VASA-1 – Des visages parlants ultra-réalistes et en temps réel

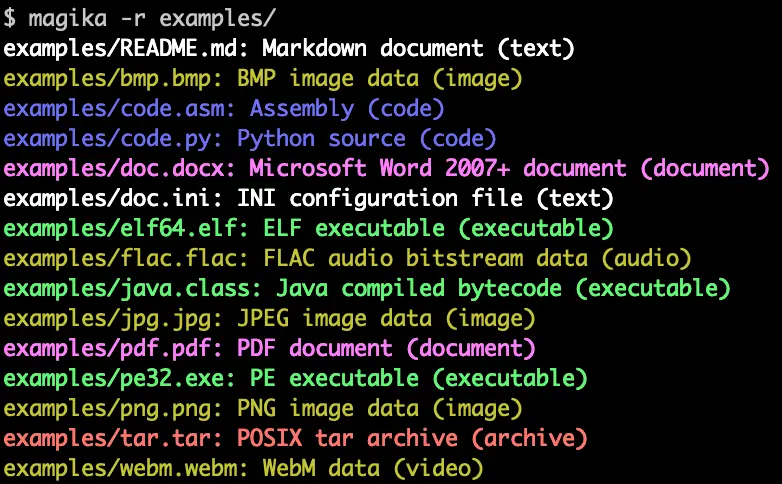
VASA-1 est un nouveau framework qui permet de générer des visages parlants ultra-réalistes en temps réel ! En gros, vous balancez une simple photo à cette IA, ainsi qu’un petit clip audio, et bim ! Elle vous pond une vidéo d’un visage qui parle, avec une synchronisation de la bouche nickel chrome, des expressions faciales hyper naturelles et des mouvements de tête très fluides. C’est hyper bluffant !
Les chercheurs de Microsoft ont réussi ce tour de force en combinant plusieurs techniques de pointe en deep learning. Ils ont d’abord créé un espace latent expressif et bien organisé pour représenter les visages humains. Ça permet de générer de nouveaux visages variés, qui restent cohérents avec les données existantes. Ensuite, ils ont entraîné un modèle de génération de dynamiques faciales et de mouvements de tête, appelé le Diffusion Transformer, pour générer les mouvements à partir de l’audio et d’autres signaux de contrôle.
Et le résultat est juste époustouflant. On a l’impression de voir de vraies personnes qui parlent, avec toutes les nuances et les subtilités des expressions faciales. Les lèvres bougent parfaitement en rythme avec les paroles, les yeux clignent et regardent naturellement, les sourcils se lèvent et se froncent…
En plus de ça, VASA-1 peut générer des vidéos en haute résolution (512×512) à une cadence élevée, jusqu’à 40 images par seconde, avec une latence de démarrage négligeable. Autant dire que c’est le graal pour toutes les applications qui nécessitent des avatars parlants réalistes. On peut imaginer des assistants virtuels avec lesquels on pourrait interagir de manière super naturelle, des personnages de jeux vidéo encore plus crédibles et attachants, des outils pédagogiques révolutionnaires pour apprendre les langues ou d’autres matières, des thérapies innovantes utilisant des avatars pour aider les patients… etc etc..
En plus de pouvoir contrôler la direction du regard, la distance de la tête et même les émotions du visage généré, VASA-1 est capable de gérer des entrées qui sortent complètement de son domaine d’entraînement comme des photos artistiques, du chant, d’autres langues…etc.
Bon, évidemment, il reste encore quelques limitations. Par exemple, le modèle ne gère que le haut du corps et ne prend pas en compte les éléments non rigides comme les cheveux ou les vêtements. De plus, même si les visages générés semblent très réalistes, ils ne peuvent pas encore imiter parfaitement l’apparence et les mouvements d’une vraie personne mais les chercheurs comptent bien continuer à l’améliorer pour qu’il soit encore plus versatile et expressif.
En attendant, je vous invite à checker leur page de démo pour voir cette merveille en action. C’est juste hallucinant ! Par contre, vu les problèmes éthiques que ça pourrait poser du style usurpation d’identité, fake news et compagnie, et connaissans Microsoft, je pense que VASA-1 ne sera pas testable par tous bientôt malheureusement. Mais je peux me tromper…