Ces derniers jours, des propriétaires de voitures électriques dans le Loiret ont été victimes de vols de données bancaires à cause de QR Codes compromis sur les bornes de recharge. Si cette campagne est pour l’instant limitée géographiquement, avec un montant dérobé de 80 Euros au total, des actions ont été prises par la mairie, […]
L'automatisation est aujourd'hui devenue incontournable dans les systèmes d'information. La mouvance DevOps n'y ai pas étrangère bien entendu, et bon nombre d'éditeurs se sont mis sur ce créneau, avec pour objectif d'améliorer nos flux de travail ou nos processus.
Donc, est-ce réservé aux seuls ingénieurs DevOps ou Cloud? Que nenni! L'automatisation peut aussi faciliter la vie de l'administrateur système/réseau en facilitant les tâches courantes ou en préparant les tâches de déploiement.
Rundeck répond parfaitement à cette problématique et du haut de ses 12 ans d’existence, le projet est bien mûr et prêt à vous rendre service. Existant en version communautaire et open source ou en version pro, il s'adapte à tous les besoins et n'est pas très gourmand, il trouvera donc forcément une place dans votre infra !
Ce logiciel est capable d'exécuter plusieurs tâches sur plusieurs serveurs, comme des commandes, des scripts, des copies de fichiers, etc... Le tout à la volée ou de manière programmée.
Dans ce tutoriel, nous allons déployer un serveur Rundeck et voir comment s'en servir pour administrer des serveurs Linux. Dans un prochain article, nous verrons comment gérer des serveurs Windows avec Rundeck.
Déjà un bon point : Rundeck s'installe de bien des façons. Tout le monde y trouvera son compte, car il peut tout autant se déployer via un conteneur Docker que s'installer sur Ubuntu, CentOS ou même Windows!
Je ne vais détailler ici que l'installation sous Debian. Les Linuxiens adapteront à leur distribution et les Windowsiens ne seront pas perdus par l'installation somme toute classique. Pour ceux qui le souhaitent, le déploiement est également possible depuis un JAR.
Au niveau des prérequis, il vous faudra à minima une machine avec 2 CPUs, 4 Go de RAM et 20 Go de disque.
Tout d'abord, sur notre Debian tout frais, comme d'habitude, on prépare l'installation :
apt-get update && apt-get upgrade -y
Si vous êtes sur Windows, il faut récupérer le package d'installation. Il est disponible ici : www.rundeck.com/downloads . Attention, il faudra fournir à minima un mail. Les paquets Deb et RPM sont également disponibles sur cette même page pour ceux qui préfèrent.
Je vais détailler l'installation via les dépôts, qui vous permettront des mises à jour facilitées.
Avant de faire l'installation à proprement parler, et Rundeck tournant sous Java, installez la version 11 d'OpenJDK :
apt-get install openjdk-11-jdk-headless -y
Si vous êtes sous Debian avec un user et un root, installez également le paquet sudo .
apt-get install sudo -y
Maintenant que tout est OK, passons à l'installation des dépôts de Rundeck, un script est fourni, pour ceux qui sont sous d'autres distributions, vous trouverez toute la doc ici :
Note : sur la documentation, faites attention à bien sélectionner l'onglet "Community" car par défaut les commandes et guides sont donnés pour la version pro
Une fois ceci fait, l'installation peut se faire comme n'importe quelle application :
apt-get install rundeck
L'installation n'est pas très longue. Une petite subtilité toutefois pour les utilisateurs de Debian (et sûrement Ubuntu), contrairement à ce qu'indique la doc, le premier démarrage doit impérativement se faire via Initd, sinon, vous aurez un message d'erreur :
/etc/init.d/rundeckd start
Une fois démarré, ajoutez-le aux services qui démarrent avec le système !
systemctl enable rundeckd
Voilà, votre serveur Rundeck est installé !
III. Configuration de Rundeck
À partir de là, votre serveur devrait répondre sur le port 4440 à son adresse IP.
En fonction de la méthode d'installation, il est possible que ce ne soit pas le cas.
Si vous êtes dans cette situation, pas de panique, il existe une solution. Pour les autres, si vous comptez accéder à votre serveur depuis une autre machine, il peut être également intéressant de faire les modifications.
Tout d'abord, le premier fichier à configurer est "framework.properties" qui se situe dans le répertoire "/etc/rundeck". L'élément qui nous intéresse est tout au début de ce fichier :
Changez "localhost" par le nom de votre serveur, au besoin, vous pouvez également changer le numéro de port. Enfin, et c'est le plus important, changez l'URL en inscrivant ici votre adresse IP (ou nom d'hôte si vous avez une résolution DNS ou Netbios au sein de votre réseau) à la place de localhost dans la ligne "framework.server.url".
Ensuite, le second fichier à modifier est celui nommé "rundeck-config.properties" qui se situe dans le même répertoire.
La ligne qui nous intéresse ici est celle nommée "grails.serverURL", modifiez encore une fois "localhost" par votre adresse IP ou nom d'hôte.
Enregistrez et redémarrez Rundeck, vous devriez accéder à la page web.
Le petit défaut de Rundeck est qu'il est long à démarrer. Donc si vous n'accédez pas immédiatement à la page après le redémarrage cela ne veut pas forcément dire qu'il ne fonctionne pas. Pour en avoir le cœur net, vous pouvez afficher le contenu de /var/log/rundeck/service.log. Tant que ce fichier n'affichera pas "Grail application running at http://.......", c'est que votre serveur n'est pas prêt!
Viens maintenant le temps de se connecter! Les logins par défaut sont admin/admin, bien entendu je vous conseille vivement de les changer si vous êtes en production...
IV. Création du premier projet
Rundeck fonctionne sous forme de projet. Chacun des projets peut avoir sa propre liste de nœuds, ses propres utilisateurs, se propres jobs, etc. L'avantage ici est donc de pouvoir scinder la gestion auprès de plusieurs équipes, ou pour des suivis ou projets clients différents par exemple.
Autre avantage, les projets sont archivables, et peuvent être importés sur un autre serveur. Cela facilite grandement les migrations ou les reprises après sinistre.
La première étape est donc de créer un projet, au sein duquel nous importerons nos serveurs. Cliquez sur le bouton "Create New Project" :
Note : si vous souhaitez accéder à la doc officielle, vous pouvez le faire d'ici depuis le bouton "Docs". Tout à droite, vous avez même accès à une sorte de tuto expliqué (en anglais) pour vous familiariser avec l'outil.
La création du projet va demander quelques informations. Tout d'abord bien entendu le nom et la description du projet, un label peut éventuellement être ajouté :
Vous l'aurez compris, je vais prendre pour exemple un déploiement de stack LAMP pour Linux.
Viens ensuite des options. Ces options sont définies au niveau projet. Cela veut dire qu'il est possible ensuite d'aller contre, disons que ce sont les options par défaut de votre projet.
L'onglet "Execution History Clean" permet de mettre en place une politique de rétention d’historique d'exécution. Par défaut, toutes les tâches exécutées sont inscrites dans l'historique pour 60 jours, avec un nombre de 50 maximum. La tâche par défaut s'exécute tous les jours à midi. Si ces valeurs ne vous conviennent pas, il suffit de cocher la case et de choisir les vôtres.
L'onglet "Executionmode" va vous permettre de choisir d'activer ou de désactiver l'exécution des tâches, et cela pour deux méthodes : programmées ou manuelles. Vous allez pouvoir entre autres ne permettre que l'exécution des tâches manuelles qu'à partir de 24 heures après la création du projet, ou au contraire la désactiver.
L'onglet "User interface" vous permet de paramétrer certains aspects de l'interface utilisateur comme afficher ou non le readme du projet, dérouler automatiquement les groupes de travaux, etc.
L'onglet "Default Node Executor" est relativement important. Le Node Executor est responsable de l'exécution des commandes et des scripts sur les nœuds distants. Vous devrez donc choisir quel "exécuteur" de commandes utiliser. Au choix, vous pourrez utiliser SSH, WinRM via python, SSHJ (pour Java) ou même Ansible ! Il est aussi possible d'utiliser son propre exécutable (Script Execution).
Pour ma part, je laisse SSH, car c'est ce qui me convient le mieux. Je n'ai pas encore testé à ce jour l'utilisation conjointe d'Ansible et Rundeck, pour les nœuds Windows, je préfère l'administration via SSH depuis que cela est rendu possible justement pour avoir les mêmes méthodes d'accès. Si vous êtes en full Linux ou hybride Linux/Windows, je vous conseille SSH, si vous êtes en full Windows, WinRM peut peut-être mieux convenir.
A noter que l'édition Entreprise de Rundeck permet l'utilisation de plus de méthodes, comme par exemple PowerShell.
Vous pourrez indiquer à Rundeck l'endroit où vous souhaitez que les fichiers de clés SSH ou de mot de passe soient stockés. Par défaut, ils le sont dans /var/lib/rundeck/project/nomduprojet/keys.
Idem pour le "Default File Copier", vous aurez le choix entre plusieurs "moteurs" pour envoyer des fichiers sur les hôtes distants. Par défaut, SCP est choisi, celui-ci étant basé sur SSH, les mêmes options que précédemment vous sont proposées.
Une fois vos choix faits, il ne reste qu'à cliquer sur "Create" !
V. Ajout de la première machine
D'office après la création de votre projet, Rundeck vous affiche la page "Edit Nodes" pour ajouter vos nœuds.
Cet ajout se fait par lecture d'un ficher en XML, JSON ou en YAML, disponible en local ou via une URL, ou encore sur un stockage S3 et même importées depuis Ansible. Cette source se déclare via le bouton "Add a new node source".
Je choisis un fichier local, je clique donc sur "File" et choisis le format YAML dans la liste déroulante (vous n'êtes pas obligé bien entendu).
Au niveau de la ligne "File Path", j'indique le chemin où je souhaite "ranger" mon fichier. Ce fichier doit pouvoir être lu et écrit par l'utilisateur rundeck, créé au moment de l'installation. À noter qu'aucun dossier home n'est créé pour ce dernier, je vais donc le créer, mais vous pouvez bien sûr le mettre où vous voulez.
Viennent ensuite les options, comme la possibilité de générer directement le fichier en question s'il n'existe pas (ce qui est mon cas) et la possibilité d'intégrer le serveur Rundeck lui-même à la liste des nœuds. Dans mon cas, cela n'as pas vraiment de sens; si je crée un autre projet pour gérer la conformité et la mise à jour de tous mes serveurs, j'aurais pu en avoir besoin par exemple. Je le laisse ici pour avoir un exemple d'entrée dans ce fichier, si vous débutez, je vous conseille de faire de même pour avoir une idée de la syntaxe et des champs attendus.
Je ne coche pas "Require File Exists" vu que je vais le générer, mais je coche la case "Writable" pour pouvoir ajouter les nœuds depuis Rundeck directement. Si cette cas n'est pas cochée, l'ajout des nœuds devra se faire via SSH ou en console directement sur le fichier, si vous préférez séparer les permissions.
Une fois les infos remplies, je sauvegarde sur cet écran ET sur l'écran suivant pour que les changements soient pris en compte. Vous remarquerez que, par défaut, une source locale est présente, elle représente le serveur Rundeck lui-même. Comme annoncé plus tôt, cette source ne m'est pas nécessaire pour ce projet, je la supprime donc.
Nous nous retrouvons avec notre fichier YAML (ou le format choisi) somme seule source. Sur ce même écran, il est possible de cliquer sur l'onglet "Edit" pour ajouter directement mes nœuds (seulement si vous avez rendu le fichier inscriptible!). Une fois dans l'onglet, un clic sur "Modify" vous permettra de découvrir le fichier tel qu'il existe au départ :
Si comme moi vous avez choisi le YAML, rappelez-vous bien que ce langage est très strict sur l'indentation! Si on décortique :
nodename : nom du nœud tel que vous souhaitez qu'il apparaisse dans Rundeck
hostname : nom de l'hôte ou IP
osVersion : Version du système
osFamily : type de système
osArch : architecture
description : comme son nom l'indique
osName : nom de l'OS
username : nom de l'utilisateur sous lequel seront effectuées les actions, très important
tags : suite de mots clés qui vous permettront de classifier vos nœuds afin de les retrouver plus facilement lors d'une recherche
Basé sur ce modèle, je vais donc insérer mon nouveau nœud, qui est un serveur Debian :
srv-dev: nodename: srv-dev hostname: 192.168.1.44 osVersion: 5.10.0-27-amd64 osFamily: unix osArch: amd64 description: Serveur de developpement osName: Debian username: rundeck tags: dev linux
J'enregistre et voilà mon nœud ajouté. Mais comment fait Rundeck pour s'y connecter?
VI. Ajout de la clé SSH
Comme je me connecte en SSH, le plus simple et le plus secure est d'ajouter une clé pour l'utilisateur root que Rundeck pourra utiliser. Pour cela, il faut en premier lieu générer la clé, puis ajouter la clé publique sur mon Debian dans les clés autorisées. Pour faire tout cela, plusieurs choix : PuTTYGen à partir d'un hôte tiers ou OpenSSH/OpenSSL depuis l'hôte Rundeck (via le terminal).
Le résultat est le même. Personnellement, je passe par PUTTYGen et un hôte tiers, car je supprime les fichiers de clé après l'opération, de sorte que la clé pour Rundeck ne se balade pas partout. C'est juste un point de vue personnel, pas une consigne.
Donc, sur mon PC Windows, je lance PUTTYGen et je génère une paire de clés. Pour ceux qui ne l'ont jamais utilisé, il suffit de bouger la souris dans le cadre supérieur jusqu’à ce que la barre de progression soit complète.
Une fois la clé générée, son empreinte sera affichée en haut, c'est cette empreinte qu'il faudra copier :
Comme indiqué au-dessus de la clé, il faut ajouter cette ligne (car oui, c'est en une seule ligne, et faites attention à l'ascenseur à droite!) dans le fichier "authorized_keys" dans le dossier ".ssh" de l'utilisateur concerné sur le serveur cible, ici root sur mon srv-dev.
Donc, connexion en SSH sur ce serveur, puis on bascule en root et on vérifie le dossier de l'utilisateur :
Pas de dossier ssh ici, on va donc le créer, n'oubliez pas le point devant car il s'agit d'un dossier caché :
mkdir .ssh
Et, à l'intérieur de ce dossier, on va créer le fichier authorized_keys et coller le texte issu de PUTTYgen :
nano .ssh/authorized_keys
Je ne vous mets pas la ligne ici, car cela n'a pas d’intérêt et qu'elle est très longue. En revanche, elle se termine par rsa-key-20240123. Cette chaine à la fin est une remarque qui peut être modifiée, je vous conseille de mettre quelque chose qui vous rappelle que cette clé est utilisée pour Rundeck, cela facilitera les choses lors du changement, surtout si vous utilisez vous-même une clé pour vous connecter.
Note : je part du principe que vous utilisez une clé par usage, c'est à dire une clé pour vos connexions en tant qu'admin et une différente pour Rundeck (et éventuellement une autre pour votre collègue). Il est fortement déconseillé d'utiliser la même clé!
Enregistrez le fichier et fermez. Il faut maintenant donner la clé privée à Rundeck. Pour cela, sur l'interface d'administration, cliquez tout en bas à gauche sur "Project Settings" puis sur "Key Storage".
Cliquez sur "Add or Upload a Key" pour ajouter votre clé, ce qui vous amène à l'écran suivant :
Il est possible ici de copier/coller le texte de la clé privée ou uploader le fichier directement. Je vais choisir la deuxième solution. De retour sur PUTTYgen, cliquez sur "Conversions" puis sur "Export OpenSSH key". PUTTYgen va vous avertir et vous demander de confirmer la création de la clé sans passphrase. Si vous souhaitez en ajouter une, sachez que sshpass sera nécessaire sur le serveur Rundeck. Enregistrez votre clé privée et, sur l'écran ci-dessus, déroulez la liste sur "Upload File" et allez chercher votre clé privée.
Faites très attention au chemin en bleu sur cette fenêtre et copiez-le. En effet, c'est ce chemin qu'il faudra déclarer dans le fichier des nœuds pour que Rundeck sache quelle clé utiliser. Pour moi, c'est ce chemin :
keys/project/Infra1/key_dev
Enregistrez, votre clé a été ajoutée. Retournez dans "Project Settings" puis cliquez sur "Edit Nodes". Vous retrouvez le fichier YAML crée précédemment, cliquez sur "Modify" pour ajouter l'entrée suivante à la fin du bloc concernant votre nœud (attention à l'indentation !):
ssh-key-storage-path: keys/project/Infra1/key_dev
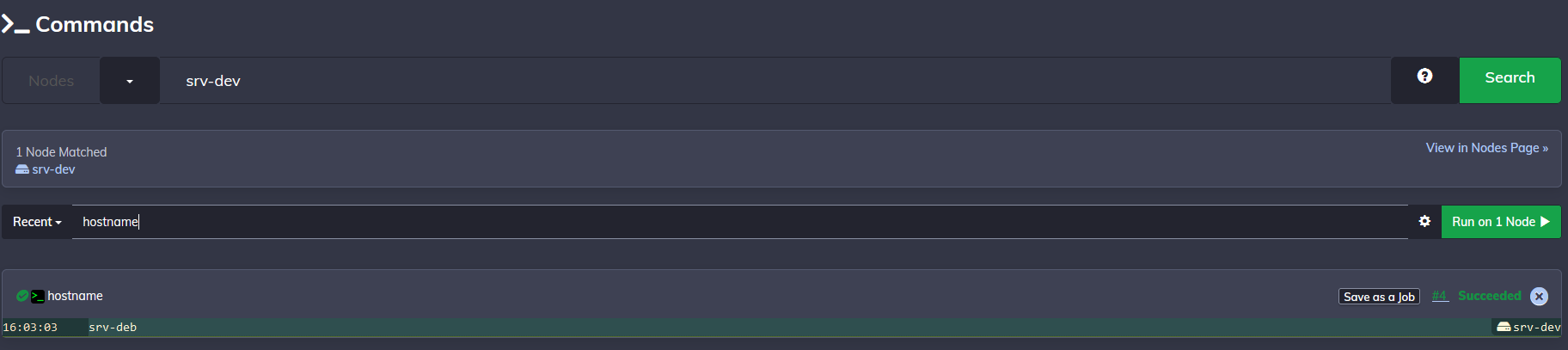
Sauvegardez le fichier. Pour tester le bon fonctionnement, nous allons utiliser la fonction commande, qui permet d'exécuter une commande sur un ou plusieurs nœuds du projet. Pour cela, cliquez sur "Commands" dans le menu de gauche, ce qui vous amènera à cette fenêtre :
La première chose à renseigner, c'est le nœud (ou le groupe de nœuds). Ici, soit vous rentrez directement le nom du nœud en question, soit vous entrez "tag:" suivi du tag pour sélectionner les nœuds, soit vous utilisez une regex pour choisir plusieurs nœuds selon leur nom (par exemple name: srv.* sélectionnera tous les nœuds dont le nom commence par srv). Plus d'information sur les filtres sur la documentation officielle.
Ici, je n'ai qu'un seul nœud, donc je vais taper directement son nom, puis à la ligne de commande, je vais simplement faire un hostname :
L'hôte m'a bien répondu, il est temps de passer à la suite.
VII. Création du job
Dans un projet Rundeck, il est question de Job pour les actions faites sur les nœuds, nous pourrions appeler cela des playbooks. Ces jobs vont inclure une suite d'actions qui seront effectuées de manière séquentielle sur un ou plusieurs nœuds, en fonction de ce que vous choisissez.
Pour créer un job, cliquez sur "Jobs" dans le menu de gauche, puis sur "Create a New Job", ce qui vous amènera à la fenêtre suivante, sur l'onglet "Details" :
Ici vous l'aurez compris, il s'agit de donner un nom au job et une description, ces deux éléments s'afficheront sur la page des jobs. Remplissez les champs et rendez-vous dans l'onglet "Workflow".
C'est ici que tout se joue. Je ne pourrais pas en un article vous montrer toute l'étendue de l'outil tellement il existe de possibilités différentes! La partie "Options" par exemple vous permettra de définir des options qui pourront être réutilisées dans les différentes étapes de votre job, comme par exemple la date du jour, ou un mot de passe afin qu'il ne soit pas stocké en dur, mais passé à chaque exécution, etc. Vous trouverez l'ensemble de ces possibilités sur la documentation. Pour notre exemple, je ne vais pas en utiliser.
Chaque action d'un job est nommé "Step" (étape), et comme vous pouvez le constater, les différentes possibilités permettent déjà de faire pas mal de choses :
Command permet de passer une commande, comme nous l'avons fait tout à l'heure avec hostname
Script vous permet d'écrire directement dans Rundeck un script qui sera exécuté sur la machine distante
Script file or URL vous permet d'utiliser un fichier de script préalablement écris ou récupérer un script depuis une page web (sur un gist par exemple)
Job reference vous permet d'inclure un job dans un job (l'inception de l'administration de système quoi...)
Mais là où ça devient très intéressant, c'est les plugins, de base, la version communautaire de Rundeck est fournie avec 5 plugins :
Ansible Playbook Inline vous permettra d'écrire un playbook directement dans Rundeck depuis la page web
Andible Playbook vous permettra d'utiliser un playbook préexistant
Copy file vous donnera la possibilité de copier des fichiers depuis le serveur Rundeck vers le serveur cible. Pratique si vous installez également un Git pour la mise à jour de scripts par exemple.
Local command va exécuter une commande sur le serveur Rundeck
Data Node Step permet quant à lui de déclarer des données à la volée pour ce job (je ne l'ai jamais utilisé cela dit donc pas certain de ce qu'il fait réellement)
Pas mal, non? Mais ce qui est top, c'est que vous pouvez ajouter des plugins! Vous en trouverez pour Git, Docker, Azure, etc. Bref, tout (ou presque) est possible. À noter que les plugins officiels ne sont disponibles que sur la version Entreprise. Pour le reste, vous pouvez commencer sur leur GitHub.
Nous allons rester simples, pour rappel, il s'agit de déployer la stack LAMP sur les serveurs cibles. Donc si on décompose, je dois :
Faire un mise à jour des dépôts et des paquets
Installer Apache, PHP (et les autres paquets utiles) et MariaDB
Vérifier que les services sont bien démarrés et les activer au démarrage
Dans mon Workflow, je vais donc découper tout cela en steps pour bien vérifier chaque étape. Je vais donc ajouter un Step pour la mise à jour, pour cela, pas besoin de script, je choisis une commande :
J'enregistre et ensuite, j'installe ce dont j'ai besoin, là encore, pas besoin de script, une commande suffit. Je l'ajoute en cliquant sur "Add A Step" :
Note : n'oubliez pas le "-y" à la fin! Vous ne pourrez pas interagir avec le job une fois celui-ci lancé...
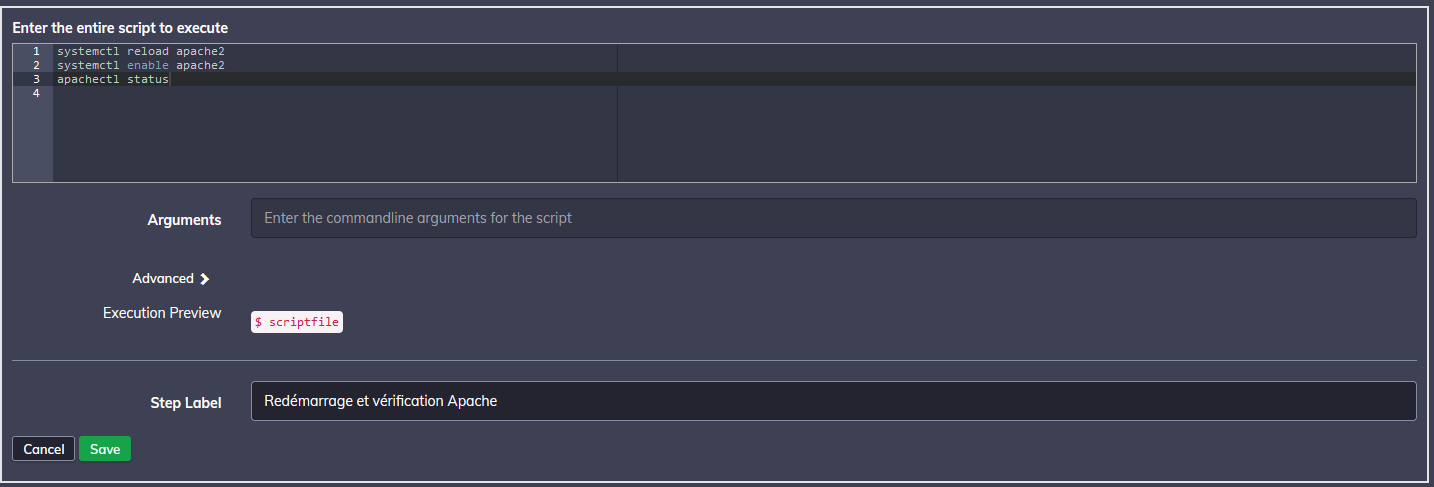
Ensuite, il me faut recharger Apache car il va démarrer tout seul suite à l'installation, et je souhaite qu'il prenne en compte PHP, puis je l'ajoute au démarrage. Ici, je préfère utiliser un script :
Vous constaterez que je n'ai pas mis de shebang ! C'est normal, car c'est du bash et c'est mon terminal par défaut. Si jamais j'utilise un autre langage, il faudra impérativement que je l'indique. Vous remarquerez aussi que vous pouvez créer des arguments pour votre script.
Maintenant, lors d'une installation normale, j'exécuterais "mysql_secure_installation", mais là pas possible. Je vais devoir le faire manuellement (enfin, via un script bien sûr) et donner un mot de passe à root. Sauf que je ne veux pas que celui-ci soit clairement indiqué dans mon étape ! C'est ici que les options peuvent nous sauver, nous allons donc créer une option, qui sera le mot de passe de MariaDB qu'il faudra renseigné lors du déploiement. Celui-ci sera rappelé dans mon script à l'aide d'une variable.
Cliquez sur "Add an Option" en haut de la fenêtre (avant les étapes) et remplissez le formulaire. Je ne fais pas de capture d'écran ici car ce serait trop grand mais je vais détailler les différents champs :
Option type : j'ai le choix entre Text et File, ici je choisis Text
Option name : le nom que je donne à mon option. C'est important car c'est avec ce nom que je vais l'appeler ensuite. Je choisis de l'appler db-pass
Option label : si vous voulez donner une étiquette à l'option, je n'en mets pas
Eventuellement une description plus explicite, pas utile pour moi
Default Value pour insérer une valeur par défaut si rien n'est indiqué lors de l'exécution. Dans mon cas, ce serai contre productif!
Input Type vous permet de choisir quel type d'entrée. Je vais choisir Secure car il s'agit ici d'un mot de passe. Celui-ci ne sera donc pas enregistré par Rundeck
Sort Value me permet de trier, utile pour une liste mais pas dans mon cas
Required : si Yes est coché, le job ne pourra pas être exécuté sans avoir rempli l'option, c'est ce que je veux donc oui.
Le champ suivant vous permet de masquer l'option sur la page du job, moi je n'en ai pas besoin.
Une fois tout rempli, Rundeck me dis comment l'utiliser :
Comme je vais l'utiliser dans un script, je vais appeler mon mot de passe avec "@option.db-pass@" et Rundeck passera au script la valeur renseignée au moment où je lance le job. Sauvegardez l'option, et ajoutez une étape au job sous forme de script.
Voici ce que je vais renseigner :
mysql --user=root <<_EOF_
SET PASSWORD FOR 'root'@localhost = PASSWORD('@option.db-pass@');
DELETE FROM mysql.user WHERE User='';
DELETE FROM mysql.user WHERE User='root' AND Host NOT IN ('localhost', '127.0.0.1', '::1');
DROP DATABASE IF EXISTS test;
DELETE FROM mysql.db WHERE Db='test' OR Db='test\_%';
FLUSH PRIVILEGES;
_EOF_
Toutes les étapes du script "mysql_secure_installation" sont reprises ici, notez l'appel de mon option à la deuxième ligne.
Je rajoute une étape pour m'assurer que le service MariaDB démarre bien avec le système :
Je termine en ajoutant un script, qui va vérifier que tout est OK en allant charger une page en PHP via Curl. Si tout est bon il va me dire "TEST OK" sinon, il me dira "TEST NOK" :
echo "" > /var/www/html/test.php
test=$(curl http://127.0.0.1/test.php | grep "PHP Version")
if [$test != "" ]; then echo "TEST OK"; else echo "TEST NOK"; fi
Nous voilà donc avec nos 6 étapes dans le job. Dernière étape obligatoire, dire où ce job s'exécute dans l'onglet "Nodes".
Rien de sorcier ici, soit on l'exécute localement, soit sur des nœuds. Cependant, lorsque vous allez cliquer sur "Dispatch to Nodes", plusieurs options vont s'afficher :
Node filter : permet de définir un filtre pour appliquer ce job à un ou plusieurs nœuds, dans mon exemple, ils seront appliqués aux serveurs Debian donc je mets osName: Debian et je clique sur "Search". Ce paramètre peut s'écraser pour ne le faire que sur un nœud au moment de l'exécution.
Exclude filter : si vous voulez exclure certains noeuds qui apparaissent quand même avec votre précédent filtre
Show Excluded Nodes : si vous souhaitez que les noeuds exclus s'affichent sur la page du job
Matched Nodes : les nœuds qui répondent au filtre mis au début. Normalement ici vous retrouvez votre serveur.
Editable filter : si vous voulez toujours exécuter sur le ou les nœuds déclarés par le biais de votre filtre, vous pouvez laisse sur No. En revanche, si votre job est amené à être exécuté sur tantôt un nœud, tantôt plusieurs nœuds, je vous conseille de mettre Yes.
Thread Count : si plusieurs nœuds, le nombre de tâches parallèles
Rank Attribute : si plusieurs nœuds, l'ordre dans lequel sera exécuté le job. Par défaut, c'est le nom des nœuds par ordre alphabétique.
Rank Order : l'ordre du classement (A-Z ou Z-A par exemple)
If a node fails : décris comment doit se comporter le job si un nœud échoue. Soit le job se termine immédiatement même s'il reste des nœuds à traiter, soit il continue sur les autres nœuds. Je choisis de continuer.
If node set empty : que faire si la liste définie de noeuds est vide
Node selection : si les cibles doivent être définies manuellement ou si la sélection se fait par défaut
Orchestrator : permets d'ajouter plusieurs options sur la manière dont le job sera traité
Une fois les options souhaités remplies, il ne reste qu'a définir si le job peut être programmé, car oui, il est possible de programmer les jobs directement pour qu'il s'exécutent à une date et une heure donnée, et s'il peut être exécuté. Cette dernière option est pratique si vous êtes plusieurs et que votre job n'est pas complet. Car vous pourrez le sauvegarder sans craindre qu'un de vos collègue l'exécute.
A ce stade, vous pouvez cliquer sur "Create" pour créer votre job. L'onglet "Notification" permet d'être alerté par mail en cas d'échec par exemple et l'onglet "Other" contiens d'autres options, comme le niveau de log. Vous pouvez laisser les valeurs par défaut, mais je vous invite à regarder ce qu'il est possible de faire.
Voilà donc mon job prêt à être lancé. Il ne reste qu'à le tester! Lorsque vous terminez sa création, vous pouvez directement le lancer à partir de l'écran sur lequel vous êtes :
Ici, je dois indiquer le mot de passe de root pour MariaDB (mon option) et je peux, si je veux changer, le ou les nœuds de destination. Je vais entrer un mot de passe et lancer le job pour vérifier que tout va bien.
Lorsque celui-ci est lancé, vous pouvez le suivre en déroulant les différentes étapes. Vous pourrez même avoir le retour du terminal du serveur distant, pratique pour débugger !
Par exemple, j'ai une erreur :
En déroulant cette étape, voici ce que cela me renvoie :
/tmp/4-7-srv-dev-dispatch-script.tmp.sh: ligne 2: curl : commande introuvable
/tmp/4-7-srv-dev-dispatch-script.tmp.sh: ligne 4: erreur de syntaxe : fin de fichier prématurée
Failed: NonZeroResultCode: Remote command failed with exit status 2
Ben oui, j'aurais pu vérifier que cURL était bien installé avant de lancer le job! Heureusement, j'avais pris un snapshot pour la démo... (comme quoi ça vous prouve que cet article est sans filet !)
Donc, je clique sur le menu à côté du nom de mon job et sur "Edit this Job" :
Me revoilà dans l'interface d'édition du job, je me rends dans l'onglet "Workflow" et édite l'étape numéro 2 en ajoutant cURL :
Je sauvegarde et relance le job (an ayant au préalable restauré mon snapshot bien sûr...).
Ça va beaucoup mieux ! Mon serveur LAMP est déployé ! Il me suffit maintenant d'ajouter plusieurs nœuds et je pourrais le faire à la volée sur plusieurs serveurs !
VIII. Conclusion
Ce premier tutoriel sur l'installation et l'utilisation de Rundeck touche à sa fin ! N'hésitez pas à nous faire vos retours en commentaire ! Le prochain article sur Rundeck portera sur la gestion des serveurs Windows Server !
You can manage Docker images and containers directly within Visual Studio Code (VS Code) with Microsoft's Docker extension. This article walks you through adding Docker files to a Workspace, creating a containerized application environment, and explains how to build and run Docker containers directly from the VS Code interface.
Y’a pas si longtemps, je vous ai présenté la police de caractères Luciole qui permet de donner beaucoup de lisibilités aux personnes mal voyantes.
Et bien dans le même esprit, je vous fais découvrir aujourd’hui Hack. Cette police de caractère libre au nom dénué d’originalité a été conçue pour soulager les petits neuneuils des développeurs qui aiment coder jusqu’au bout de la nuit. Hack intègre des versions gras, italique, regular…etc. avec un support de toutes les langues et tous les glyphes possibles y compris le cyrillique, le grec…etc.
Son design améliore la lisibilité du code, avec du contraste, une bonne hauteur des lettres, un zéro rempli pour ne pas le confondre avec le 0 majuscule, un bon espacement…etc. Tout est dans la subtilité, ça se touche beaucoup la nouille typographique, mais vous devriez quand même l’essayer, car ça ne peut être que plus confortable que ce bon vieil Arial que vous collez partout.
Ça y est, la vague Rust déferle sur la Silicon Valley et même le géant Google n’y échappe pas ! Le langage de programmation qui monte, qui monte, s’installe peu à peu dans les couloirs de la firme de Mountain View et visiblement, il fait des ravages… mais dans le bon sens du terme !
Lors de la récente conférence Rust Nation UK, Lars Bergstrom, directeur de l’ingénierie chez Google, a lâché une petite bombe : les équipes de dev qui sont passées à Rust ont vu leur productivité doubler par rapport à celles qui utilisent encore C++ !
On savait déjà que Rust était prometteur, avec sa gestion de la mémoire ultra safe et son système de « ownership » qui évite les erreurs de segmentation. Mais de là à imaginer des gains de productivité pareils, personne n’osait en rêver !
Et pourtant, c’est bien réel puisque quand une équipe Google migre un projet C++ vers Rust, elle divise par deux le temps nécessaire pour le développer et le maintenir. C’est énorme ! Surtout quand on sait à quel point le développement en C++ peut être chronophage et complexe. Mais alors comment expliquer un tel boost de performance ?
D’après Lars Bergstrom, c’est très simple : Rust inspire confiance. Les développeurs se sentent plus sereins quand ils codent en Rust, car ils savent que le compilateur va les aider à éviter toute une classe de bugs vicieux liés à la gestion de la mémoire. Résultat, ils passent moins de temps à débugger et plus de temps à ajouter des fonctionnalités. Et ça, c’est bon pour le moral des troupes et pour la vélocité des projets !
Autre avantage de Rust : sa courbe d’apprentissage. Contrairement à ce qu’on pourrait penser, les développeurs Google ne mettent pas des mois à être opérationnels en Rust. En moyenne, il leur faut environ 2 mois pour se sentir à l’aise et 4 mois pour retrouver leur niveau de productivité C++.
C’est sûr, Rust n’est pas le langage le plus simple à prendre en main, avec ses concepts de ownership et de borrowing qui peuvent paraître abstraits au début. Mais une fois franchie cette étape, on découvre un langage puissant, expressif et fiable. Et puis, il faut bien l’avouer, il y a un petit côté « hype » à coder en Rust en ce moment. C’est un langage qui a le vent en poupe et tout le monde en parle !
La révolution de l’IA est en marche depuis un bon moment maintenant mais faire tourner les derniers modèles de langage comme llama.cpp sur votre bécane, demande de la puissance. C’est là qu’intervient Justine Tunney, hackeuse et ex-programmeuse de chez Google, qui vient de pondre de nouveaux kernels d’algèbre linéaire pour booster les perfs de llama.cpp.
Concrètement, elle a réécrit les routines qui font les multiplications de matrices, c’est à dire les opérations au cœur des réseaux de neurones et en utilisant les dernières instructions vectorielles AVX-512 et ARM dotprod, elle a réussi à multiplier par 5 la vitesse d’exécution sur les processeurs récents d’Intel, AMD et ARM.
Mais ce n’est pas tout, elle a aussi bossé sur l’optimisation mémoire. Fini le temps où les calculs étaient ralentis par les accès à la RAM. Grâce à une utilisation intelligente du cache L2 et du prefetching, elle arrive maintenant à diviser par 2 le temps de chargement des données.
Résultat, llama.cpp et les autres modèles compatibles tournent comme des horloges, même sur des configs modestes. Fini les CUDA cores hors de prix, un bon vieux processeur avec un peu de RAM suffit. De quoi démocratiser l’accès à l’IA sans se ruiner surtout que son code est dispo sur son GitHub. Il est écrit en C++ avec zéro dépendance externe et peut être compilé sur Linux, macOS, Windows, FreeBSD et même SerenityOS.
Mais Justine ne compte pas s’arrêter là. Elle planche déjà sur le support de nouveaux formats de données comme le FP16 et le BF16 pour réduire encore l’empreinte mémoire. À terme, elle espère faire tourner les IA les plus gourmandes sur un Raspberry Pi ! Chouette non ?
D’un côté on a donc les géants comme Nvidia qui misent tout sur leurs accélérateurs graphiques propriétaires et de l’autre les hackers et les libristes qui veulent garder le contrôle de leur machine avec du code ouvert et optimisé.
En attendant, je vous invite à tester ses kernels par vous-même et à voir la différence. C’est peut-être ça le véritable sens du progrès technologique : permettre au plus grand nombre d’accéder à des outils auparavant réservés à une élite.
Gérald Darmanin annonce au Parisien l'ouverture d'un site dédié aux Jeux olympiques de Paris, le 10 mai. Il permettra de générer des QR Codes pour accéder à la ville, dont l'accès sera restreint durant la compétition.
Le déplacement à Paris dans certains périmètres sera conditionné à la présentation d'un QR Code. Une plateforme dédiée pour s'inscrire est attendue en mai 2024, afin de pouvoir le récupérer. Des documents et des éléments d'identité devront être fournis. En attendant le détail, voilà ce que l'on sait de son fonctionnement.
Vous êtes un étudiant en informatique, tout frais, tout nouveau, et on vous balance des exercices de programmation à faire. Panique à bord !
Mais attendez, c’est quoi ce truc là-bas ?
Ah bah oui, c’est ChatGPT, votre nouveau meilleur pote ! Il est capable de résoudre vos exos en deux temps trois mouvements, grâce à des techniques de traitement du langage naturel (NLP) et d’analyse de langage de programmation, mais attention, c’est pas si simple.
Des chercheurs ont voulu creuser la question et voir comment ces générateurs de code IA influencent vraiment l’apprentissage des étudiants et pour cela, ils ont réalisé 2 études. Dans la première, ils ont pris 69 étudiants, des novices complets en Python et les ont séparés en deux groupes : Ceux qui utiliseront l’IA et ceux qui coderont à l’ancienne sans IA.
Durant 7 sessions, ils leur ont donné des exos à faire. Les Jedis boostés à l’IA avaient accès à un générateur de code basé sur Codex, un modèle d’apprentissage automatique qui utilise le NLP et l’analyse de langage de programmation pour générer du code à partir des entrées des utilisateurs. Les autres, eux, devaient se débrouiller.
Résultat des courses ?
Les dev augmenté à l’IA ont cartonné ! Ils ont fini 91% des tâches contre 79% pour les autres. En plus, leur code était beaucoup plus correct. Toutefois, sur les tâches où il fallait modifier du code existant, les deux groupes étaient au coude à coude. Ensuite, ils ont fait passer des tests de connaissance aux étudiants, sans l’IA. Et là, surprise ! Les deux groupes ont eu des scores similaires. Mais quand ils ont refait les tests une semaine plus tard, les étudiants du goupe boosté à l’IA ont mieux retenu ce qu’ils avaient appris.
Dans la deuxième étude, les chercheurs ont analysé comment les étudiants utilisaient vraiment le générateur de code. Et là, révélations ! Certains en abusaient grave, genre copier-coller direct la consigne sans réfléchir. Pas cool ! 😅 Mais d’autres étaient plus malins et s’en servaient pour décomposer le problème en sous-tâches ou vérifier leur propre code.
Alors, que faut-il en retenir ?
Et bien que l’IA peut être un super outil pour apprendre à coder, mais à condition savoir l’utiliser intelligemment. C’est pourquoi les concepteurs d’outils et les profs doivent encourager une utilisation responsable et auto-régulée de ces générateurs de code. Sinon, c’est le drame assuré !
Pour ma part, vous le savez, le développement, c’est pas mon truc. Mais depuis que l’IA a débarqué dans ma vie, « sky is the limit » et ça m’aide énormément. Et comme ces étudiants, si je pose mon cerveau que je passe en mode copié-collé IA, à la fin, je vais avoir du caca. Mais si je comprends ce que je veux faire, si je maitrise mon code plus comme un chef de projet bien technique et bien c’est redoutablement efficace. Et ce qui est encore plus cool, c’est que j’apprends plein de trucs. On dit souvent qu’il faut forger pour devenir forgeron. Et bien là c’est le cas, car je ne m’encombre plus des problématiques de syntaxe, et je construis brique par brique mes outils en comprenant tout ce que je fais. Donc l’IA pour développer, oui !! Mais en laissant le cerveau allumé.
En tout cas, une chose est sûre, c’est en train de révolutionner l’apprentissage du code. Ça promet pour le futur mais faudra veiller à ce que les étudiants apprennent vraiment à faire les choses et ne deviennent pas des zombies du copier-coller (on avait déjà le souci avec StackOverflow, cela dit…).