Vous voyez le tableau.
Ce qui est sympa avec Port Kill, c’est l’interface. L’icône dans la barre de menu change de couleur selon le nombre de processus détectés. Vert quand tout est clean, rouge quand vous avez entre 1 et 9 processus qui traînent, et orange quand ça part en cacahuète avec plus de 10 processus. Un clic sur l’icône et vous avez la liste complète avec la possibilité de tuer chaque processus individuellement ou de faire table rase d’un coup.
Techniquement, c’est du solide puisque c’est écrit en Rust (hé oui parce qu’en 2025, si c’est pas du Rust, c’est has-been), l’app utilise les commandes système lsof pour détecter les processus. Et la stratégie de kill de l’outil est plutôt intelligente puisqu’il fait d’abord un SIGTERM poli pour demander gentiment au processus de se barrer, et si au bout de 500ms ce dernier fait le têtu, PAF, un SIGKILL dans les dents. C’est la méthode douce-ferme, comme quand vous demandez à votre chat de descendre du clavier.
Le contexte, c’est qu’on a tous galéré avec ça.
L’erreur EADDRINUSE
est un classique du dev web. Vous fermez mal votre serveur avec Ctrl+C, ou pire, vous fermez juste la fenêtre du terminal, et hop, le processus continue de tourner en arrière-plan comme un zombie. Sur macOS, c’est encore plus vicieux depuis Monterey avec AirPlay qui squatte le port 5000 par défaut.
Il existe d’autres solutions, bien sûr. Par exemple,
Killport
est autre un outil en ligne de commande cross-platform écrit aussi en Rust qui fait un job similaire.
kill-my-port
est un package npm qui fait la même chose. Mais ces outils nécessitent de passer par le terminal à chaque fois. Port Kill, lui, est toujours là, discret dans votre barre de menu, prêt à dégainer.
L’installation est simple : vous clonez le repo GitHub, un petit cargo build --release si vous avez Rust installé, et vous lancez avec ./run.sh. L’app tourne en tâche de fond, consomme quasi rien en ressources, et met à jour son menu contextuel toutes les 3 secondes. Pas de fenêtre principale, pas de configuration compliquée, juste l’essentiel.
Pour les puristes du terminal, oui, vous pouvez toujours faire lsof -ti:3000 | xargs kill -9. Mais franchement, avoir une interface graphique pour ce genre de tâche répétitive, c’est pas du luxe. Surtout quand vous jonglez entre plusieurs projets et que vous ne vous rappelez plus quel port utilise quoi.
Le seul bémol, c’est que c’est limité à macOS pour l’instant donc les développeurs sur Linux et Windows devront se contenter des alternatives en CLI. Mais bon, vu que le code est open source, rien n’empêche quelqu’un de motivé de faire un portage.
Voilà, donc si comme moi vous en avez marre de cette danse répétitive pour trouver et tuer le processus qui squatte votre port,
Port Kill
mérite que vous y jetiez un oeil.
Si comme moi, vous jonglez avec une dizaine de serveurs SSH différents et que votre fichier ~/.ssh/config ressemble à un roman de Marcel Proust, je vous ai trouvé un petit outil bien sympa qui pourrait vous faciliter grandement la vie. Ça s’appelle SSH-List et c’est un gestionnaire de connexions SSH codé en Rust et équipé d’une jolie une interface TUI (Text User Interface) plutôt bien pensée.
Ce qui me plaît avec SSH-List, c’est sa philosophie minimaliste car contrairement à certains mastodontes comme
Termius
,
Tabby
ou
SecureCRT
qui essaient de tout faire, lui reste focus sur l’essentiel, à savoir gérer vos connexions SSH, point. Et pour beaucoup d’entre nous qui passons notre vie dans le terminal au détriment de notre famille, c’est exactement ce qu’il nous faut.
L’outil a été développé par Akinoiro et propose toutes les fonctionnalités de base dont vous avez besoin telles que ajouter, éditer, copier et trier vos connexions SSH. Vous pouvez même définir des options SSH personnalisées et exécuter des commandes directement sur vos hôtes distants. Et cerise sur le gâteau, il peut importer automatiquement vos hôtes existants depuis votre fichier ~/.ssh/config.
Pratique pour migrer en douceur.
Un point sécurité qui mérite d’être souligné c’est que SSH-List ne stocke aucun mot de passe. L’outil vous encourage même à utiliser des clés SSH pour l’authentification, ce qui est de toute façon la bonne pratique à adopter en 2025. Toute votre configuration est sauvegardée dans un simple fichier JSON ici ~/.ssh/ssh-list.json, donc vous gardez le contrôle total sur vos données.
Maintenant, pour l’installation, vous avez l’embarras du choix. Si vous êtes sur Arch Linux, un petit paru -S ssh-list via l’AUR et c’est réglé. Sur Ubuntu ou Linux Mint, il y a un PPA dédié :
Pour les puristes ou ceux sur d’autres distributions, vous pouvez l’installer via Cargo (le gestionnaire de paquets Rust) avec un simple cargo install ssh-list, ou compiler directement depuis les sources si vous êtes du genre à aimer avoir la main sur tout.
L’interface TUI est vraiment intuitive. Vous naviguez dans votre liste de connexions avec les flèches, vous appuyez sur Entrée pour vous connecter, et vous avez des raccourcis clavier pour toutes les actions courantes. C’est simple, efficace, et ça reste dans l’esprit terminal qu’on aime tant.
Ce qui différencie SSH-List des autres gestionnaires de connexions SSH disponibles, c’est justement cette approche sans chichi. Pas de fonctionnalités inutiles, pas d’interface graphique lourde, juste ce qu’il faut pour bosser efficacement. C’est un peu l’antithèse de solutions comme
MobaXterm
ou
mRemoteNG
qui essaient de gérer tous les protocoles possibles et imaginables.
Si vous cherchez une alternative légère à des outils comme
sshs
ou sgh (qui font à peu près la même chose mais avec des approches différentes), SSH-List mérite également le détour et le fait qu’il soit écrit en Rust garantit des performances au top et une utilisation mémoire minimale. Deux points non négligeables quand on passe sa journée avec 50 onglets de terminal ouverts.
Alors non, SSH-List ne va pas changer drastiquement votre façon de travailler, mais il va clairement la simplifier.
Vous recevez un fichier Word et votre premier réflexe, en bon libriste, c’est de lancer LibreOffice qui met 30 minutes à démarrer, juste pour lire trois paragraphes. Ou pire, vous êtes en SSH sur un serveur et là, c’est le drame total, impossible de lire un doc Word là bas. Hé bien ce bon Ben Greenwell en a eu marre de cette galère et a créé doxx, un outil écrit en Rust qui affiche vos .docx directement dans le terminal.
Ce concept m’a rappelé
Glow
, vous savez, ce magnifique renderer Markdown pour terminal créé par l’équipe de Charm, sauf qu’ici, on s’attaque à un format bien plus casse-pieds : les fichiers Word.
Doxx gère donc non seulement le texte formaté, mais aussi les tableaux avec de jolies bordures Unicode, les listes, et même les images si votre terminal le supporte (Kitty, iTerm2, WezTerm). Et comme c’est écrit en Rust, il parse le XML des fichiers .docx en un clin d’œil.
Pour utiliser l’outil, rien de plus simple :
doxx rapport.docx
Et boom, votre document s’affiche. Vous cherchez quelque chose ?
doxx contrat.docx --search "paiement"
Et il vous surligne toutes les occurrences. Il peut aussi exporter vers d’autres formats comme le Markdown, le CSV pour les tableaux, le JSON pour les devs, ou du plain text pour les puristes.
Pour l’installer, si vous êtes sur macOS avec Homebrew, c’est
brew install doxx
Et pour les rustacés :
cargo install doxx
Les utilisateurs d’Arch ont leur paquet AUR, et il y a même une option Nix et Conda. Bref, peu importe votre setup, vous devriez pouvoir l’installer.
Alors comment ce truc fonctionne pour afficher le format de Microsoft dans le terminal. Et bien c’est simple vous allez voir. En fait, les fichiers .docx sont des archives ZIP contenant du XML. Donc techniquement, vous pourriez les dézipper et parser le XML vous-même avec sed ou awk. Mais qui a envie de faire ça ?
C’est pourquoi doxx utilise la bibliothèque docx-rs pour le parsing, ratatui pour l’interface terminal interactive, et viuer pour l’affichage des images. Bref, c’est solide. Il y a même déjà un port en Go créé par keskinonur qui maintient la parité des fonctionnalités.
Alors oui,
Doxx
ce n’est pas un éditeur mais juste un viewer mais je trouve quand même que c’est bien pratique ! Donc si vous en avez marre de lancer des applications lourdes juste pour consulter un fichier Word, cet outil mérite clairement le détour.
Hier soir, j’ai découvert un outil qui m’aurait évité des dizaines de commits “fix CI”, “fix CI again”, “please work this time” sur GitHub. J’sais pas si vous aussi vous connaissez cette galère ? Vous modifiez votre workflow GitHub Actions, vous poussez, ça plante, vous corrigez, vous repoussez, ça replante… Bref, votre historique Git ressemble à un journal de débugging en temps réel.
Et heureusement, wrkflw vient mettre fin à ce cauchemar.
Ce petit outil codé en Rust vous permet en fait de valider et d’exécuter vos GitHub Actions directement sur votre machine, sans avoir besoin de pusher quoi que ce soit. L’outil vient d’être annoncé sur le forum Rust et ça va bien aider tout le monde je pense.
Grâce à lui, au lieu de tester vos workflows dans le cloud GitHub (et potentiellement faire planter votre CI/CD devant toute l’équipe… La te-hon…), vous les exécutez localement. Wrkflw parse alors votre fichier YAML, résout les dépendances entre jobs, et lance tout ça soit dans Docker/Podman pour matcher l’environnement GitHub, soit en mode émulation si vous n’avez pas de runtime container sous la main.
Ce qui rend wrkflw vraiment pratique, c’est son interface TUI (Terminal User Interface) qui vous permet de visualiser l’exécution en temps réel. Un simple wrkflw tui et vous avez un dashboard interactif où vous pouvez suivre vos jobs, voir les logs, et comprendre ce qui foire sans avoir à jongler entre 15 onglets GitHub.
L’installation se fait en deux secondes si vous avez Rust :
cargo install wrkflw
Le package est aussi dispo sur crates.io et une fois installé, vous pouvez valider un workflow avec la commande :
wrkflw validate .github/workflows/rust.yml
ou le lancer directement avec
wrkflw run .github/workflows/ci.yml
L’outil détectera automatiquement tous vos workflows et les chargera dans l’interface.
Ce qui est fort avec wrkflow, c’est surtout le support quasi-complet des fonctionnalités de GitHub Actions. Les Matrix builds ? Ça passe ! Les Container actions ? Bah ouais, pas de problème ! Tout ce qui est JavaScript actions ? Check ! Même chose pour les Composite actions et les workflows réutilisables et même les fichiers d’environnement GitHub sont supportés. Bon, il y a quelques limitations évidemment. Vous ne pouvez pas par exemple mettre de secrets GitHub (ce qui est logique), et y’a pas de support Windows/macOS runners, ni pas d’upload/download d’artifacts. Mais pour 90% des cas d’usage, c’est largement suffisant.
Wrkflw s’inscrit dans une tendance plus large d’outils qui cherchent à remplacer Make et ses Makefiles cryptiques. Je pense par exemple à Task (Taskfile) qui est un autre exemple populaire, écrit en Go avec une syntaxe YAML plus moderne ou encore à Act, un autre outil open source qui fait à peu près pareil. Les développeurs cherchent clairement des alternatives plus lisibles et maintenables et wrkflw va encore plus loin en se spécialisant sur GitHub Actions.
Le mode Docker/Podman de wrkflw permet par exemple de créer des containers qui matchent au plus près l’environnement des runners GitHub. Et si jamais vous interrompez l’exécution avec Ctrl+C, pas de panique, puisque l’outil nettoie automatiquement tous les containers créés. Comme ça, y’aura plus de containers zombies qui traînent après vos tests.
Et pour tous ceux qui bossent en mode émulation sécurisée (sans Docker), wrkflw exécute les actions dans un environnement sandboxé. C’est moins fidèle à l’environnement GitHub mais au moins ça permet de tester rapidement sans avoir besoin d’installer Docker. Pratique sur des machines de dev légères ou des environnements restrictifs.
Le workflow de test devient donc le suivant : 1/ Vous modifiez votre YAML. 2/ Vous lancez wrkflw run . 3/ Vus voyez immédiatement si ça marche. 4/ Vous corrigez si besoin. 5/ Et c’est seulement ensuite que vous poussez sur GitHub. Plus de commits de debug, plus de CI cassée, plus de collègues qui râlent parce que la pipeline est tout rouge ^^.
L’outil est encore jeune bien sûr mais déjà très prometteur. Les prochaines versions devraient ajouter le support des secrets locaux, une meilleure intégration avec GitLab CI, et peut-être même le support des runners Windows/macOS.
Bref, si vous gérez des workflows GitHub Actions complexes, wrkflw va rapidement devenir indispensable à votre life.
Regarder Star Wars en version Despecialized ou le premier Jurassic Park sur un écran géant dans mon salon, c’est un peu retrouver son âme d’enfant. Et c’est exactement ce que j’ai fait ces dernières semaines avec le XGIMI Aura 2 que j’ai reçu en test.
Le truc qui m’a le plus impressionné avec ce projecteur ultra courte focale (UST - Ultra Short Throw), c’est qu’il suffit de le poser à environ 17 / 18 cm du mur pour obtenir une image de 100 pouces (2,54 m de diagonale). Plus besoin de câbles qui traînent partout, plus de projo pendu au plafond qui fait peur aux invités… Ça me change de mon ancien. Là, on le pose sur le meuble TV, et basta. (Bon, j’avoue, j’ai pas encore acheté le meuble TV…).
Un petit détail dont on parle rarement quand même avec ce genre de projo, c’est que comme la lumière arrive de façon rasante, la texture du mur se voit et ça donne un petit grain. Je fixais dessus au début, puis on s’y fait. Donc si vous êtes perfectionnistes, une toile ALR spéciale UST (type Fresnel) ou une peinture très lisse règle ce “problème” et améliorera aussi le contraste en lumière ambiante.
Côté image, le Aura 2 exploite la techno Dual Light 2.0 (hybride LED + laser) pour sortir 2300 lumens ISO et ainsi couvrir 99 % du DCI-P3. En clair, ça donne des couleurs bien pétantes et suffisamment de pêche pour regarder en journée (rideaux tirés, c’est mieux quand même). La puce 0,47” DMD affiche l’image 4K via wobulation, ce qui n’est pas du vrai 4K natif, mais honnêtement, à l’usage, on ne voit pas la différence. Et la plage de taille conseillée par XGIMI s’étends de 90 à 150”, le mieux étant 100/120”.
Autre bonne surprise dans ce projo, c’est la prise en charge de Dolby Vision, HDR10, HLG et mode IMAX Enhanced, comme ça le contraste dynamique annoncé grimpe à 1 000 000:1. Maintenant, dans la vraie vie, on n’atteint pas les noirs d’une OLED, mais pour un UST, ça fait le job.
Dessus, c’est Android TV 11.0 (pas Google TV). J’ai trouvé l’interface plutôt fluide**, par contre, pas de Netflix natif** (question de certification) alors il faudra passer par un boîtier externe (Apple TV, Chromecast/Google TV, Fire TV…) ou bidouiller. Disney+ est dispo selon les régions et versions, mais pour avoir toutes les plateformes, le plus simple reste comme je vous le disais d’y adjoindre un petit streamer HDMI.
Un gros point fort de ce projo c’est une barre Harman Kardon 60 W intégrée (4 x 15 W) avec Dolby Atmos, DTS-HD et DTS Virtual:X. Pour Netflix & chill (ou L’Amour est dans le pré), c’est largement suffisant. Après si vous voulez aller plus loin, il y a une sortie HDMI eARC pour brancher un ampli ou une barre externe.
Notez que la barre blanche que vous voyez devant le projo, c’est ma barre de son, et elle n’est pas livrée avec…
En mode Jeu, j’ai une latence autour de 20 ms, ce qui est très bon pour un projecteur. Mon astuce, c’est de désactivez l’auto keystone pour profiter du plus faible input lag. Pas de VRR ni 120 Hz en 4K, donc on reste sur du 60 Hz pour les consoles. Je me suis fait quelques parties de Mario Kart sur la Switch 2, là dessus, c’était quand même pas mal.
Niveau connectique, on peut y mettre 3 x HDMI (dont 1 eARC), 3 x USB, Ethernet, optique, jack 3,5 mm. Y’a également du Wi-Fi 6, Bluetooth 5.2, Chromecast intégré, 3D (Frame Packing & Side-by-Side). Le tout avec un capot motorisé qui protège l’optique, un Art Mode pour afficher des œuvres quand on n’utilise pas le projo, et l’ISA 5.0 (autofocus, auto-keystone continu, correction de planéité du mur, adaptation à la couleur du mur, alignement auto avec l’écran, etc.).
Bien sûr, ce n’est pas “portable” puisque ce projecteur mesue 51 cm de large, 27 cm de profondeur, 14,4 cm de haut pour environ 9 kg. Et le bruit mesuré est ≤ 32 dB à 1 m (c’est donc discret par rapport à mon vieux BenQ qui soufflait plus qu’une documentaliste de collège). Et pour la conso, on est autour de 180 W en usage.
Maintenant, le tarif officiel en Europe est de 2 899 €. C’est cher mais face à lui y’a le Hisense PX3-Pro (tri-laser, Dolby Vision, Google TV avec Netflix) qu’on voit souvent entre 2 499–2 999 €, le Samsung The Premiere 9 (tri-laser) autour de 5 999 €, et le Formovie Theater Premium (Google TV + Netflix natif, DV, ALPD RGB+) annoncé à 2 999 €.
Niveau recul donc, le XGIMI est très bien placé avec un ratio 0,177:1 (100” à 17,8 cm), ce qui est plus court que pas mal de concurrents. Bref, j’ai bien aimé l’installation ultra simple, et surtout la qualité d’image et le son 60 W très propre. Le fait aussi que ça se coupe quand on approche sa grosse tête au dessus, c’est une excellente sécurité pour ne pas se prendre un coup de laser dans l’œil.
Par contre, dommage pour Netflix et j’ai trouvé aussi que la télécommande n’était pas hyper lisible dans le noir, ce qui peut être vite relou.
Bref, après plusieurs semaines d’utilisation, je suis conquis par ce XGIMI Aura 2. Donc si vous avez le budget et que vous voulez un UST plug-and-play qui envoie une vraie image de cinéma sans transformer le salon en salle machine avec des câbles partout, foncez.
C’est toujours marrant de voir des outils ultra populaires mettre des années à intégrer une fonctionnalité que tout le monde bricole depuis une éternité. Et aujourd’hui, c’est au tour de NGINX qui vient enfin de franchir le pas avec l’intégration native du protocole ACME !
Pour ceux qui ne seraient pas familiers avec cet acronyme, ACME (Automated Certificate Management Environment) c’est le protocole magique qui permet d’automatiser toute la gestion des certificats SSL/TLS. Développé à l’origine par l’Internet Security Research Group pour Let’s Encrypt, c’est donc lui qui vous évite de devoir renouveler manuellement vos certificats tous les 90 jours comme un moine copiste du Moyen Âge.
Le truc vraiment cool, c’est que NGINX a décidé de faire les choses en grand car plutôt que de bricoler une solution rapide, ils ont carrément développé un nouveau module baptisé ngx_http_acme_module qui s’appuie sur leur SDK Rust. Hé oui y’a du Rust dans NGINX ! Cette approche leur permet ainsi d’avoir un module dynamique disponible aussi bien pour la version open source que pour leur solution commerciale NGINX Plus.
Du coup, fini les scripts à la con avec Certbot qui tournent en cron et qui plantent au pire moment. Maintenant, vous configurez tout directement dans votre fichier NGINX comme ceci :
Simple, efficace, intégré, plus besoin de jongler entre différents outils, car tout se passe dans la configuration NGINX. Ensuite, les certificats se renouvellent automatiquement, s’installent tout seuls, et vous pouvez enfin dormir tranquille.
Mais attention, selon les discussions sur LWN.net, tout n’est pas rose au pays des bisounours… La communauté a quelques réserves, et pas des moindres. Leur plus gros point de friction c’est que NGINX a décidé de lancer cette première version avec uniquement le support du challenge HTTP-01. Pour les non-initiés, ça veut dire que votre serveur doit être accessible publiquement sur le port 80 pour prouver qu’il contrôle bien le domaine.
Les développeurs frustrés pointent aussi du doigt l’absence du challenge DNS-01. Et je trouve qu’ils ont raison d’être énervés car sans DNS-01, impossible de générer des certificats wildcard (*.example.com), et impossible de sécuriser des services internes qui ne sont pas exposés sur Internet. Donc pour tous ceux qui ont des homelabs ou des infrastructures privées, c’est relou.
Surtout que Caddy, le concurrent direct de NGINX, gère ça depuis des années sans problème. Bref, l’équipe NGINX promet que les challenges TLS-ALPN et DNS-01 arriveront dans le futur, mais pour l’instant, c’est motus et bouche cousue sur les délais.
Pour ceux qui veulent tester, sachez que le code est disponible sur GitHub et des packages précompilés sont déjà disponibles. La documentation officielle explique également bien le processus d’installation et de configuration. Notez que le module utilise une zone de mémoire partagée pour coordonner les renouvellements entre les différents workers NGINX, ce qui est plutôt malin pour éviter les conflits.
Au niveau technique, le workflow est assez classique… vous configurez votre serveur ACME (Let’s Encrypt ou autre), vous allouez la mémoire partagée nécessaire, vous configurez les challenges, et le module s’occupe du reste. Les variables $acme_certificate et $acme_certificate_key sont automatiquement remplies avec les chemins vers vos certificats.
Tout ceci permet de réduire également la surface d’attaque car vous n’avez plus besoin d’avoir Certbot et toutes ses dépendances Python qui traînent sur votre serveur ou plus de scripts externes qui doivent recharger NGINX. Tout est natif, et donc c’est forcément plus sécurisé.
Perso, je trouve que c’est un pas dans la bonne direction, même si l’implémentation actuelle est limitée. Et le faut qu’ils aient codé ça en Rust montre bien que NGINX prend au sérieux la modernisation de sa base de code. Du coup, pour ceux qui ont des besoins simples avec des domaines publics, foncez tester cette nouveauté. Plus d’excuses pour avoir des certificats expirés !
Ça vous dirait d’en savoir plus sur le gang de ransomware le plus innovant et le plus traître de l’histoire du cybercrime moderne ? BlackCat, aussi connu sous le nom d’ALPHV, c’est le groupe qui a sorti le premier ransomware majeur entièrement écrit en Rust, un langage de programmation que même les hipsters de la Silicon Valley trouvent cool. Mais leur véritable coup de maître ça a été d’avoir arnaqué leurs propres affiliés pour 22 millions de dollars avant de disparaître dans la nature comme des voleurs… de voleurs. Si vous pensiez que l’honneur entre criminels existait encore, et bien BlackCat va vous faire réviser votre jugement de fond en comble.
Pour comprendre l’ampleur de cette trahison, faut s’imaginer la scène. Vous êtes un cybercriminel chevronné, vous avez infiltré la plus grosse plateforme de paiement de santé américaine et vous êtes en train de négocier une rançon de 22 millions de dollars avec des semaines d’efforts, quand au moment de toucher votre part de 80%… pouf magie, magie, votre patron disparaît avec tout le fric et vous bloque de tous ses serveurs. Et bien c’est exactement ce qui est arrivé à l’affilié “Notchy” en mars 2024. Mais bon, je m’avance un peu, laissez-moi reprendre depuis le début de cette saga digne d’un polar cyberpunk.
Tout commence le 21 novembre 2021. À cette époque, le monde du ransomware sort à peine du chaos provoqué par les attaques contre Colonial Pipeline et la fermeture brutale de REvil par les autorités russes. C’est dans ce contexte tendu qu’un nouveau groupe fait son apparition sur les forums du dark web, précisément sur RAMP (Russian Anonymous Marketplace). Leur nom ? BlackCat. Leur proposition ? Un ransomware entièrement codé en Rust, ce langage de programmation moderne que Mozilla a développé pour remplacer le C++ vieillissant. C’est du jamais vu dans l’écosystème criminel !
Alors pourquoi Rust, vous allez me dire ? Bah, c’est simple, d’abord, c’est moderne, rapide comme l’éclair, et sûr au niveau mémoire… Comme ça, pas de plantages foireux comme avec du C++ mal écrit. Ensuite, et c’est là le génie, la plupart des antivirus n’avaient aucune idée de comment analyser du code Rust en 2021. Les signatures de détection étaient Inexistantes et les outils d’analyse statique totalement en galère. Du coup, leur ransomware passe entre les mailles du filet durant des mois.
Post de forum pour faire la promo du Ransomware
Les experts en sécurité sont littéralement bluffés quand ils mettent la main sur les premiers échantillons. Le code est propre, modulaire, optimisé. BlackCat peut tourner sur Windows, Linux, et même VMware ESXi… C’est du cross-platform de qualité industrielle. Et c’est un ransomware, personnalisable via des fichiers JSON. Comme ça, si vous voulez chiffrer seulement certains types de fichiers, ou encore éviter certains pays pour pas se faire taper sur les doigts par les autorités locales ? C’est pas un problème car c’est littéralement du ransomware à la carte, conçu comme un produit SaaS légitime.
Mais qui se cache derrière cette prouesse technique ?
Selon les analyses des chercheurs en cybersécurité, tous les indices pointent vers d’anciens membres de REvil, DarkSide et BlackMatter, c’est à dire la crème de la crème du ransomware russe. Ces mecs ont visiblement appris de leurs erreurs passées… Fini les attaques tape-à-l’œil contre les infrastructures critiques qui font réagir les gouvernements, et place à un profil bas et à une approche business plus subtile. Ils ont compris qu’il faut savoir rester dans l’ombre pour durer.
Leur modèle économique, justement, c’est une révolution dans l’écosystème RaaS (Ransomware-as-a-Service) car là où la concurrence prend 30 à 40% des rançons, comme REvil qui prenait 40%, BlackCat ne prend que 10 à 20% selon le niveau d’expérience de l’affilié. Pour les cybercriminels, c’est carrément Noël en novembre ! Et ce groupe leur fournit tout un écosystème clé en main : le ransomware personnalisable, les outils d’exfiltration de données, l’infrastructure de négociation hébergée sur Tor, un blog de leak pour faire pression sur les victimes, même un service client disponible 24h/24. L’affilié n’a qu’une chose à faire : Trouver une victime et déployer le malware.
L’infrastructure technique développée par BlackCat est très impressionnante, même selon les standards du métier car ils utilisent une architecture décentralisée basée sur Tor et I2P, avec une redondance digne d’AWS. Chaque victime reçoit un site de négociation unique, généré automatiquement et hébergé sur plusieurs serveurs miroirs. Si le FBI ferme un site, dix autres prennent instantanément le relais. Ils ont même développé “Searcher”, un outil custom qui fouille automatiquement dans les téraoctets de données exfiltrées pour identifier les documents les plus compromettants tels que des contrats confidentiels, des données personnelles sensibles, des correspondances avec les avocats…etc. Un moteur de recherche pour le chantage, quoi.
Dès décembre 2021, les premières victimes tombent comme des dominos. Moncler, la marque de luxe italienne qui se retrouve avec ses données étalées sur le dark web. Swissport, qui gère la logistique dans plus de 300 aéroports mondiaux et voit ses opérations paralysées. Des cabinets d’avocats de prestige, des hôpitaux, des universités… BlackCat ne fait pas dans la discrimination sociale, tant que la victime peut payer une rançon substantielle. Les montants varient de quelques centaines de milliers à plusieurs millions de dollars selon la taille et l’impact de l’attaque. Un business en pleine explosion !
Mais c’est en 2023 que BlackCat passe vraiment à la vitesse supérieure en nouant une alliance diabolique avec Scattered Spider, un groupe de jeunes hackers dont certains sont encore des adolescents de 17 à 22 ans, spécialisés dans l’ingénierie sociale. Ces gamins, principalement américains et britanniques, sont issus des communautés de gaming toxiques (Roblox, Minecraft) et ont évolué du SIM swapping vers le ransomware professionnel.
La méthode de Scattered Spider est redoutable mais imparable. D’abord, ils font de l’OSINT (Open Source Intelligence) intensif sur LinkedIn, Instagram, les sites d’entreprise. En gros, ils identifient des employés avec des accès privilégiés, c’est à dire les administrateurs système, les responsables IT, les managers avec des droits élevés. Puis ils les appellent directement, souvent en spoofant le numéro du support IT interne de l’entreprise grâce à des services VoIP. Le script est bienrodé : “Bonjour, ici le help desk de [NomEntreprise], on a détecté une activité suspecte sur votre compte, on doit procéder à un reset de sécurité de votre authentification multi-facteurs.”
Les employés, conditionnés à faire confiance au support IT et souvent sous pression dans leur travail quotidien, donnent alors leurs codes d’accès ou acceptent le reset. Et en 10 minutes chrono, Scattered Spider est dans le système avec des droits d’administrateur sur Active Directory, Okta, ou Azure. Une fois à l’intérieur, ils déploient BlackCat en mode silencieux, exfiltrent les données sensibles, et ne déclenchent le chiffrement qu’une fois certains d’avoir récupéré tout ce qui les intéresse. C’est la combinaison parfaite entre l’ingéniosité sociale des digital natives et la puissance technique du ransomware nouvelle génération.
Le chiffrement des données en action
Le 11 septembre 2023, c’est l’apothéose. MGM Resorts, l’empire des casinos de Las Vegas qui pèse des milliards, tombe en 10 minutes. Un simple coup de fil de Scattered Spider au help desk où ils se font passer pour un employé trouvé sur LinkedIn, et boom, voilà que tout l’écosystème tech de MGM s’effondre comme un château de cartes. BlackCat se déploie méthodiquement sur plus de 100 hyperviseurs VMware ESXi. Les casinos sont littéralement paralysés… les machines à sous affichent des écrans bleus, les systèmes de réservation rendent l’âme, même les clés électroniques des chambres d’hôtel ne fonctionnent plus.
Les images sont complètement surréalistes… On voit des files d’attente interminables de touristes devant les bureaux d’enregistrement qui sont obligés de repasser au papier et au crayon. Des clients bloqués dans les couloirs d’hôtel, incapables d’ouvrir leur porte. Des croupiers contraints de revenir aux jetons physiques et aux calculs faits main comme dans les années 1970. Le Bellagio, le MGM Grand, le Mandalay Bay, tous les joyaux de Sin City touchés simultanément. Les pertes opérationnelles sont estimées à 100 millions de dollars pour le seul troisième trimestre 2023.
Mais MGM, dirigé par des cadres qui ont des couilles en acier, refuse catégoriquement de payer. Ils préfèrent tout reconstruire from scratch plutôt que de céder au chantage. C’est un pari financier et stratégique risqué qui leur coûtera une fortune, mais ils tiennent bon. BlackCat publie évidemment une partie des données volées sur leur blog de leak pour faire pression, mais l’impact reste gérable. MGM survit à l’épreuve, même si ça fait mal au porte-monnaie et à l’ego.
Mais Caesars Entertainment, l’autre mastodonte des casinos frappé quelques jours avant MGM, fait un choix diamétralement opposé. Plutôt que d’affronter des semaines de chaos opérationnel, ils choisissent la voie de la négociation pragmatique. La demande initiale de BlackCat était alors de 30 millions de dollars. Après des discussions tendues avec les négociateurs professionnels du groupe, ils s’accordent sur 15 millions. Dans l’univers impitoyable du ransomware, payer 50% de la demande initiale est considéré comme une victoire diplomatique. Caesars récupère ses systèmes, évite la publication d’informations sensibles sur des millions de clients, et reprend ses opérations quasi normalement.
Cette différence de stratégie entre MGM et Caesars devient immédiatement un cas d’école dans les universités et les formations en cybersécurité. D’un côté, MGM qui refuse de payer et met des semaines à récupérer complètement, avec des pertes financières massives mais un message moral fort. De l’autre, Caesars qui paie et repart en quelques jours, avec un coût maîtrisé mais l’amertume d’avoir financé le crime organisé. Les experts en sécurité restent profondément divisés sur la “bonne” approche. Payer encourage indéniablement les criminels à continuer, mais ne pas payer peut littéralement détruire votre business si vous n’avez pas les reins suffisamment solides.
Quoiqu’il en soit, BlackCat ne se repose jamais sur ses lauriers et continue d’innover à un rythme effréné. Nouvelle version 2.0 du ransomware avec chiffrement intermittent, c’est à dire qui ne chiffre qu’une partie des fichiers pour aller plus vite tout en gardant une bonne efficacité. Un nouvel outil d’exfiltration qui compresse automatiquement les données à la volée pour optimiser les transferts. Un nouveau système de paiement qui accepte Monero en plus de Bitcoin pour plus d’anonymat. Bref, ils ont systématiquement un coup d’avance sur la concurrence et surtout sur les forces de l’ordre.
Mais leur innovation la plus controversée (et, géniale, je trouve) c’est le lancement d’une API publique pour les chercheurs en sécurité. Oui, vous avez bien lu ! BlackCat développe une interface de programmation qui permet aux entreprises de vérifier automatiquement si leurs données ont été volées et leakées. L’idée est diabolique : Pourquoi négocier dans l’ombre quand on peut automatiser le processus de vérification et de chantage ? Les victimes potentielles peuvent alors checker leurs données, voir exactement ce qui a fuité, évaluer l’impact, et décider en connaissance de cause s’il faut payer ou non.
Annonce de leurs nouveautés
Cette API devient rapidement populaire, y compris auprès d’utilisateurs légitimes. Les chercheurs en cybersécurité s’en servent pour tracker les victimes et comprendre les modes opératoires. Les journalistes l’utilisent pour leurs enquêtes sur le cybercrime. Même des concurrents de BlackCat viennent étudier le code pour s’en inspirer. Un groupe criminel qui fournit un service d’utilité publique et démocratise l’accès à l’information sur ses propres crimes, c’est encore du jamais vu !
Puis le 19 décembre 2023, un coup de théâtre qui va chambouler tout l’écosystème BlackCat. Le FBI, en collaboration avec Europol et des agences de plusieurs pays, annonce officiellement avoir saisi l’infrastructure du groupe. Le site principal de BlackCat affiche une bannière “This site has been seized by the FBI” avec le sceau officiel. Les affiliés paniquent totalement, les victimes en cours de négociation ne savent plus à qui payer, c’est le chaos absolu dans l’empire cybercriminel. Les forums du dark web s’enflamment, et tout le monde spécule sur l’ampleur réelle de l’opération.
Sauf que… quelque chose cloche dans cette histoire de saisie. Les serveurs de négociation individuels continuent mystérieusement de fonctionner. Le blog de leak reste accessible via des URLs alternatives. Les affiliés peuvent toujours télécharger le ransomware et déployer leurs attaques. Est-ce vraiment une saisie complète par le FBI ou juste une opération de communication pour déstabiliser le groupe ? La réalité s’avère plus nuancée et moins glorieuse que les communiqués officiels.
Les détails de l’opération révèlent que le FBI a effectivement eu accès à certains serveurs BlackCat grâce à un informateur infiltré qui avait obtenu le statut d’affilié. Ils ont ainsi récupéré 946 paires de clés publiques/privées et développé un outil de déchiffrement distribué gratuitement à plus de 500 victimes, leur évitant ainsi de payer environ 68 millions de dollars de rançons cumulées. Mais c’est un succès partiel car BlackCat conserve le contrôle de l’essentiel de son infrastructure grâce à l’architecture décentralisée qu’ils avaient intelligemment mise en place dès le début.
La réaction de BlackCat à cette “saisie” est brutale et révèle leur véritable nature. Dans un message vengeur publié sur leur blog, ils déclarent la guerre totale aux autorités américaines et annoncent la levée de toutes leurs restrictions auto-imposées. Plus aucune limite morale ou géopolitique. Les hôpitaux, les infrastructures critiques, les centrales électriques, même les installations nucléaires deviennent des cibles légitimes. “Le FBI a franchi une ligne rouge en s’attaquant à nous”, écrivent-ils dans un communiqué rageur. “Nous franchissons la nôtre aussi. Que les conséquences retombent sur eux.”
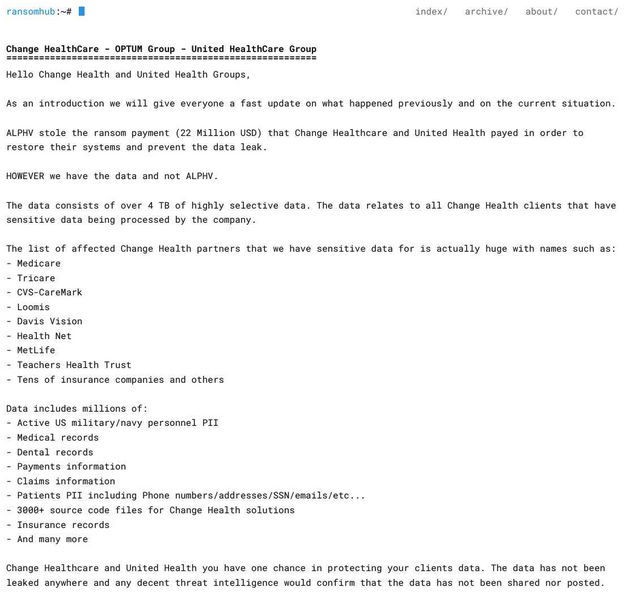
C’est dans ce climat de guerre ouverte entre BlackCat et les autorités américaines qu’éclate l’affaire Change Healthcare en février 2024. Un affilié expérimenté surnommé “Notchy”, probablement lié à des groupes chinois selon des analystes en renseignement, réussit à infiltrer le système de cette entreprise absolument stratégique. Change Healthcare, c’est pas n’importe qui puisqu’ils traitent 15 milliards de transactions médicales par an, soit environ un tiers de tous les paiements de santé aux États-Unis. C’est littéralement le système nerveux financier de la médecine américaine.
L’impact de l’attaque est proprement catastrophique car du jour au lendemain, des milliers de pharmacies ne peuvent plus traiter les ordonnances électroniques. Les hôpitaux se retrouvent incapables de facturer les compagnies d’assurance. Les patients diabétiques ou cardiaques ne peuvent plus obtenir leurs médicaments. Bref, c’est une crise sanitaire nationale d’une ampleur inédite. Change Healthcare n’a littéralement aucune marge de manœuvre et doivent payer pour éviter l’effondrement du système de santé américain. Ils n’ont pas le choix.
La négociation entre Notchy et Change Healthcare se déroule pendant plusieurs semaines dans une atmosphère de crise absolue. La demande initiale est de 60 millions de dollars, soit une des plus grosses rançons jamais exigées. Change Healthcare contre-propose désespérément 15 millions mais après des jours de marchandage intense avec les négociateurs professionnels de BlackCat, qui je vous le rappelle, ont des équipes dédiées disponibles 24h/24 dans plusieurs fuseaux horaires, ils finissent par s’accorder sur 22 millions de dollars. Le 1er mars 2024, Change Healthcare envoie alors 350 Bitcoin (valeur de l’époque, environ 22 millions de dollars) à l’adresse crypto fournie par l’organisation BlackCat.
Et là, c’est le drame qui va révéler la véritable nature de BlackCat et bouleverser tout l’écosystème du ransomware moderne. Notchy, qui a passé des mois sur cette opération complexe et attend “légitimement” sa part de 80% selon l’accord d’affiliation standard (soit environ 17,6 millions de dollars), se retrouve face à un silence radio total. Un jour passe sans nouvelles. Puis deux. Puis une semaine entière. Le 3 mars, pris d’un mauvais pressentiment, Notchy tente de se connecter au panel d’administration de BlackCat pour vérifier le statut de sa mission. Message affiché : “Accès refusé”. Il essaie alors de contacter les administrateurs via les canaux Tox sécurisés habituels mais pas de réponse. Il tente ensuite les serveurs de backup, les channels Discord privés, et même les anciens moyens de communication d’urgence.
Le vide absolu.
C’est à ce moment-là que la réalité frappe Notchy comme un uppercut. Il vient de se faire arnaquer par ses propres patrons. Les administrateurs de BlackCat ont tout simplement empoché les 22 millions de dollars et l’ont éjecté du système. Dans le monde du crime organisé traditionnel, ça s’appelle “se faire buter après le casse”. Dans l’univers cybercriminel, c’est un exit scam d’une ampleur légendaire !
La réaction de Notchy est explosive et va marquer un tournant dans l’histoire du cybercrime car il débarque en rage sur les forums RAMP et BreachForums et balance absolument tout ce qu’il sait. Screenshots des négociations avec Change Healthcare, preuves du paiement de 350 Bitcoin, messages ignorés avec les admins BlackCat, même les details techniques de l’infiltration. “BlackCat m’a volé 22 millions de dollars et vous êtes les prochains !”, hurle-t-il dans un post de 15 pages qui fait l’effet d’une bombe dans la communauté cybercriminelle.
L’onde de choc est immédiate et titanesque. La communauté cybercriminelle mondiale, habituée aux coups fourrés entre gangs rivaux, est en état de sidération totale. Un groupe de ransomware qui arnaque ses propres affiliés avec qui il partage les risques et les bénéfices ?? C’est du jamais vu dans l’histoire du cybercrime organisé. C’est comme si la mafia sicilienne décidait soudainement de buter tous ses capos après chaque opération réussie. Les règles non-écrites du milieu volent alors en éclats.
Mais tout ceci n’est que le début du feuilleton car le 5 mars, BlackCat publie un message laconique sur leur blog qui va rester dans les annales : “Nous fermons définitivement nos opérations. Les pressions du FBI ont rendu notre business model intenable. Merci à tous nos affiliés pour leur collaboration. Bonne chance pour la suite.” Et puis… plus rien. Silence radio total. Les serveurs s’éteignent méthodiquement un par un, le code source du ransomware disparaît des dépôts privés, les administrateurs s’évaporent de tous les canaux de communication.
BlackCat cesse purement et simplement d’exister.
L’analyse forensique de la blockchain Bitcoin révèlera l’ampleur de l’arnaque et la préméditation de l’opération. Les 350 Bitcoin de Change Healthcare ont été immédiatement fragmentés et dispersés à travers un réseau complexe de plus de 50 adresses intermédiaires, puis passés dans des mixers automatisés avant d’être reconvertis en Monero pour une anonymisation totale. Les administrateurs de BlackCat ont mis en place un système de blanchiment digne des plus grandes organisations criminelles et n’ont pas gardé un seul satoshi pour Notchy. C’est le parfait exit scam, minutieusement planifié et exécuté avec une froideur industrielle.
La communauté cybercriminelle mondiale explose alors littéralement. Sur RAMP, XSS, BreachForums, c’est la guerre civile numérique. Certains anciens affiliés défendent encore BlackCat : “Le FBI les a forcés à fermer, ils ont fait ce qu’ils pouvaient.” et d’autres crient à la trahison absolue : “Ils ont détruit 30 ans de confiance dans le modèle RaaS, ces enfoirés nous ont tous niqués.” Les modérateurs des forums, d’habitude neutres, prennent même position de manière inédite : BlackCat est officiellement banni de tous les espaces de discussion, leurs anciens comptes sont fermés, leur réputation est définitivement détruite. Même entre voleurs, il y a des limites à ne pas franchir.
Notchy, l’affilié floué qui se retrouve avec des mois de travail pour rien et 22 millions de dollars envolés, ne se laisse évidemment pas faire. Il lance un ultimatum public sur tous les forums… soit les admins disparus de BlackCat lui versent sa part dans les 48 heures, soit il publie l’intégralité des 6 téraoctets de données volées chez Change Healthcare. Données qui incluent des informations médicales ultra-sensibles sur des millions d’Américains, des militaires couverts par Tricare, des employés CVS, MetLife, des dizaines d’autres assureurs. Change Healthcare se retrouve alors dans une position impossible : ils ont déjà payé 22 millions, et maintenant on leur demande implicitement de payer encore pour éviter le leak.
Épuisé par des semaines de crise et refusant de céder une nouvelle fois au chantage, ils choisissent alors de ne plus négocier. Puis le 20 mars 2024, un mystérieux nouveau groupe appelé RansomHub, qui ressemble étrangement à une reconversion de Notchy ou d’anciens affiliés BlackCat, publie effectivement les données de Change Healthcare sur leur blog de leak. 4 téraoctets d’informations médicales ultra-confidentielles, des millions de patients impactés, un scandale sanitaire d’ampleur historique. Mais qui se cache réellement derrière RansomHub ? Notchy ? Un autre ancien affilié de BlackCat ? Des opportunistes qui ont récupéré les données ? Le mystère reste entier encore à ce jour, mais à ce moment là, le chaos est total.
L’impact de l’exit scam de BlackCat va bien au-delà des 22 millions de dollars volés et ébranle les fondements mêmes du modèle économique du Ransomware-as-a-Service, qui avait pourtant fait ses preuves depuis 2019 avec des groupes comme REvil ou LockBit, qui se retrouve remis en question. Si même les gangs les plus établis et respectés peuvent arnaquer leurs propres affiliés sans préavis, qui peut-on encore croire dans cet écosystème ?
La méfiance s’installe alors durablement dans tous les forums du dark web. Les nouveaux affiliés exigent désormais des garanties financières, des comptes escrow gérés par des tiers de confiance, des preuves de bonne foi, des références vérifiables. Certains demandent même des cautions de plusieurs millions de dollars avant d’accepter de travailler avec un nouveau groupe RaaS. L’époque de la confiance aveugle basée sur la réputation est révolue.
Certains experts de la cybersécurité y voient même la fin d’une époque dorée pour les cybercriminels, car quand la confiance, paradoxalement essentielle même entre criminels, disparaît complètement, tout ce système collaboratif s’effondre. D’autres experts prédisent au contraire une consolidation darwinienne où seuls les groupes avec une vraie réputation historique et des garanties financières béton survivront.
Mais où sont donc passés les mystérieux administrateurs de BlackCat avec leurs 22 millions de dollars ?
Les théories du complot abondent sur les forums spécialisés où certains pensent qu’ils ont été discrètement recrutés par les services de renseignement russes pour développer des cyberarmes d’État. D’autres qu’ils se sont reconvertis dans la crypto-fraude ou les arnaques DeFi, secteurs moins risqués et tout aussi lucratifs. Les plus cyniques suggèrent qu’ils préparent déjà leur prochain coup sous une nouvelle identité, avec un ransomware encore plus sophistiqué et un business model “amélioré”.
En tout cas, BlackCat avait absolument tout pour devenir le LockBit ou le Conti de leur génération et dominer l’écosystème ransomware pendant des années… Mais l’appât du gain immédiat et la cupidité pure ont été plus forts que la vision stratégique. Pour 22 petits millions de dollars soit même pas 6 mois de revenus à leur rythme de croissance, ils ont détruit un business potentiel de plusieurs milliards.
BlackCat laisse un héritage amer mais instructif car ils ont définitivement prouvé que les attaques par ingénierie sociale restaient terriblement efficaces malgré toutes les formations de sensibilisation et que la technologie de chiffrement la plus sophistiquée ne valait absolument rien face à la naïveté humaine et aux processus IT mal sécurisés.
L’épilogue de cette histoire tragique continue de s’écrire en temps réel. Notchy se balade encore sur les forums quand il n’a pas de nouvelles opérations en cours, Change Healthcare panse toujours ses plaies financières et répare péniblement sa réputation et le FBI continue ses investigations pour identifier et arrêter les administrateurs disparus, sans grand succès pour l’instant. Y’a même une récompense de 10 millions de dollars si vous avez des infos.
Et quelque part, peut-être sur une plage paradisiaque des Caraïbes ou dans un penthouse de Dubaï, les cerveaux de BlackCat sirotent probablement des cocktails hors de prix achetés avec les 22 millions de dollars de leur ultime trahison.
La morale de cette histoire, si tant est qu’il puisse y en avoir une dans l’univers du ransomware, c’est que personne n’est jamais digne d’une confiance absolue, surtout pas les criminels. Donc si vous êtes un affilié RaaS qui lisez ceci, méfiez-vous car le prochain exit scam pourrait bien vous viser personnellement…
Vous aussi vous en avez marre de voir vos images disparaître d’Imgur après 6 mois d’inactivité ? Ou de devoir passer par Discord qui compresse tout ce qui bouge ?
Ça tombe bien car j’ai découvert Slink il y a quelques jours et je pense que ça va vous plaire si vous voulez retrouver le contrôle sur vos partages d’images.
Slink, c’est le projet d’Andrii Kryvoviaz, un développeur qui a décidé de combiner ses deux passions : La danse et l’amour de la forêt euuuh, non… Avoir son propre service de partage d’images ET pouvoir raccourcir les URLs en même temps. Parce que oui, en plus d’héberger vos images, Slink génère automatiquement des liens courts pour les partager facilement. Et comme le souligne XDA Developers, tout tient dans un seul container Docker, ce qui rend le déploiement hyper simple.
Le truc vraiment bien pensé, c’est que Slink ne se contente pas de stocker bêtement vos fichiers. Il génère automatiquement des previews, gère l’expiration automatique si vous le souhaitez (pratique pour les partages temporaires), et propose même un mode galerie pour organiser vos images. Le backend en Symfony assure la robustesse, tandis que le frontend en SvelteKit offre une interface moderne et réactive.
Pour l’installation, c’est du Docker classique. Créez votre docker-compose.yml :
Et une fois lancé, vous aurez accès à une interface web complète avec drag & drop, upload multiple, et même une API REST pour automatiser vos uploads depuis vos scripts ou applications. Le système de permissions est granulaire ce qui vous permet de créer des utilisateurs, définir des quotas, et même activer l’upload anonyme si vous voulez faire votre propre service public.
Ce qui m’a particulièrement séduit dans ce projet, c’est surtout la gestion intelligente du stockage. Selon la doc GitHub, Slink supporte non seulement le stockage local, mais aussi S3 (compatible avec MinIO, Backblaze B2, etc.), et même le partage réseau via SMB. Vous pouvez également définir des limites de taille par fichier, par utilisateur, et même configurer une rétention automatique pour ne pas exploser votre espace disque.
La partie raccourcisseur d’URL est aussi vraiment bien intégrée. Chaque image uploadée reçoit automatiquement un identifiant court (style “slink.io/a8f2”), et vous pouvez aussi créer des liens personnalisés avec votre propre nom de domaine. Et contrairement à des services comme bit.ly, vous gardez le contrôle total sur vos analytics avec le nombre de vues, l’origine des visiteurs, et bien sûr tout est stocké localement (génial pour le RGPD, comme dirait le Capitaine Haddock).
Pas de tracking tiers, pas de publicités, pas de vente de données. Avec Slink, vos images restent vos images, point. Et si vous voulez partager quelque chose de sensible, Slink propose même un chiffrement côté client avec des liens à usage unique qui s’autodétruisent après consultation.
Pour les développeurs, l’API est un vrai bonheur avec de l’authentification via tokens JWT, endpoints RESTful bien documentés, et même des webhooks pour intégrer Slink dans vos workflows. Vous pouvez par exemple configurer un hook pour redimensionner automatiquement les images, les envoyer vers un CDN, ou les sauvegarder sur un service externe.
Et les performances sont au rendez-vous grâce à Rust pour la partie critique (génération des identifiants courts et routing), avec un cache Redis optionnel pour accélérer les requêtes fréquentes. Ainsi, sur un VPS basique, Slink peut facilement gérer des milliers de requêtes par seconde. Un détail sympa, le mode sombre adaptatif suit les préférences système, et il y a une PWA complète pour installer Slink comme une app native sur mobile. De plus, l’interface est responsive et fonctionne parfaitement sur tablette ou smartphone.
Après si vous cherchez des alternatives, il y a Chevereto (payant mais très complet), Lychee (orienté galerie photo), ou PictShare (plus minimaliste et que je testerai une prochaine fois…). Slink trouve donc un excellent équilibre entre fonctionnalités et simplicité, et il y a des mises à jour régulières, ce que j’apprécie beaucoup vue que ma passion dans la vie c’est lire des changelogs.
Voilà, donc pour ceux qui veulent tester avant de se lancer, le projet est entièrement open source sous licence MIT et dispo ici !