Cette semaine il y a encore de quoi alimenter la veille des bidouilleurs, même si on n’a pas encore tous les composants nécessaires pour monter une configuration complète.
[Deal du jour] Sorti en mai 2025, le casque Sony WH-1000XM6 est encore aujourd'hui l’un des meilleurs casques audio sur le marché. Encore plus maintenant qu’il est possible de l'acheter en promotion.
L’automobile vit encore au rythme industriel, mais les clients sont passés à l’ère de l’immédiateté. Le choc des cultures est en train de devenir impossible à ignorer, de quoi inspirer l'édito de la newsletter Watt Else du 7 mai.
Que se passe-t-il quand la source officielle se trompe sur son propre produit et que seule une IA le détecte ? Récit d'un micro-incident de fact-checking qui pose une vraie question sur nos angles morts. C'était le sujet de la newsletter ToujoursPlus de la semaine passée : inscrivez-vous gratuitement ici pour recevoir la suivante !
Dans le désert de Chihuahua, une zone blanche alimente tous les fantasmes : ondes radio coupées, magnétisme fou et visites d’aliens. Mais derrière la légende de la « Zona del Silencio » se cache surtout un crash de missile radioactif mal géré par l'armée américaine en pleine Guerre froide.
The website for the popular JDownloader download manager was compromised earlier this week to distribute malicious Windows and Linux installers, with the Windows payload found deploying a Python-based remote access trojan. [...]
Roblox veut rendre ses jeux plus beaux grâce à l’IA, Vista 4D transforme une vidéo en scène manipulable, ChatGPT développe une étrange obsession pour les gobelins, Apple semble enterrer doucement le Vision Pro, Tesla lance enfin son Semi industriel, et les infrasons pourraient expliquer certaines maisons hantées.
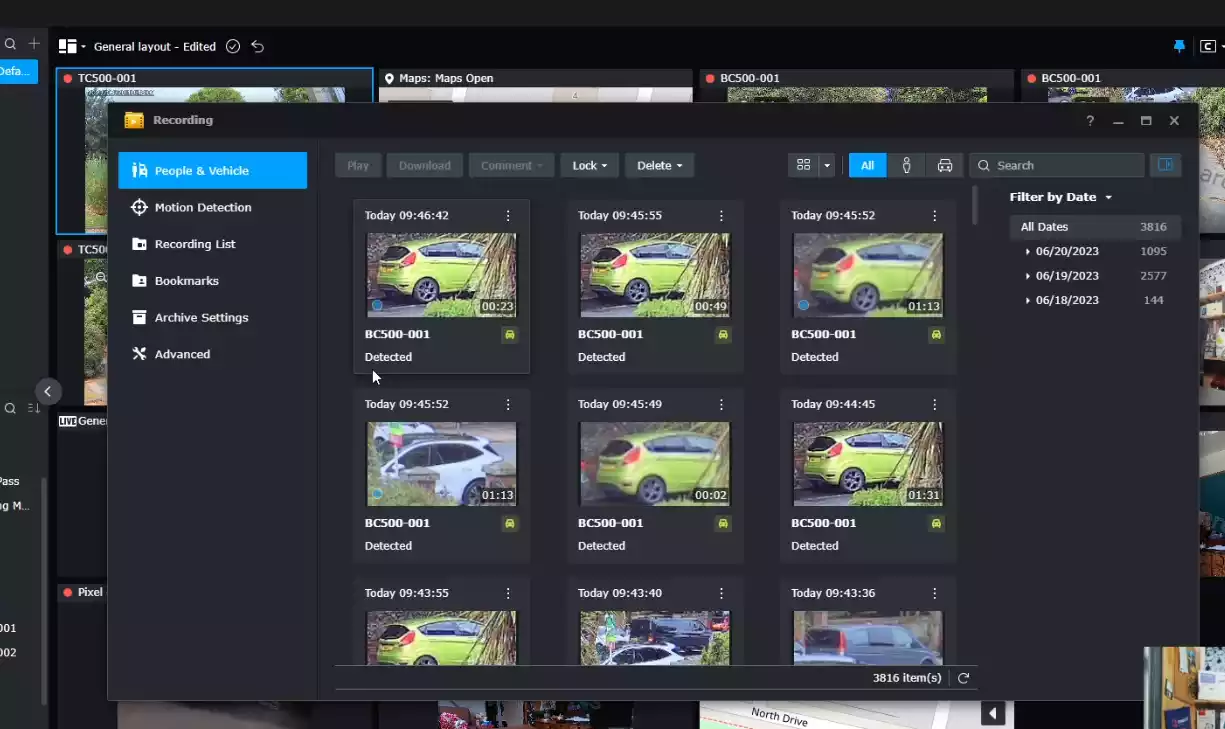
Synology Cameras Now Need a License for Surveillance Station
Synology has changed the licensing position for selected cameras in its 2026 surveillance camera range, with the newly listed BC510, TC510, and BC800Z now requiring a Surveillance Device License when used with Synology Surveillance Station. This marks a notable shift from the previous value proposition of Synology-branded cameras, which had been positioned as tightly integrated first-party devices that did not require an additional camera license. The new BC510 and TC510 have been introduced as AI-enabled bullet and turret cameras with 5MP resolution, 30 FPS recording, 110° horizontal field of view, IP66/IP67 protection, 30 m night vision, edge AI analytics, ONVIF support, and compatibility with Synology’s wider surveillance ecosystem, including its upcoming cloud-based surveillance platform. But why has Synology changed it’s stance on camera license requirements with this new series?
What Changed in Synology Cameras and the License Requirements?
Synology’s camera licensing policy has changed for part of its 2026 camera generation. The BC510, TC510, and BC800Z are now listed by Synology as requiring a Surveillance Device License, with Synology’s license documentation stating that these models require 1 license per camera. This means these Synology-branded cameras are now treated in the same basic licensing structure as regular IP cameras, where each camera consumes 1 available Surveillance Station camera license.
This is a significant change because Synology’s own cameras previously had a clear licensing advantage inside Surveillance Station. Earlier Synology camera models were positioned as first-party devices that worked directly with the platform without the need to buy an additional camera license. For users building a Synology-based surveillance setup, that made the cameras easier to justify even when comparable third-party ONVIF cameras were available at lower prices. The camera, platform integration, AI features, and license position were effectively part of the same value proposition.
With the 2026 generation, that arrangement has changed for the BC510, TC510, and BC800Z. Users will now need to account for the cost of a Surveillance Device License when deploying these cameras beyond the default licenses included with their Synology NAS, NVR, or DVA system. Synology NAS systems generally include 2 default licenses, Network Video Recorder systems include 4, and Deep Learning NVR systems include 8. Any deployment that exceeds the available default license count will require additional license packs, just as it would when adding third-party IP cameras or other supported surveillance devices.
Device Type
License Units
Example
License required
Synology Cameras
Per camera
BC510, TC510, BC800Z
1
Per camera
BC500, TC500
0
Synology LiveCam
Per device
Synology LiveCam app
1
Regular IP camera
Per camera
AXIS P1347
1
Panoramic (fisheye)
Per camera
AXIS M3007
1
Multi-lens
Fixed lens
Per camera
ArecontVision AV8185DN
1
Fixed lenses with independent IP
Per channel
AXIS Q3709-PVE
3
Removable lens
Per channel
AXIS F44
5
Video server
Per channel
Vivotek VS8801
8
I/O module
Per device
AXIS A9188
1
Intercom
Per device
AXIS A8105-E
1
IP speaker
Per device
AXIS C3003-E
1
Access controller (door)
Per device
AXIS A1001
1
Transaction device (POS)
Per device
–
2
According to Synology’s stated position around the new generation, the decision is connected to broader deployment flexibility. The BC510 and TC510 are being introduced not only as cameras for Surveillance Station, but also as devices designed to work across multiple surveillance environments. Synology states that these cameras support deployment within the native Synology ecosystem, third-party NVR and VMS infrastructures through ONVIF, and its upcoming cloud-based surveillance platform. In that context, Synology appears to be separating the camera hardware from the Surveillance Station license entitlement, rather than treating the license as implicitly bundled with the camera.
The advantage Synology presents is that this approach allows the cameras to be used more flexibly outside Synology-only deployments. In theory, a lower hardware price can reduce the entry cost for users who want to deploy the cameras in third-party systems, where a Synology Surveillance Station license would not be relevant. For mixed environments, installers, managed service providers, or businesses migrating between platforms, the cameras can be positioned as ONVIF-capable AI cameras rather than hardware tied primarily to a Synology NAS or NVR. Synology’s argument is therefore less about removing value from Surveillance Station users, and more about aligning the cameras with wider interoperability, third-party infrastructure support, and future cloud surveillance services.
Which Cameras are Affected, and What About Older Synology Cameras?
The affected 2026 Synology camera models listed as requiring a Surveillance Device License are the BC800Z, BC510, and TC510. The BC800Z is the higher-end 8MP model with PoE connectivity, optical zoom coverage, longer night vision range, IP66/IP67/IK10 protection, a 5-year warranty, and additional analytics such as License Plate Recognition and Smoke Detection. The BC510 and TC510 are 5MP PoE cameras, offered in bullet and turret designs respectively, with 2880×1620 resolution, 30 FPS video, a 110° horizontal field of view, 30 m night vision, people and vehicle detection, intrusion detection, audio detection, tampering detection, motion detection, people and vehicle counting, Instant Search, and people-based auto tracking. The CC400W is not listed as requiring a Surveillance Device License, and remains separate from the licensing change affecting the BC800Z, BC510, and TC510.
At this stage, the licensing change appears to apply to the newer 2026 generation models listed by Synology, rather than being presented as a wider retrospective change across all previous Synology cameras. Older Synology camera models are less prominent on Synology’s current product pages following the arrival of the refreshed range, so the long-term public positioning of those older models is less clear from the current camera comparison material. Based on the available details, there is no indication in the supplied information that previously released Synology cameras are being newly reclassified in the same way, but buyers and existing users should still check the official Synology Camera Support List and license documentation for their exact model before expanding or changing a deployment.
Why Has Synology Made This Decision?
Synology’s stated reasoning appears to centre on making its newer cameras more flexible across different deployment environments. The BC510 and TC510 are being positioned not only as Surveillance Station cameras, but also as cameras for third-party NVR and VMS systems through ONVIF, as well as Synology’s upcoming cloud-based surveillance platform. By separating the camera hardware from the Surveillance Station license entitlement, Synology can sell the cameras into environments where a bundled Surveillance Station license would not be useful, while also lowering the hardware entry price for users who are not deploying them directly with Synology’s own platform. There may also be a wider commercial consideration around Synology’s position as a Taiwanese camera manufacturer. In some government, education, public sector, and official institutional deployments, the country of origin of surveillance hardware can be a factor in procurement, security review, and long-term platform approval.
This may give Synology an advantage over some Chinese-made camera brands, particularly in environments where hardware from certain vendors is harder to approve or deploy. In that context, Synology may see an opportunity to position the BC510, TC510, and BC800Z as more broadly deployable surveillance cameras for institutions that want ONVIF-compatible hardware without relying on brands that may face additional scrutiny. For Synology-only users, however, the practical result is different: the license cost now needs to be considered separately when adding the BC510, TC510, or BC800Z to a deployment that has already used its default license allowance. This does not remove the cameras’ first-party integration benefits, edge AI features, or official support inside the Synology ecosystem, but it does change the overall value calculation compared with older Synology cameras that did not require a separate Surveillance Device License.
This description contains links to Amazon. These links will take you to some of the products mentioned in today's content. As an Amazon Associate, I earn from qualifying purchases. Visit the NASCompares Deal Finder to find the best place to buy this device in your region, based on Service, Support and Reputation - Just Search for your NAS Drive in the Box Below
Need Advice on Data Storage from an Expert?
Finally, for free advice about your setup, just leave a message in the comments below here at NASCompares.com and we will get back to you.Need Help?
Where possible (and where appropriate) please provide as much information about your requirements, as then I can arrange the best answer and solution to your needs. Do not worry about your e-mail address being required, it will NOT be used in a mailing list and will NOT be used in any way other than to respond to your enquiry.
[contact-form-7]
TRY CHAT Terms and Conditions
If you like this service, please consider supporting us.
We use affiliate links on the blog allowing NAScompares information and advice service to be free of charge to you.Anything you purchase on the day you click on our links will generate a small commission which isused to run the website. Here is a link for Amazon and B&H.You can also get me a Ko-fi or old school Paypal. Thanks!To find out more about how to support this advice service checkHEREIf you need to fix or configure a NAS, check FiverHave you thought about helping others with your knowledge? Find Instructions Here
Or support us by using our affiliate links on Amazon UK and Amazon US
Alternatively, why not ask me on the ASK NASCompares forum, by clicking the button below. This is a community hub that serves as a place that I can answer your question, chew the fat, share new release information and even get corrections posted. I will always get around to answering ALL queries, but as a one-man operation, I cannot promise speed! So by sharing your query in the ASK NASCompares section below, you can get a better range of solutions and suggestions, alongside my own.
TeamViewer is a remote assistance solution that lets you remotely connect to and control Intune-managed Windows, macOS, Android, and iOS/iPadOS devices directly from the Intune admin center to support your users. Microsoft Intune's April 2026 update (service release 2604) introduces a redesigned TeamViewer connector for remote assistance. The new connector replaces the existing one with a simplified setup process and adds SSO (single sign-on) support, device group synchronization, and granular role-based permissions. If you still use the old connector, you have 12 months to migrate before it stops working. This article explains what changed, what you need, and how to configure the new connector.
Ce n’est pas peu dire que Sonic, la mascotte de Sega, a connu des débuts difficiles dans les années 2000. Ballotté entre des jeux sans âme aux choix douteux, Sonic a depuis cherché son registre, sans grand succès. Mais il s’avère que l’on aurait pu avoir un Sonic bien plus intéressant lors de son passage à la 3D.
Vous n'êtes pas encore prêts à dire adieu aux bureaux de Runway ? Alors que Le Diable s’habille en Prada 2 affole les compteurs du box-office et que la performance de Meryl Streep prouve que le style est éternel, nous avons sélectionné pour vous cinq pépites cinématographiques à voir après (ou avant) avoir vu cette suite.
L’apparition de l’IA Mythos, présentée comme capable de détecter rapidement des failles informatiques majeures, montre que les capacités offensives dans le cyberespace progressent très vite. Cette évolution pourrait rendre les systèmes nucléaires plus vulnérables et augmenter le risque d’erreurs, de sabotage ou d’escalade accidentelle.
Un YouTubeur a transformé la roue d'exercice de son hamster en mini-turbine pour recharger son téléphone. Ça fonctionne, à condition de patienter et de soigner son câble USB.
Une équipe chinoise a entraîné 25 volontaires à voler avec des ailes virtuelles. Au bout d'une semaine, leur cerveau a commencé à traiter ces ailes comme s'il s'agissait de bras.
Une image d'OVNI en forme d'étoile à huit branches, captée par un capteur infrarouge militaire au Moyen-Orient, refait surface sur X après la publication de fichiers liés aux OVNI par la Maison-Blanche. La vidéo date en réalité de 2013, et l'explication la plus probable n'a rien d'extraterrestre.
Anthropic a expliqué dans un long billet de recherche comment ses modèles Claude sont passés d'un taux de chantage de 96 % à zéro dans ses tests d'alignement. La recette : leur enseigner le raisonnement derrière les bons comportements, pas seulement les bons comportements.
 Cette semaine il y a encore de quoi alimenter la veille des bidouilleurs, même si on n’a pas encore tous les composants nécessaires pour monter une configuration complète.
Cette semaine il y a encore de quoi alimenter la veille des bidouilleurs, même si on n’a pas encore tous les composants nécessaires pour monter une configuration complète.








 SUBSCRIBE TO OUR NEWSLETTER
SUBSCRIBE TO OUR NEWSLETTER 






.webp)








