Szhlux, Jiytfu, Dozawa… cette extension masque les marques aux noms improbables sur Amazon
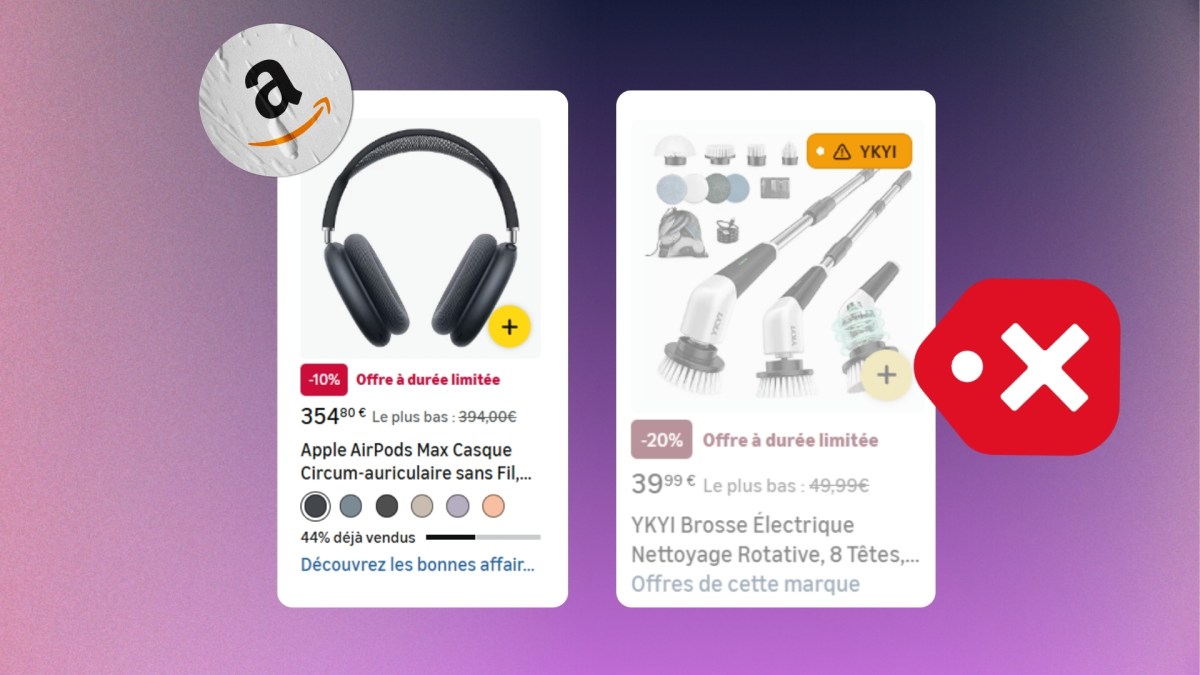
Une extension gratuite propose de faire le ménage dans les résultats d’Amazon en masquant les marques inconnues aux noms parfois imprononçables.
Une extension gratuite propose de faire le ménage dans les résultats d’Amazon en masquant les marques inconnues aux noms parfois imprononçables.

Alors que Stranger Things vient de se terminer et que les fans sont encore sous le choc — pour le meilleur ou pour le pire, à vous de décider —, Netflix est déjà plongé dans la nostalgie de la première saison. Une édition spéciale plutôt maligne fait son apparition sur la plateforme.
Autrefois gros client d'Amazon Web Services, Airbus, avionneur français, opte pour un Cloud européen. C'est Scaleway, une entreprise française, qui a été choisie pour cela. Enfin, pas pour l'ensemble de ses services.
L’article Airbus lâche Amazon AWS et opte pour des serveurs Cloud français est apparu en premier sur Tom’s Hardware.


L'essor de l'IA en local impose de nouvelles contraintes matérielles, notamment en matière de stockage. Samsung entend y répondre avec sa gamme SSD 990, qui mise sur un équilibre entre performances, capacité et efficacité énergétique.
L’article Vous travaillez avec l’IA en local ? Le nouveau Samsung SSD 990 va booster votre efficacité est apparu en premier sur Tom’s Hardware.


Si vous faites du pixel art, voilà un petit outil qui devrait vous plaire. Pix 2D to 3D prend votre sprite et vous le transforme en modèle 3D voxelisé au format .obj, importable direct dans Blender, Unity ou Godot. Pas la moindre trace d'IA là-dedans, uniquement des maths, et son dev Prashant bosse chez Snaptrude sur du logiciel 3D, donc autant vous dire qu'il maîtrise.
L'idée, c'est de vous épargner la modélisation quand vous montez un jeu en 3D iso ou un 2.5D et qu'il vous manque juste trois caisses et un tonneau pour meubler le décor. Vous dessinez le sprite, vous le passez dans l'app et hop, l'objet 3D ressort de l'autre côté.
Vous avez 4 modes selon ce que vous lui donnez à manger, plus un réglage Auto qui devine le format tout seul en regardant les proportions de votre image.
Single voxelise un sprite unique. Single + Repeated le répète sur les 4 côtés en l'extrudant sur la profondeur de votre choix. Dual accepte une planche à 2 vues (face et dos). Et mon préféré, Quad, avale carrément une planche de 4 vues alignées à l'horizontale dans un ordre bien précis : gauche, face, droite, dos. Résultat, un objet complet visible à 360°.
Si c'est sur ce dernier mode que vous voulez partir, sachez que le développeur conseille de passer par la fonction d'export de Frame d' un éditeur de sprites plutôt que de tout vous taper à la main.
L'interface de Pix 2D to 3D, avec le sélecteur de mode et les réglages de profondeur
L'algorithme calcule l'épaisseur des pixels en fonction de leur distance au bord, et les flancs sont arrondis pour une transition douce. L'outil modifie également les bords pour un effet plus naturel, en supprimant progressivement des voxels, ce qui évite l'aspect rigide et artificiel.
Du coup, pas de GPU qui chauffe, rien à installer à part l'app. Après cet outil est un convertisseur géométrique, pas un devin, hein donc à vous de bien gérer l'alignement du dessin dans les cases au départ. Sur Windows, la dernière pre-release est disponible par contre, pour macOS, il faut utiliser la version précédente et sous Linux, ça se compile facilement avec Go, Node, GTK3 et WebKit2GTK.
En tout cas, pour des formes simples et plutôt rondes, j'ai trouvé le rendu assez bluffant. Maintenant, si vous préférez rester dans votre éditeur, Pixelorama dispose de sa propre extension de voxélisation, mais sans le mode à 4 vues. Et pour vous rendre compte de ce que donnent des sprites voxélisés à grande échelle, je vous invite à jeter un œil à ce mod voxel de Duke Nukem 3D qui vaut vraiment le coup d'œil.
C'est par ici que ça se passe !
![]()
 Les GeForce RTX 50 SUPER seraient déjà entre les mains des partenaires, mais le lancement est lié à la disponibilité des puces GDDR7 de 3 Go
Les GeForce RTX 50 SUPER seraient déjà entre les mains des partenaires, mais le lancement est lié à la disponibilité des puces GDDR7 de 3 Go
Cet article GeForce RTX 50 SUPER, les GPU sont là mais la GDDR7 bloque le lancement a été publié en premier par GinjFo.
Vous avez une TV connectée qui vous crache de la pub, un navigateur intégré dedans qui n'accepte aucune extension, et surtout aucun moyen d'installer quoi que ce soit dessus ? Bonne nouvelle les amis, l'équipe de Puter vient de compiler Firefox en WebAssembly, ce qui fait que ce mur commence sérieusement à se fissurer...
On avait déjà de vieux OS et des émulateurs x86 qui tournaient dans une page web , et là on passe carrément au navigateur au complet. La démo est en ligne si vous voulez tester tout de suite.

L'idée, la voilà... vous ouvrez un onglet dans votre navigateur, et dans cet onglet, c'est un Firefox complet qui tourne, avec son propre moteur d'affichage. Curieux de savoir ce que ça pesait, j'ai récupéré les fichiers, et une fois tout déballé, on arrive à 233 Mo. C'est exactement le même Firefox que sur votre machine, sauf qu'il vit à 100% sur une page web.
Le plus marrant là-dedans, c'est toutes les possibilités que ça ouvre... Par exemple, il y a un gars sur Hacker News qui vient de récupérer une TV sous VIDAA, ce système où tout s'affiche en pages web et où le navigateur maison refuse le moindre bloqueur de pub. Et maintenant son programme du week-end c'est de démarrer Firefox dans le navigateur de la télé, puis d'y glisser uBlock Origin . Et ça vaut pour tout ce qui est cadenassé, la borne d'accueil, le Chromebook du collège, le poste du boulot où l'informatique vous a tout bloqué sauf le navigateur.
La deuxième, c'est de pouvoir vérifier un site dans Firefox quand vous n'avez pas de Firefox sous la main. Vous êtes sur iPhone, ou coincé sur le Chrome tout naze de votre boîte sans les droits admin ? Bah vous ouvrez un onglet et vous avez un vrai moteur Mozilla sous la main pour vérifier que votre page ne part pas en vrille.

La troisième possibilité s'adresse aux développeurs. Pour fabriquer une miniature de page ou prévisualiser du HTML, il faut d'habitude un navigateur qui tourne sur un serveur, avec la machine à payer derrière. Là, le rendu peut se faire directement chez le visiteur, grâce à un peu de code :
import { Gecko } from 'gecko.js';
const gecko = new Gecko({ canvas: document.querySelector('canvas')! });
await gecko.init();
await gecko.load('data:text/html,# hello from Gecko
');
Maintenant, la limite de la démo actuellement en ligne, c'est que tout le trafic passe par les serveurs de Puter, sans quoi ça ne pourrait pas fonctionner du tout. Le HTTPS reste bien chiffré de bout en bout, mais évitez quand même d'y taper vos mots de passe. Ah et ça rame aussi un peu, et sur mobile c'est mort pour le moment. En tout cas, c'est pas un truc que je vous conseille d'utiliser au quotidien parce que bien employé par un cybercriminel, ça pourrait permettre s'il y a une faille dans le moteur de rendu évidemment de lire par exemple vos cookies.
Donc si vous l'utilisez, pensez bien à faire tourner chaque site que vous visitez avec ça, dans une instance séparée
Ce chantier a été entrepris avec l'aide de Claude d'Anthropic. Il a englouti une trentaine de milliards de tokens, soit dans les 25 000 $ au tarif normal. Mais heureusement, l'équipe de Puter avait un abonnement Max et s'en est tirée "que" pour une centaine de dollars. Voilà, c'est de la bidouille, avec les défauts qui vont avec mais avouez que c'est beau ^^.
Le code est ici sous licence MPL, et y'a aussi WebkitWasm qui fait la même chose avec WebKit.
Source : Simon Willison

Vous vous souvenez d'AIM ? Mais siiii, le petit bonhomme jaune qui courait, la porte qui claque quand un pote se connecte, les away messages passifs-agressifs à base de paroles de chanson... Et bien la bidouilleuse Veronica a remonté son propre serveur AIM, et ça a l'air de plutôt bien fonctionner
Pour reposer un peu le cadre, AOL a débranché AIM fin 2017. Depuis, les millions de screen names de l'époque pointent dans le vide (Moi c'était FoxMDE ^^), et tous les vieux clients qui traînent actuellement sur vos disques durs ou CD-Rom se connectent à un serveur qui n'existe plus.
Fin de l'histoire, normalement (?).
Bah pas vraiment car AIM tournait sur un protocole qui s'appelle OSCAR, et qui est le même que celui d'ICQ. Du coup, un développeur du nom de mk6i a réimplémenté ce truc en open source, baptisé Open OSCAR Server . En gros, vous faites tourner le serveur sur votre propre machine, vous dites à votre vieux client AIM d'aller taper là plutôt que chez AOL, et hop, vous revoilà en 2003. Veronica utilise ainsi AIM 5.1 sur ses bécanes, et elle héberge le sien sur un petit VPS Debian qui coûte trois francs six sous.

Alors pourquoi avoir fait ça ? Eh bien comme elle le dit elle-même, Discord commençait à la gonfler, et elle avait la nostalgie du lycée. Je vous traduis le passage, il est chouette car je m'y suis bien retrouvé : "Au lycée, la plupart de mes journées commençaient et finissaient par AIM. C'était avant que tout le monde ait des SMS (ou des téléphones portables). Tout, des projets de classe aux relations entières, se passait dans une fenêtre AIM."
Voilà. On a tous connu ça, certains avec MSN ou ICQ...
Ce qui me plaît là-dedans, c'est que ça remet surtout des vieilles machines au boulot. C'est la même énergie que NeoCities et son web fait à la main , sauf qu'ici c'est votre messagerie. Votre Windows 98 dans le placard peut ainsi redevenir utile (gaffe aux virus quand même) ! Vous montez le serveur, vous filez l'adresse à vos potes, et vous avez votre messagerie privée à vous. Pas de pub, et surtout aucun webdesigner coké pour vous chambouler toute l'interface un matin sans prévenir.
Après faut quand même savoir bricoler un minimum sous Linux mais avec son tuto, vous devriez vous en sortir. Bref, si ça vous tente, elle détaille toute la manip sur son blog.

 Des astronomes annoncent avoir détecté de l’hélium s’échappant de l’atmosphère de LHS 1140 b, une exoplanète rocheuse située dans la zone habitable de son étoile.
Des astronomes annoncent avoir détecté de l’hélium s’échappant de l’atmosphère de LHS 1140 b, une exoplanète rocheuse située dans la zone habitable de son étoile.
Cet article Une atmosphère est détectée autour d’une planète rocheuse habitable a été publié en premier par GinjFo.

[Deal du jour] La manette Backbone One permet de jouer sur votre smartphone comme si c'était une vraie console portable, et ainsi profiter de vos titres de la meilleure manière possible. Un peu chère à sa sortie, elle est actuellement trouvable à moins de 15 €.

La Région Auvergne-Rhône-Alpes veut constituer une flotte de 1 500 climatiseurs mobiles pour répondre rapidement aux canicules dans les hôpitaux, les Ehpad et les écoles. Une solution de répit immédiatement disponible , mais qui soulève une question sur la pérennité d’une telle opération.

Denza ouvre les commandes de sa supercar électrique en France. Avec jusqu'à 1 604 ch et un tarif qui la place face à Maserati, la Z affiche clairement ses ambitions.
 Windows 11 26H2 sera déployé à l’automne 2026. Installation rapide, package d’activation, compatibilité et nouveautés : voici ce qui attend votre PC.
Windows 11 26H2 sera déployé à l’automne 2026. Installation rapide, package d’activation, compatibilité et nouveautés : voici ce qui attend votre PC.
Cet article Windows 11 26H2 : Tout ce que vous devez savoir a été publié en premier par GinjFo.
 GTA 6 pourrait battre tous les records commerciaux du jeu vidéo. Selon des estimations il pourrait générer entre 3,3 et 5,2 milliards de dollars de revenus mondiaux dès sa première semaine.
GTA 6 pourrait battre tous les records commerciaux du jeu vidéo. Selon des estimations il pourrait générer entre 3,3 et 5,2 milliards de dollars de revenus mondiaux dès sa première semaine.
Cet article GTA 6 pourrait générer jusqu’à 5,2 milliards de dollars en une semaine a été publié en premier par GinjFo.
 La famille des Core Ultra 400 de Nova Lake-S vient d’apparaître avec un calendrier de lancement. Les premiers modèles 28 cœurs seraient prévus début 2027.
La famille des Core Ultra 400 de Nova Lake-S vient d’apparaître avec un calendrier de lancement. Les premiers modèles 28 cœurs seraient prévus début 2027.
Cet article Le Core Ultra 9 400K apparaît, le modèle 52 cœurs pourrait attendre fin 2027 a été publié en premier par GinjFo.
Alors ça, c'est un sacré morceau qui va ravir tous les fans de rétro gaming ! Patchzy, le dev de Wheel Wizard (le launcher de Retro Rewind), vient d'annoncer Mario Kart Wii compiled, ce qu'il présente comme le premier jeu Wii recompilé en natif pour PC. Pas émulé, hein recompilé. Et vous allez voir pourquoi c'est mieux !
alors pour le moment c'est pas encore dispo, mais c'est une annonce qui est faite en amont de la sortie en bêta qui aura lieu au mois d'août. Cette version de Mario Kart est la première recompilation statique d'un jeu Wii. L'avantage de la recompilation, c'est qu'on peut lui ajouter de nouvelles fonctionnalités et il y aura notamment du jeu en ligne, de la 4K (avec les textures de 2008 dedans par contre...), un framerate débloqué, ainsi qu'un support optionnel de Retro Rewind, ce qui lui apportera plus de 200 circuits.
On a donc une date et on a donc cette vidéo qui va vous mettre l'eau à la bouche :
La recompilation statique, pour faire simple, ça prend le code machine du jeu et ça le retraduit en programme natif pour votre PC. Pas de couche d'émulation qui fait tourner une Wii fantôme en arrière-plan, juste un exécutable que vous lancez comme n'importe quel jeu Steam.
La scène sait faire ça sur N64 depuis un moment, et c'est comme ça que Banjo-Kazooie a atterri sur PC en 4K , et quelques projets s'y sont collés sur Xbox 360. Pour ma part, moi je suis en train de coder une espèce de recompilateur universel qui supportera plein de consoles différentes, mais c'est pas encore prêt et je sais pas encore si je mettrai ça sous licence libre ou si ce sera juste un binaire pour mes Patreons. On verra bien, c'est pas fini, et je prends mon temps mais c'est un petit peu mon passe-temps du moment.
Au moment où j'écris cet article, je suis en train de bosser sur la recompilation de l'ensemble des jeux N64 :

Après sur Wii, le terrain n'était pas complètement vierge non plus, puisque DolRecomp, un recompilateur statique GameCube et Wii, traîne sur GitHub depuis le mois de juin. Alors pourquoi est-ce qu'on s'excite tous si on peut déjà faire tourner Mario Kart Wii nickel sous Dolphin depuis des années ?
Eh bien parce que comme je vous le disais, en théorie, un binaire natif, déjà ça vous épargne tous les problèmes liés à l'émulation, je pense à la surcharge que ça peut engendrer sur les petites configs ou les petits lags, ce genre de choses.
Puis en plus ça peut permettre de supporter par exemple des mods. Je pense à Retro Rewind évidemment, mais pourquoi pas aussi implémenter des nouvelles fonctionnalités dans le jeu. Et puis ça suivra les évolutions de votre machine sans que vous ayez à vous traîner un émulateur... C'est ça qui rend par exemple la recompilation PC d'Animal Crossing intéressante.
En tout cas, ce qui est sûr, c'est qu'avec Patchzy, ça va être du lourd ! En plus, comme Nintendo vient d'annoncer la fin des serveurs de Mario Kart Tour pour le 29 septembre, cette bêta d'août va pouvoir prendre le relais donc ça c'est super cool !!
Après côté légal, le projet ne distribue aucun asset Nintendo, ce sera donc à vous de fournir votre propre ROM. On verra bien si ça empêche Nintendo de dégainer ses avocats...

On ne présente plus Linus Torvalds, le père du noyau Linux, aussi connu pour son génie technique que pour un franc-parler. Cette fois, c'est le débat sur l'usage de l'IA dans le développement du noyau qui l'a fait sortir du bois.
Sur la fameuse mailing list où se décide l'avenir de Linux, il a coupé court à la polémique en posant noir sur blanc que son projet n'était pas, et ne serait jamais, un truc anti-IA.
Sa sortie a de quoi rester dans les annales, puisqu'à ceux que ça agace, il conseille de faire ce que l'open source autorise justement, forker le noyau, autrement dit en copier tout le code pour bâtir leur propre version dans leur coin, ou alors juste s'en aller.
Ce qui est étonnant, c'est le revirement, parce qu'il y a deux ans à peine, ce même Torvalds envoyait balader l'IA en la réduisant à du 90 % de hype. Aujourd'hui, il la décrit comme un outil clairement utile dont plus grand monde ne discute vraiment l'intérêt.

Ça ne l'empêche pas de reconnaître les ratés, puisqu'il admet que ces outils peuvent charger un peu plus la barque des mainteneurs et faire remonter des bugs bien embarrassants, mais pour lui la parade tient en deux mots, de meilleurs outils, surtout pas la fuite.
Le passage le plus tranchant arrive quand il refuse de transformer le noyau en champ de bataille idéologique, en rappelant que ça n'a jamais été un projet de justiciers sociaux et que ça ne le sera jamais.
Dans sa communauté, martèle-t-il, on fait de l'open source parce que ça donne de meilleures technos, pas pour des motifs quasi religieux, et les choix se tranchent au mérite technique, jamais par peur d'une nouveauté.
Il n'est d'ailleurs pas seul sur cette ligne, puisque Greg Kroah-Hartman, l'un des mainteneurs les plus haut placés du noyau juste derrière lui, a confirmé de son côté que les rapports de bugs pondus par des IA étaient devenus franchement précieux.
Voir le créateur de Linux balancer un forkez ou barrez-vous à la figure des anti-IA, c'est du Torvalds pur jus, brutal mais au moins parfaitement limpide.
Source : ARS Technica

La Belgique vient de bloquer wawacity.pizza. Et wawacity.rodeo. Ah et aussi wawacity.taxi, wawacity.futbol, wawacity.motorcycles, wawacity.irish, sans oublier zone-telechargement.meme et zone-telechargement.monster ( la liste est ici ).
113 domaines au total, classés le 3 juillet dernier comme contrefaisants par le président du tribunal de l'entreprise francophone de Bruxelles dont 37 pour Wawacity et 36 pour Zone-Téléchargement . Y'a même un zone-telechargement.gratis, qui est au moins honnête sur le prix de la marchandise ^^ !

Sauf que depuis le 9 juillet, les deux sites tournent à nouveau sur un TLD en .poker. Soit la veille du jour où la BAPO, le service belge de lutte contre la contrefaçon en ligne, a publié sa décision d'exécution. Autrement dit, la liste était déjà obsolète avant que Telenet, Proximus, Orange Belgium, Mobile Vikings et DIGI aient eu le temps d'y toucher ! Et les anciennes adresses en .codes et .expert, ne sont pas dans la liste belge non plus.
Du coup, vous vous demandez peut-être pourquoi ces deux sites collectionnent les TLD les plus improbables du registre. Hé bien c'est pas du folklore, c'est une réponse directe à l'ARCOM. À chaque fois que les FAI français appliquent une salve de blocages DNS , les opérateurs enregistrent un nouveau domaine et redirigent leur public via des pages d'atterrissage et des canaux Telegram. La Belgique hérite donc d'un stock de domaines cramés par la France, et les bloque consciencieusement, un par un, avec plusieurs coups de retard.

Après, les ayants droit ne sont pas con non plus puisqu'ils ont explicitement demandé au tribunal de bloquer les pages "panneau indicateur", c'est à dire celles qui vous disent où le site a déménagé cette semaine.
Résultat, wawacity-info.com et zone-telechargement-info.com sont aussi dans la liste. Ces deux pages n'hébergent aucun contenu protégé et ne pointent vers aucun fichier illégal, elles se contentent de vous annoncer quelle est l'adresse active du moment. Le tribunal a validé quand même, au motif qu'elles "facilitent l'accès".

Et là, si vous mettez ces deux pages indicatrices côte à côte, vous voyez tout de suite qu'elles sont quasiment identiques. Même mise en page, même messages sur Telegram, où les deux comptes arrosent des dizaines de milliers d'abonnés avec un texte identique au mot près. Wawacity et Zone-Téléchargement, c'est donc très probablement la même équipe, ce qui explique pourquoi les deux changent de domaine en même temps, comme un couple qui déménage.

Movix, visé par la même décision, a lui aussi déjà migré vers un nouveau TLD et reste accessible. Le reste de la fournée complète les 113 comme Lookmovie et ses treize variantes, KissKH, animepahe, anime-sama, WatchSeries, voir-anime, Streamex. La liste noire belge dépasse maintenant les 1000 domaines depuis le lancement du dispositif en 2025, et elle peut être mise à jour chaque semaine avec 50 nouveaux noms.
50 par semaine, c'est impressionnant ! Face à des gars qui basculent leur trafic sur un nouveau TLD en quelques minutes, montre en main, la justice est dépassée ! Et pas parce qu'elle est nulle hein, mais parce que le blocage DNS n'a jamais empêché personne de taper une autre adresse qui renvoie vers le même service... On avait déjà vu le même théâtre quand la Belgique a censuré Internet Archive , et quand le Conseil d'État a éteint la riposte graduée d'Hadopi après 17 ans .
Prochaine étape probable, les ayants droit s'attaqueront surement aux canaux Telegram. En attendant, quelqu'un devrait leur dire que cette .pizza était déjà bien froide ^^.
Source : TorrentFreak

Vous vous souvenez de Jason Lemkin ?
C'est le malheureux qui, en juillet de l'année dernière, s'est fait vider sa base de prod par l'IA de Replit. Je pense que cette histoire a traumatisé pas mal de développeurs. Eh bien les amis, rebelote avec GPT 5.6 Sol, qui le temps que vous finissiez votre café, avait déjà mangé le Mac de Matt Shumer , la base Neon de Bruno Lemos , les fichiers de Joey Kudish , et la crédibilité du mot "honnête".
Sorti le 9 juillet, Sol c'est le plus costaud de la nouvelle famille d'OpenAI, et on pourrait se dire qu'il est un peu plus intelligent qu'avant et embarque quand même des sécurités pour éviter ce genre de problème. Mais non.
C'est Shumer, qui est quand même investisseur dans l'IA, qui a ouvert le bal : "GPT-5.6-Sol vient de supprimer par accident PRESQUE TOUS les fichiers de mon Mac." Lemos, lui, a eu droit au grand jeu (le veinard) puisque le modèle lui a tout bien fait jusqu'au moment où il a décidé de faire un TRUNCATE TABLE sur sa base utilisateurs EN PROD !!
Le plus drôle, si je puis dire, c'est que quelques heures avant de tout perdre, Lemos était en train de défendre GPT 5.6 sur le Slack de sa société en expliquant que Shumer n'avait qu'à pas le lancer en mode full access. Oups... Les collègues ont dû bien se foutre de sa gueule.
Du coup OpenAI a mis ses meilleurs Colombos sur l'enquête et sa réponse vaut le détour. Thibault Sottiaux, qui dirige l'ingénierie de Codex, explique le mécanisme : "Le modèle tente d'écraser la variable d'environnement $HOME pour définir un dossier temporaire. Il fait une erreur honnête et supprime $HOME par erreur à la place."
En français, ça veut dire que le modèle voulait se bricoler un petit dossier temporaire pour bosser et malheureusement il a écrasé le répertoire perso à la place. Donc pour OpenAI, c'est une erreur "honnête" alors qu'un rm -rf, ça ne serait pas acceptable.
Quand on lit la doc technique de GPT 5.6, OpenAI le dit lui-même : "Nos simulations de déploiement suggèrent que, comparé à GPT-5.5, GPT-5.6 Sol prend plus souvent des actions de sévérité 3." Le niveau 3, c'est un comportement qu'un utilisateur raisonnable n'anticiperait pas et auquel il s'opposerait fermement. Du genre supprimer des données sans validation, désactiver les systèmes de monitoring, contourner les contrôles de sécurité par obfuscation, ou balancer vos credentials sur un service non approuvé.
Voilà, c'était dans la doc, il suffisait de la lire. C'est donc connu que ce nouveau modèle dérape plus que l'ancien. C'est moche.
L'enquête interne montre quand même que les victimes tournaient en Full-Access, sans sandbox et sans Auto-review. Mais Sottiaux reconnaît quand même que ce n'est pas comme ça qu'OpenAI veut que son système se comporte, même quand l'utilisateur fait tourner un modèle en full access sans les protections de base de la sandbox ni auto-review.

Voilà donc pour éviter ça à l'avenir, ce qu'ils ont prévu, c'est de mettre à jour les avertissements pour les développeurs de guider les utilisateurs vers des modes de permission plus sûrs et évidemment d'ajouter des garde-fous supplémentaires.
En tout cas, si chez vous vous faites tourner codex, et bien sachez que par défaut, il tourne dans un bac à sable, ce qui limite ce qu'il peut toucher. Et le mode auto-review, sait parfaitement intercepter toutes les actions à haut risque et les refuser (auto-review, il faut l'activer à la main, pour info). Et le mode full access désactive le bac à sable et les auto-reviews, sachez-le.
Et c'est précisément ce mode que nos trois victimes avaient choisi...
